
Aligning an AI with human preferences might be hard. But there is more than one AI out there, and users can choose which to use. Can we get the benefits of a fully aligned AI without solving the alignment problem? In a new paper we study a setting in which the answer is yes. 

Imagine predictive medicine LLMs being used by a doctor to help treat patients. One is made by Merck. The doctor wants to cure his patients as quickly as possible. The Merck LLM also tries to do this, but has a preference for Merck drugs, resulting in substantial misalignment.
Say there is another predictive medicine AI out there made by Pfizer. It is similar but has a preference for Pfizer drugs. Both AIs are substantially misaligned, but they are differently misaligned, and the doctor's utility is well approximated by the average of the AI utilities.
Merck and Pfizer both know that they are competing in an AI marketplace, and deploy their LLMs strategically to advance their goals. Given this competition, perhaps the doctor can use both AIs to the same effect as if there was an AI that was perfectly aligned.
We give several mathematical models of AI competition in which the answer is yes, provided that the user's utility function lies in the convex hull of the AI utility functions. Under this condition, all equilibria of the game between AI providers leads to high user utility.
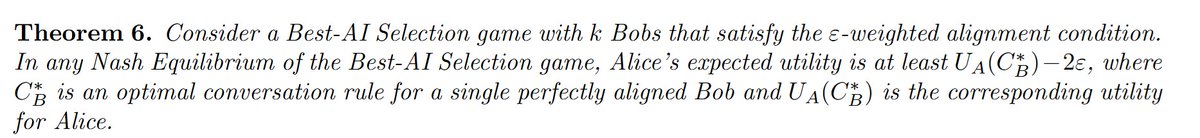
Even if all of the AI providers are very badly aligned, if it is possible to approximate the user's utility by any non-negative linear combination of their utilities, then the user does as well as they would with a perfectly aligned AI. Alignment emerges from competition.
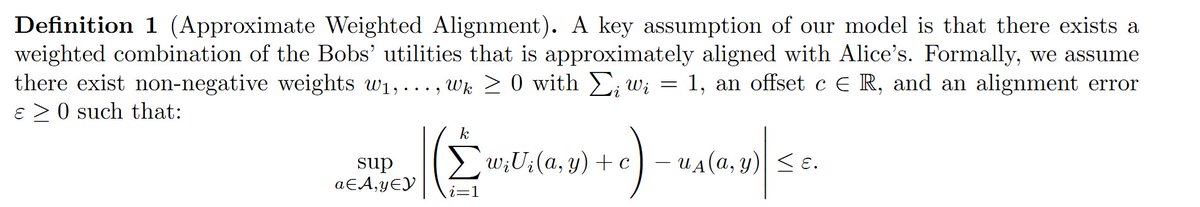
We give simple experiments (where LLM personas are generated with prompt variation) demonstrating that representing user utility functions somewhere in the convex hull of LLM utility functions is a much easier target than finding a single well aligned LLM utility function.
This is intuitive. Think about politics. It might be hard to find a public figure who agrees with you on every issue --- but its probably not hard to find one who is to the right of you on most issues, -and- one who is to the left of you on most issues. Convex hulls are large.
We conduct another simple experiment in which we explicitly compute equilibria amongst differently misaligned sets of agents. The results validate our theory --- user utility can sometimes match our worst case bound (so its tight), but is often much better.
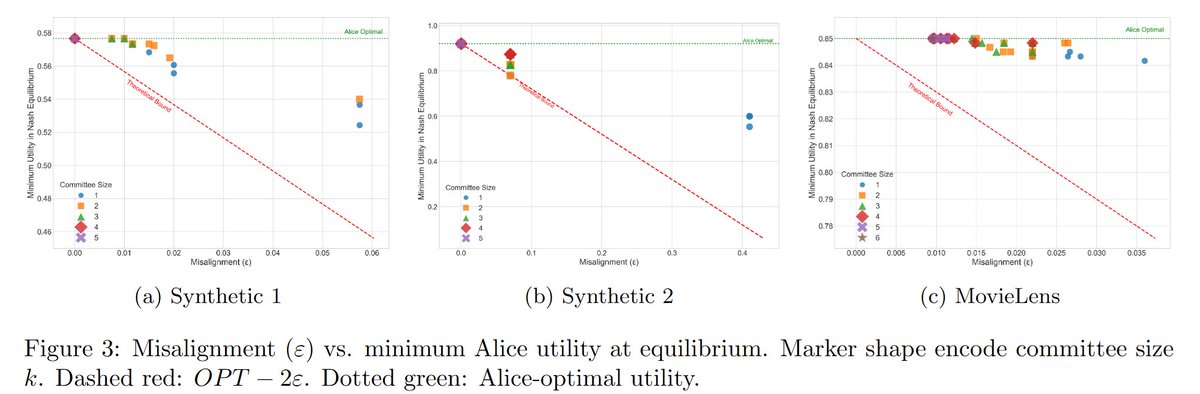
I'm excited about this line of work. We get clean results in a stylized setting, and there is much to do to bring these kinds of ideas closer to practice. But I think that ideas from market and mechanism design should have lots to say about the practical alignment problem too.

The paper is here: and is joint work with the excellent @natalie_collina, @SurbhiGoel_, Emily Ryu, and Mirah Shi. arxiv.org/abs/2509.15090




• • •
Missing some Tweet in this thread? You can try to
force a refresh









