I finally solved player recognition
- player and number detection with RF-DETR
- player tracking with SAM2
- team clustering with SigLIP, UMAP and KMeans
- number recognition with SmolVLM2
stay tuned for YT tutorial:
↓ full breakdown + code youtube.com/c/Roboflow
- player and number detection with RF-DETR
- player tracking with SAM2
- team clustering with SigLIP, UMAP and KMeans
- number recognition with SmolVLM2
stay tuned for YT tutorial:
↓ full breakdown + code youtube.com/c/Roboflow
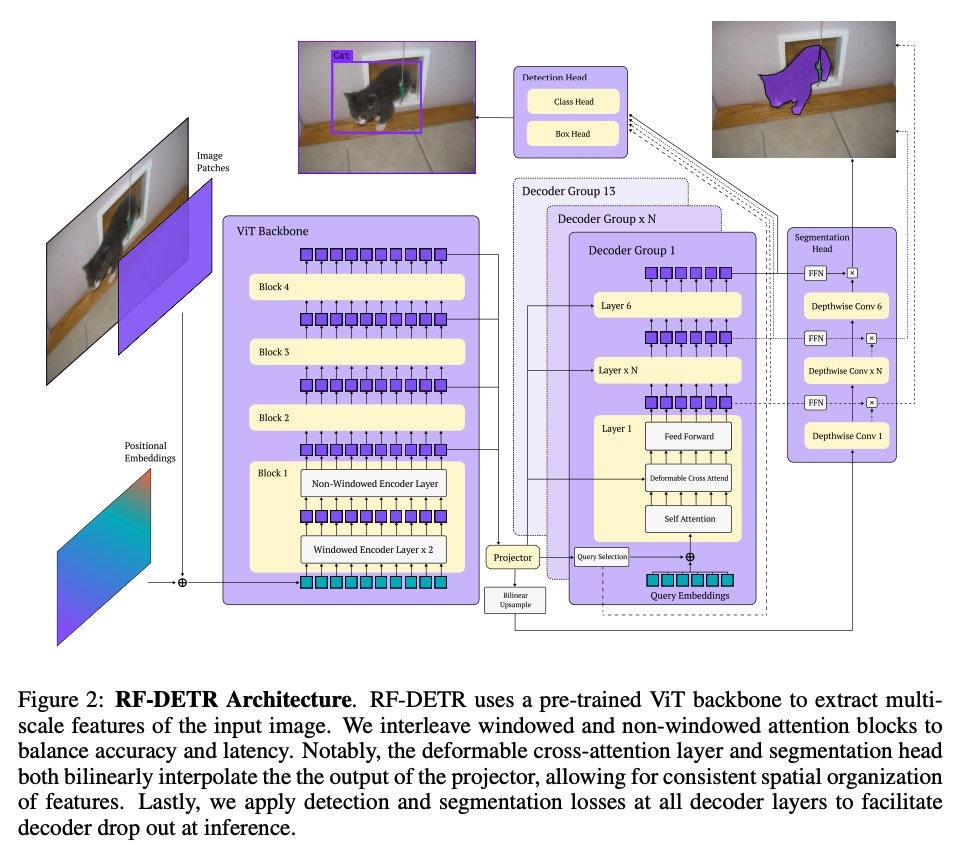
we start with RF-DETR model fine-tuned to detect players, numbers, referees, ball, rim
model + dataset: universe.roboflow.com/roboflow-jvuqo…
model + dataset: universe.roboflow.com/roboflow-jvuqo…
I recently used the same model to build a jump shot make-or-miss demo, which will also be included in my upcoming YT tutorial
google colab: github.com/roboflow/noteb…
google colab: github.com/roboflow/noteb…
SAM2.1 tracks objects across video using visual prompts like boxes or points
we use a fine-tuned RF-DETR to detect all players in the first frame, pass these detections to SAM2.1, and track them in the following frames
we use a fine-tuned RF-DETR to detect all players in the first frame, pass these detections to SAM2.1, and track them in the following frames
I sample frames, detect players, crop the central regions, generate SigLIP embeddings, reduce them with UMAP, and cluster with KMeans to separate players into two teams
I used the same strategy in last year’s Football AI project. I also recorded a YouTube tutorial covering it
check it out if you haven’t already:
check it out if you haven’t already:
reading player numbers from small and blurry crops is not easy
traditional OCR models struggle with this task
for this reason, we decided to use SmolVLM2, fine-tuned on a custom multi-modal dataset
@andimarafioti @mervenoyann
model + dataset: universe.roboflow.com/roboflow-jvuqo…
traditional OCR models struggle with this task
for this reason, we decided to use SmolVLM2, fine-tuned on a custom multi-modal dataset
@andimarafioti @mervenoyann
model + dataset: universe.roboflow.com/roboflow-jvuqo…

the next step is to match each jersey number to the right player using the mask IoS metric
unlike IoU, which measures overlap against the union, IoS measures it against the smaller area, so a smaller object fully inside a larger one gives IoS = 1
unlike IoU, which measures overlap against the union, IoS measures it against the smaller area, so a smaller object fully inside a larger one gives IoS = 1


as player positions change, jersey numbers are not always clear, so relying on a single prediction is unreliable
to reduce errors, we validate numbers across frames
you can see in the video how numbers stabilize once they stay visible across consecutive frames
to reduce errors, we validate numbers across frames
you can see in the video how numbers stabilize once they stay visible across consecutive frames
code for those of you who really want to have some fun: colab.research.google.com/github/roboflo…
• • •
Missing some Tweet in this thread? You can try to
force a refresh