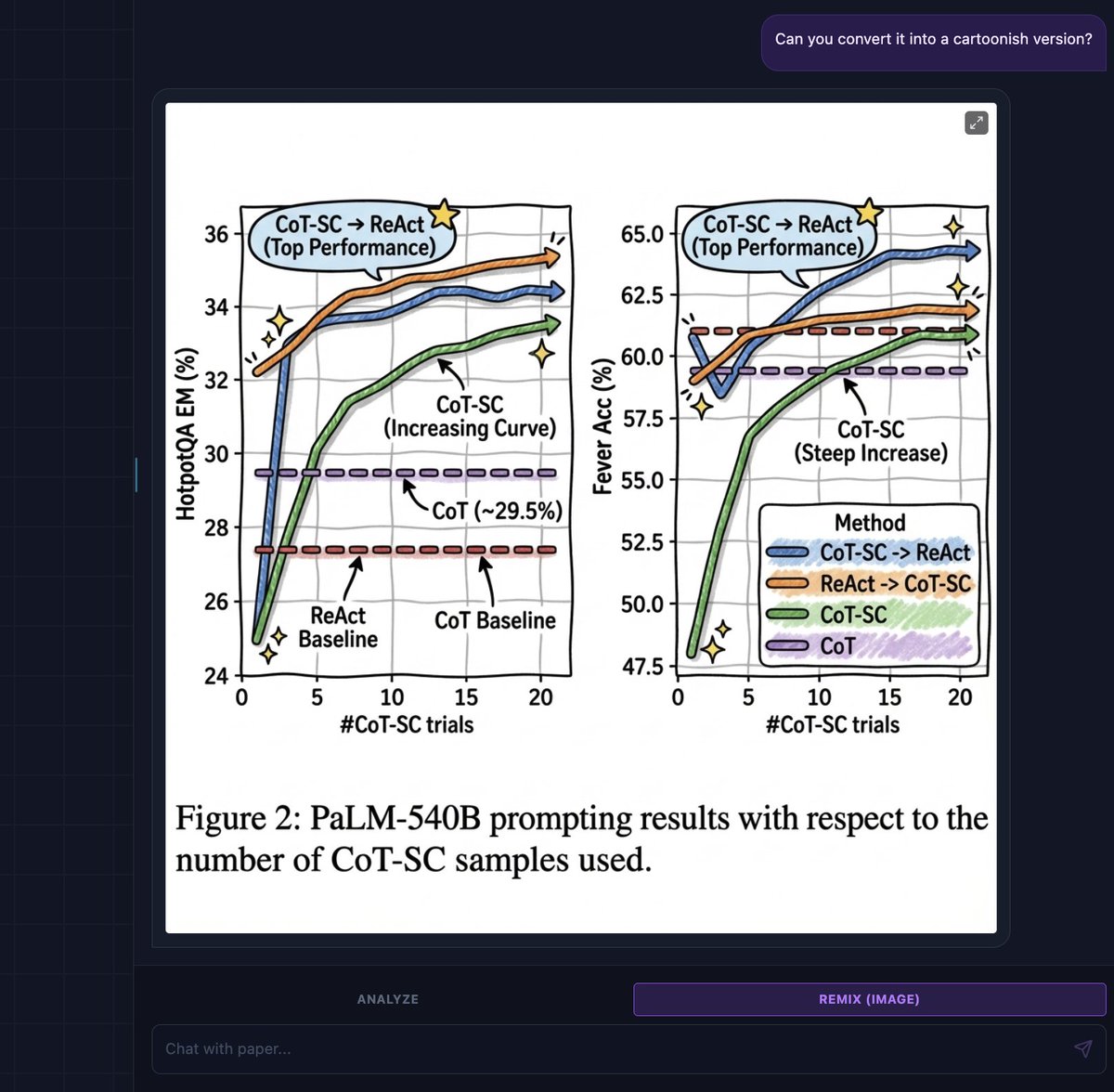
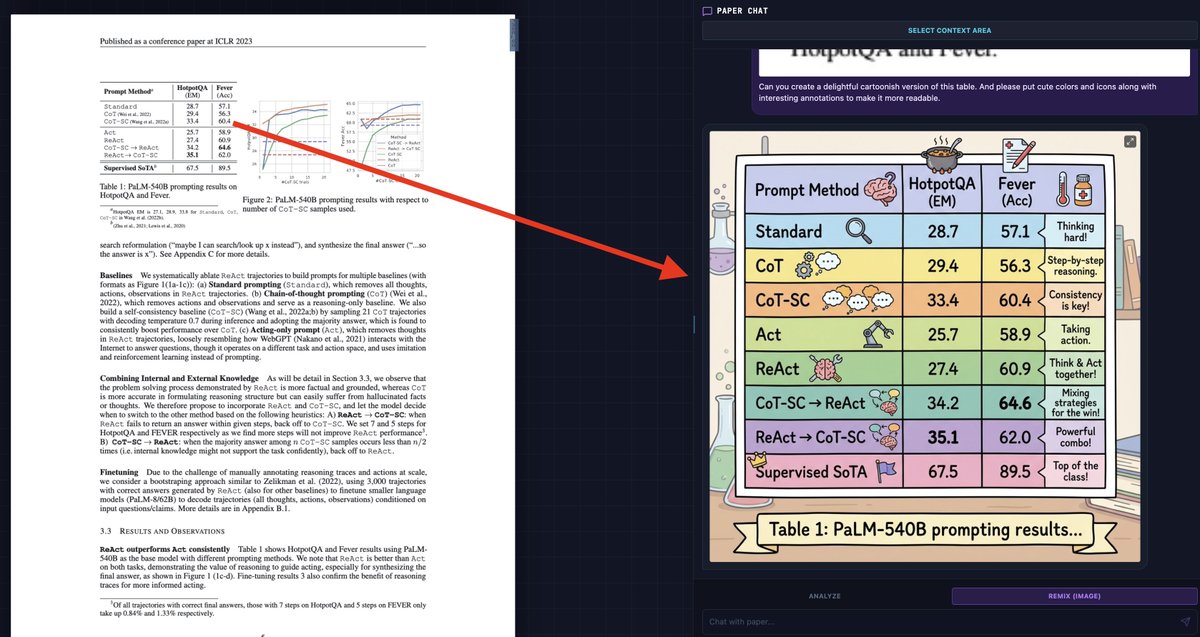
Another impressive paper by Meta.
It's a plug-in decoding strategy for RAG systems that slashes latency and memory use.
REFRAG achieves up to 30.85× TTFT acceleration.
Let's break down the technical details:
It's a plug-in decoding strategy for RAG systems that slashes latency and memory use.
REFRAG achieves up to 30.85× TTFT acceleration.
Let's break down the technical details:

TL;DR
REFRAG replaces most retrieved tokens with precomputed chunk embeddings at decode time, then selectively expands only the few chunks that matter.
This exploits block-diagonal attention in RAG prompts to cut latency and memory while preserving accuracy across RAG, multi-turn dialog, and long-doc summarization.
REFRAG replaces most retrieved tokens with precomputed chunk embeddings at decode time, then selectively expands only the few chunks that matter.
This exploits block-diagonal attention in RAG prompts to cut latency and memory while preserving accuracy across RAG, multi-turn dialog, and long-doc summarization.

Core idea
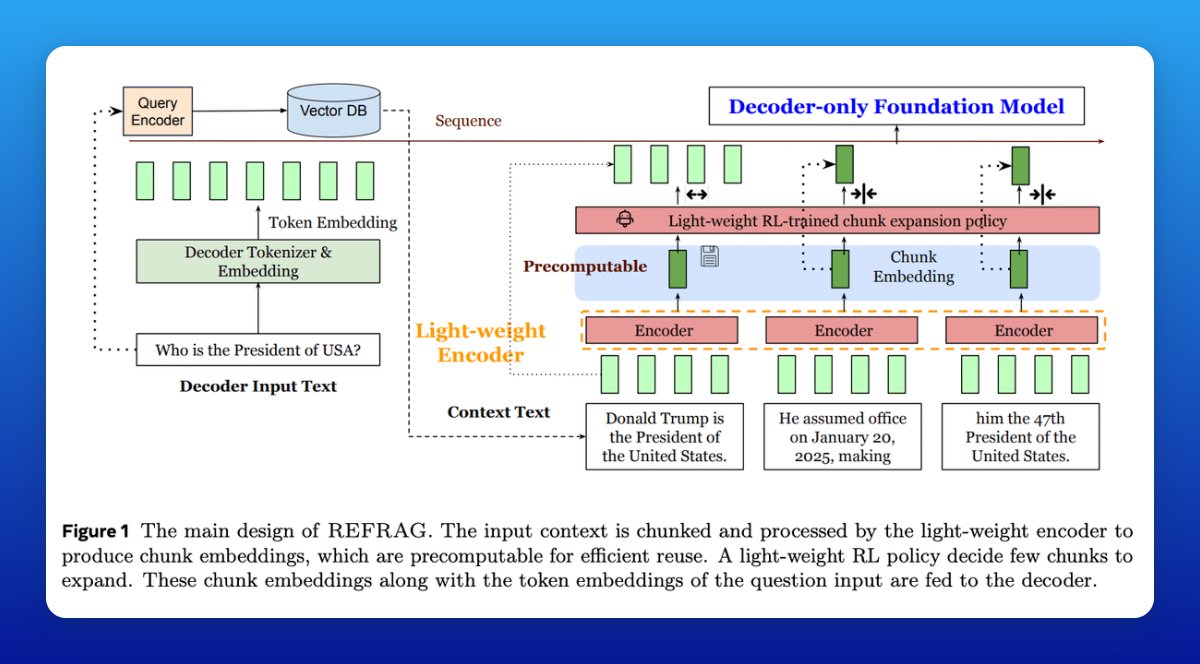
Chunk the retrieved context, encode each chunk with a lightweight encoder, project to the decoder’s embedding size, and feed embeddings directly alongside the user query.
A lightweight RL policy decides which chunks should stay compressed and which need to be expanded back into full text. Think of it as zooming in only where necessary.
Chunk the retrieved context, encode each chunk with a lightweight encoder, project to the decoder’s embedding size, and feed embeddings directly alongside the user query.
A lightweight RL policy decides which chunks should stay compressed and which need to be expanded back into full text. Think of it as zooming in only where necessary.
Why it works under the hood
Attention maps show that retrieved passages rarely interact with each other (block-diagonal pattern).
So REFRAG avoids wasting attention across irrelevant text, only paying full price for chunks that matter.
Attention maps show that retrieved passages rarely interact with each other (block-diagonal pattern).
So REFRAG avoids wasting attention across irrelevant text, only paying full price for chunks that matter.

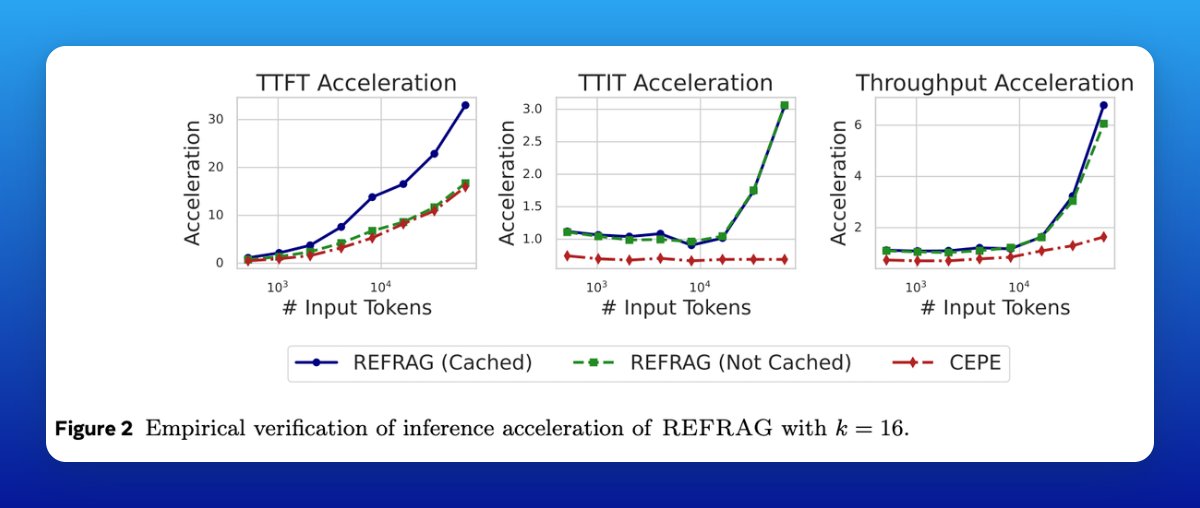
Speedups without dumbing down
Benchmarks show up to 30× faster time-to-first-token and 6–7× higher throughput versus vanilla LLaMA.
Even compared to strong baselines like CEPE, REFRAG is still 3–4× faster, with equal or better accuracy.
Benchmarks show up to 30× faster time-to-first-token and 6–7× higher throughput versus vanilla LLaMA.
Even compared to strong baselines like CEPE, REFRAG is still 3–4× faster, with equal or better accuracy.
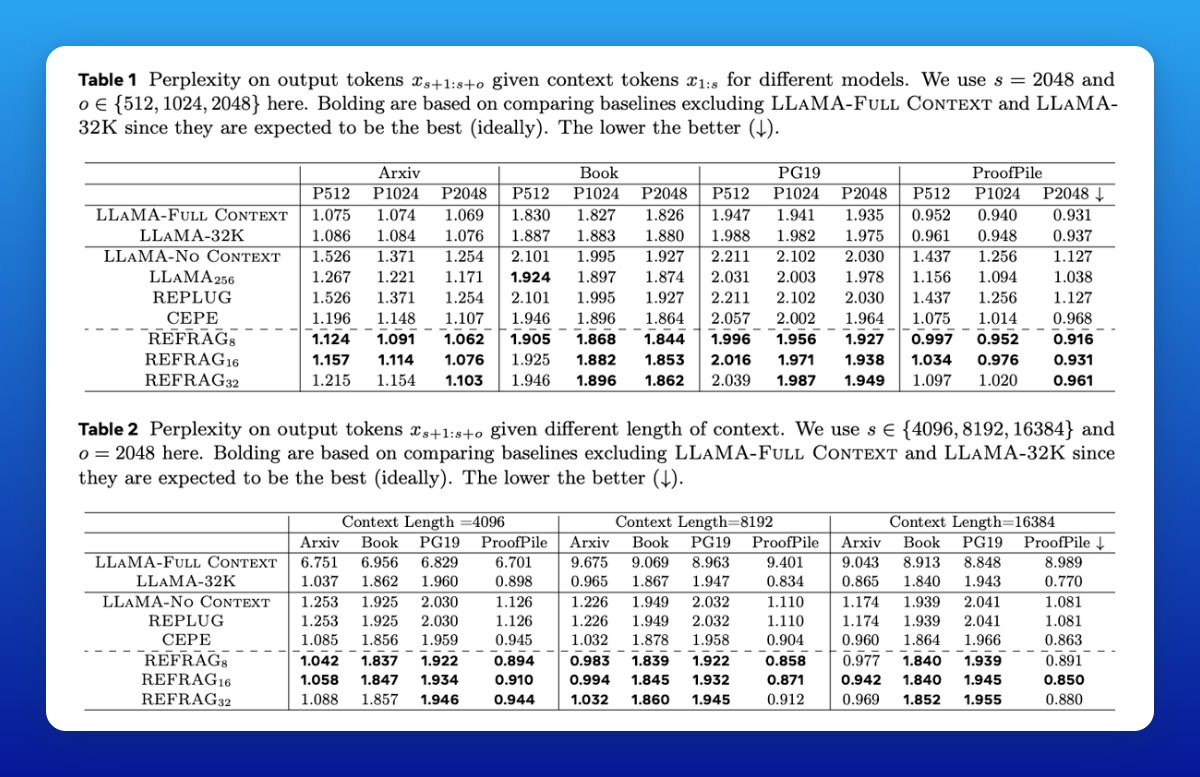
Longer memory for free
By compressing most chunks, REFRAG effectively extends model context length up to 16× more tokens, letting it juggle way more retrieved passages without breaking latency budgets.
By compressing most chunks, REFRAG effectively extends model context length up to 16× more tokens, letting it juggle way more retrieved passages without breaking latency budgets.
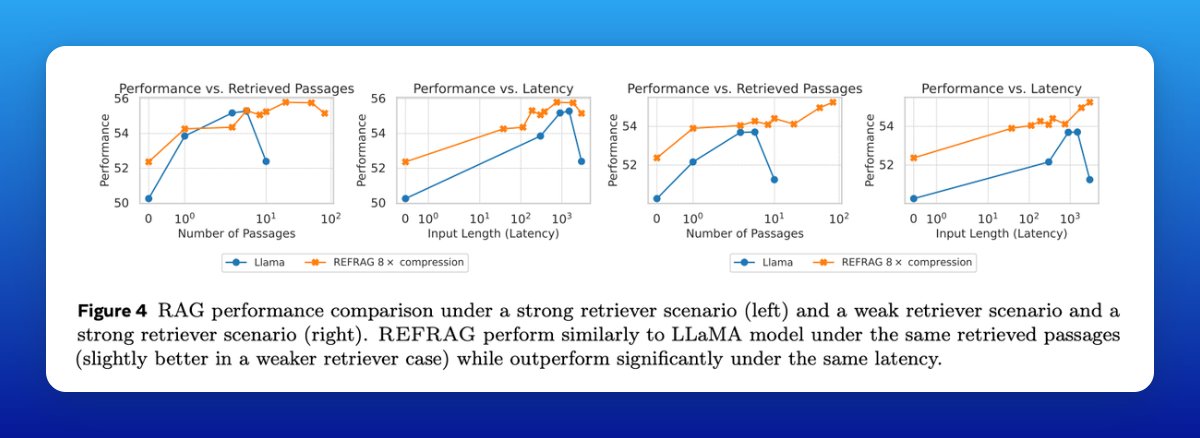
Better use of retrieval budget
With the same latency, REFRAG can process more passages than a baseline model and outperform it across 16 RAG tasks, especially when the retriever is weak (messy or noisy results).
Beyond RAG, it boosts multi-turn dialog (keeping more history without truncation) and long-doc summarization (higher ROUGE at fixed compute).
Paper: arxiv.org/abs/2509.01092
With the same latency, REFRAG can process more passages than a baseline model and outperform it across 16 RAG tasks, especially when the retriever is weak (messy or noisy results).
Beyond RAG, it boosts multi-turn dialog (keeping more history without truncation) and long-doc summarization (higher ROUGE at fixed compute).
Paper: arxiv.org/abs/2509.01092
• • •
Missing some Tweet in this thread? You can try to
force a refresh