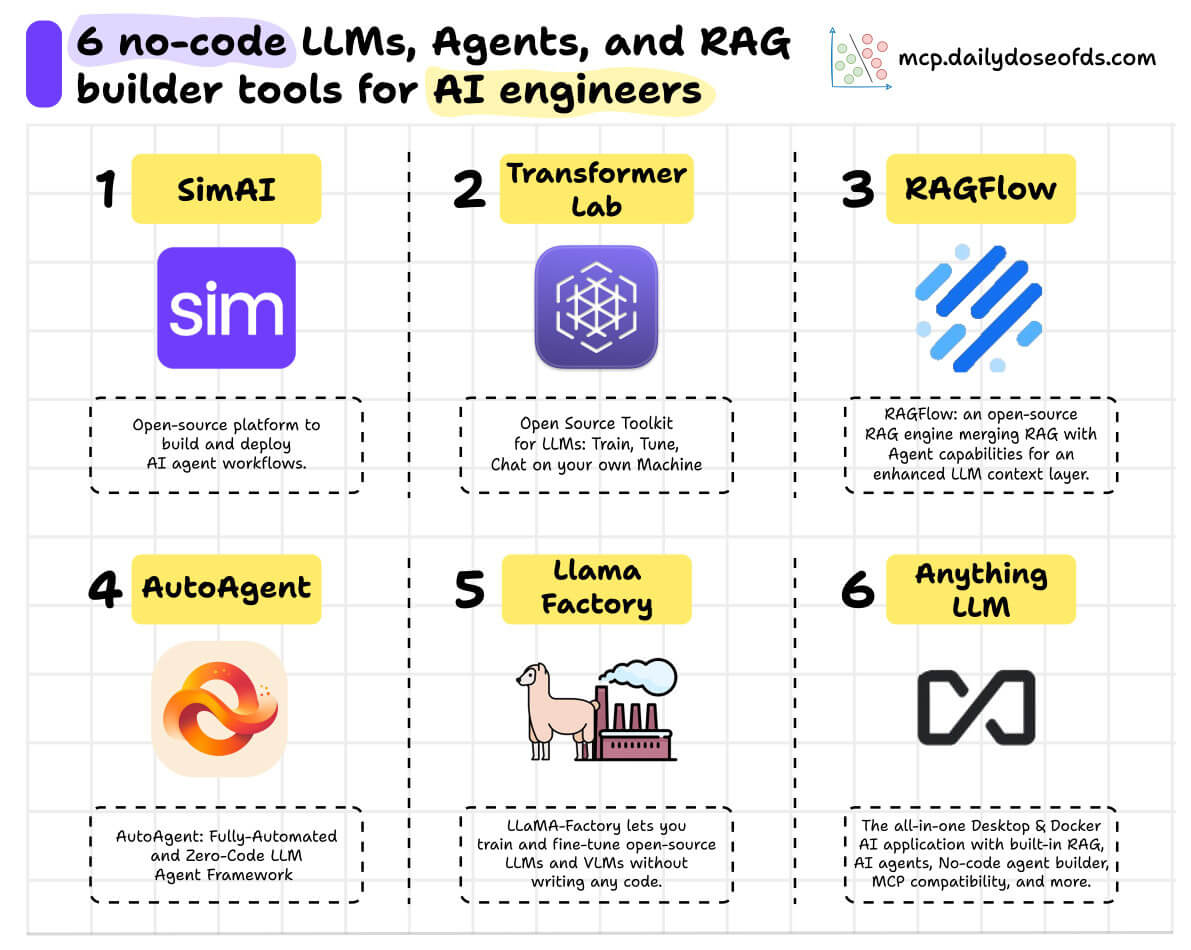
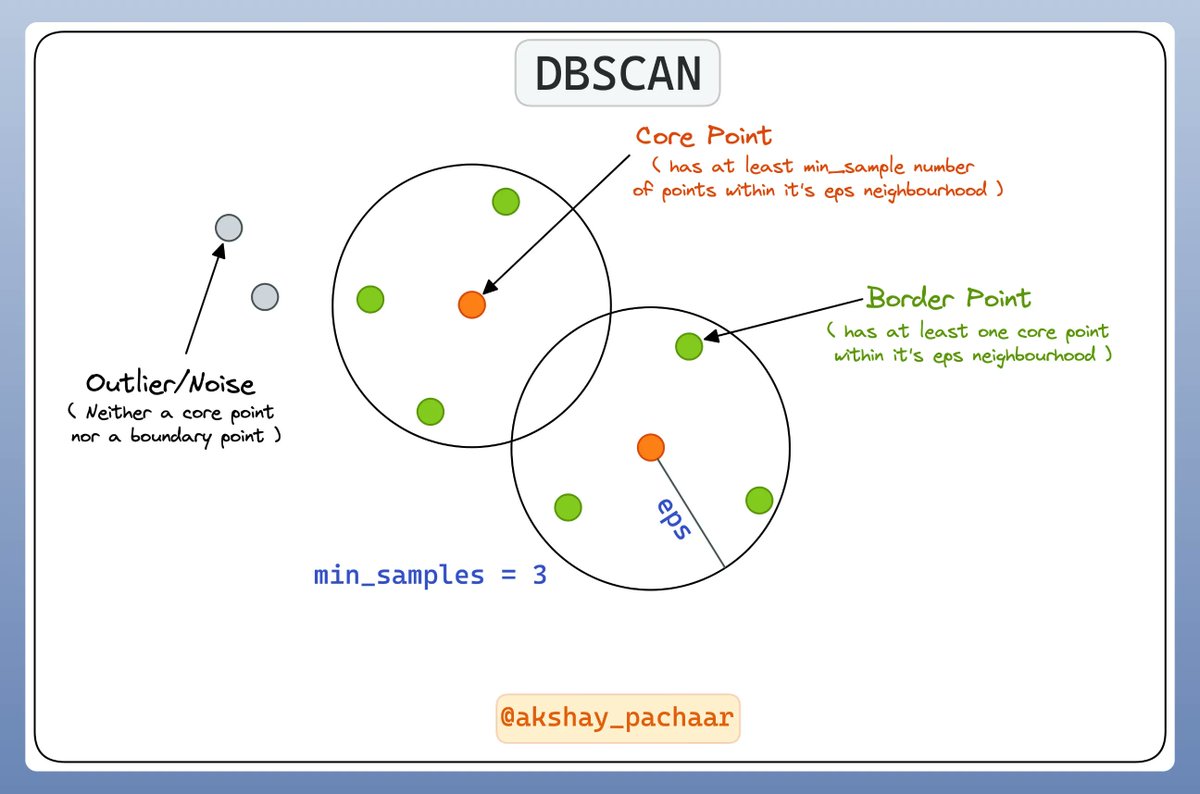
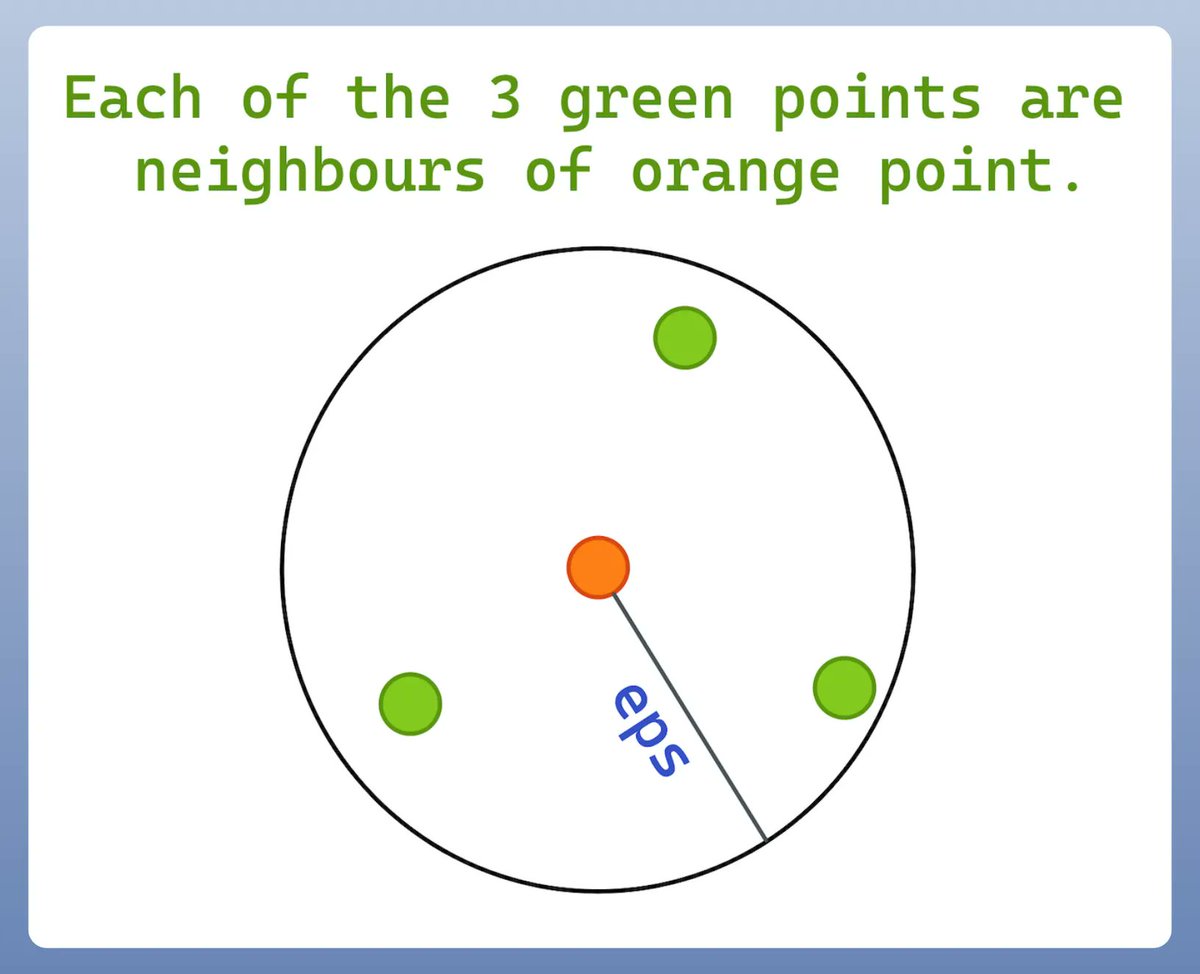
10 MCP, AI Agents & LLM visual explainers:
(don't forget to bookmark 🔖)
(don't forget to bookmark 🔖)
1️⃣ MCP
MCP is a standardized way for LLMs to access tools via a client–server architecture.
Think of it as a JSON schema with agreed-upon endpoints.
Anthropic said, "Hey, let's all use the same JSON format when connecting AI to tools" and everyone said "Sure."
Check this👇
MCP is a standardized way for LLMs to access tools via a client–server architecture.
Think of it as a JSON schema with agreed-upon endpoints.
Anthropic said, "Hey, let's all use the same JSON format when connecting AI to tools" and everyone said "Sure."
Check this👇
2️⃣ MCP vs Function calling for LLMs
Before MCPs became popular, AI workflows relied on traditional Function Calling for tool access. Now, MCP is standardizing it for Agents/LLMs.
The visual covers how Function Calling & MCP work under the hood.
Check this out👇
Before MCPs became popular, AI workflows relied on traditional Function Calling for tool access. Now, MCP is standardizing it for Agents/LLMs.
The visual covers how Function Calling & MCP work under the hood.
Check this out👇
3️⃣ 4 stages of training LLMs from scratch
This visual covers the 4 stages of building LLMs from scratch to make them practically applicable.
- Pre-training
- Instruction fine-tuning
- Preference fine-tuning
- Reasoning fine-tuning
Check this out👇
This visual covers the 4 stages of building LLMs from scratch to make them practically applicable.
- Pre-training
- Instruction fine-tuning
- Preference fine-tuning
- Reasoning fine-tuning
Check this out👇
4️⃣ Reinforcement fine-tuning using GRPO
A recipe to build your own reasoning models!
This breakthrough technique was used by DeepSeek to build the world's first reasoning model.
Here's the entire GRPO process explained visually.
Check this out👇
A recipe to build your own reasoning models!
This breakthrough technique was used by DeepSeek to build the world's first reasoning model.
Here's the entire GRPO process explained visually.
Check this out👇
5️⃣ 3 Prompting Techniques for Reasoning in LLMs
This covers three popular prompting techniques that help LLMs think more clearly before they answer.
- Chain of Thought (CoT)
- Self-Consistency (or Majority Voting over CoT)
- Tree of Thoughts (ToT)
Check this out👇
This covers three popular prompting techniques that help LLMs think more clearly before they answer.
- Chain of Thought (CoT)
- Self-Consistency (or Majority Voting over CoT)
- Tree of Thoughts (ToT)
Check this out👇
6️⃣ Transformer vs. Mixture of Experts in LLMs
Mixture of Experts (MoE) is a popular architecture that uses different "experts" to improve Transformer models.
The visual below explains how they differ from Transformers.
Check this out👇
Mixture of Experts (MoE) is a popular architecture that uses different "experts" to improve Transformer models.
The visual below explains how they differ from Transformers.
Check this out👇
7️⃣ RAG vs Agentic RAG
Naive RAG retrieves once and generates once, it cannot dynamically search for more info, and it cannot reason through complex queries.
Agentic RAG solves this.
Check this out👇
Naive RAG retrieves once and generates once, it cannot dynamically search for more info, and it cannot reason through complex queries.
Agentic RAG solves this.
Check this out👇
8️⃣ RAG vs Graph RAG
Answering questions that need global context is difficult with traditional RAG since it only retrieves the top-k relevant chunks.
Graph RAG makes RAG more robust with graph structures.
Check this out👇
Answering questions that need global context is difficult with traditional RAG since it only retrieves the top-k relevant chunks.
Graph RAG makes RAG more robust with graph structures.
Check this out👇
9️⃣ JSON (Structured) prompting for LLMs
JSON is like writing modular code; it brings clarity of thought, makes adding new requirements effortless, & creates better communication with AI.
It's not just a technique, it's a habit worth developing for cleaner AI interactions.
JSON is like writing modular code; it brings clarity of thought, makes adding new requirements effortless, & creates better communication with AI.
It's not just a technique, it's a habit worth developing for cleaner AI interactions.
🔟 KV caching
KV caching is a technique used to speed up LLM inference.
Check this out👇
KV caching is a technique used to speed up LLM inference.
Check this out👇
That's a wrap!
If you found it insightful, reshare with your network.
Find me → @akshay_pachaar ✔️
For more insights and tutorials on LLMs, AI Agents, and Machine Learning!
If you found it insightful, reshare with your network.
Find me → @akshay_pachaar ✔️
For more insights and tutorials on LLMs, AI Agents, and Machine Learning!
https://twitter.com/703601972/status/1966485352778256628
• • •
Missing some Tweet in this thread? You can try to
force a refresh