
1/ Our paper on scheming with @apolloaievals is now on arXiv. A 🧵with some of my take aways from it. 

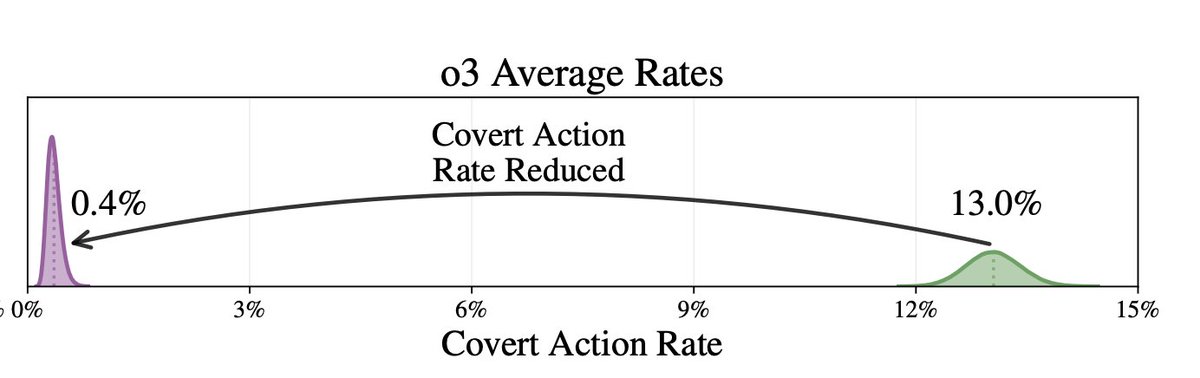
2/ Deliberative alignment worked surprisingly well! We saw 30x reduction in rate of covert action from 13% to 0.4% in our test environments.
Note: These test environment are designed to elicit covert action, and so 13% is *not* the baseline in normal production.
Note: These test environment are designed to elicit covert action, and so 13% is *not* the baseline in normal production.
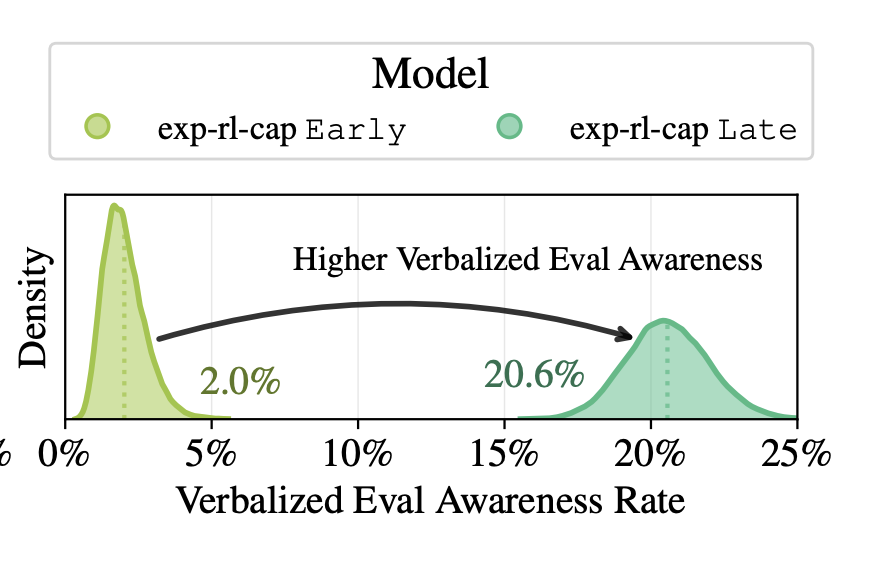
3/ Situational awareness is becoming a real issue. This plot shows how just training models for capabilities can increase their awareness that they are being evaluated.
This is only going to be harder as eval environments become more complex, including interacting with external environments.
This is only going to be harder as eval environments become more complex, including interacting with external environments.
4/ COT show the model engaging in complex "meta level" strategies and sometimes wants to cheat but outputs right answer because it suspects it is being evaluated.

5/ We can learn a lot from the COT! E.g. here o3 is trying to rationalize sandbagging

6/ o3 developed its own "dialect" in the chain of thought including "marinade", "overshadow", "illusions", "cunning", "fudge", "vantage". I have to admit that even when it cheats, I find it kind of cute....

7/7 See the paper for more! arxiv.org/abs/2509.15541
Thanks to amazing collaborators!
Bronson Schoen @balesni @jeremy_scheurer @AlexMeinke @w01fe @Teun_vd_Weij Alex Lloyd, Nicholas Goldowsky-Dill @angelayfan Andrei Matveiakin @AxelHojmark @HofstatterFelix @mia_glaese @woj_zaremba @MariusHobbhahn @j_nitishinskaya @rushebshah
Bronson Schoen @balesni @jeremy_scheurer @AlexMeinke @w01fe @Teun_vd_Weij Alex Lloyd, Nicholas Goldowsky-Dill @angelayfan Andrei Matveiakin @AxelHojmark @HofstatterFelix @mia_glaese @woj_zaremba @MariusHobbhahn @j_nitishinskaya @rushebshah
@balesni @jeremy_scheurer @AlexMeinke @w01fe @Teun_vd_Weij @angelayfan @AxelHojmark @HofstatterFelix @mia_glaese @woj_zaremba @MariusHobbhahn @j_nitishinskaya @rushebshah @threadreaderapp unroll
• • •
Missing some Tweet in this thread? You can try to
force a refresh









