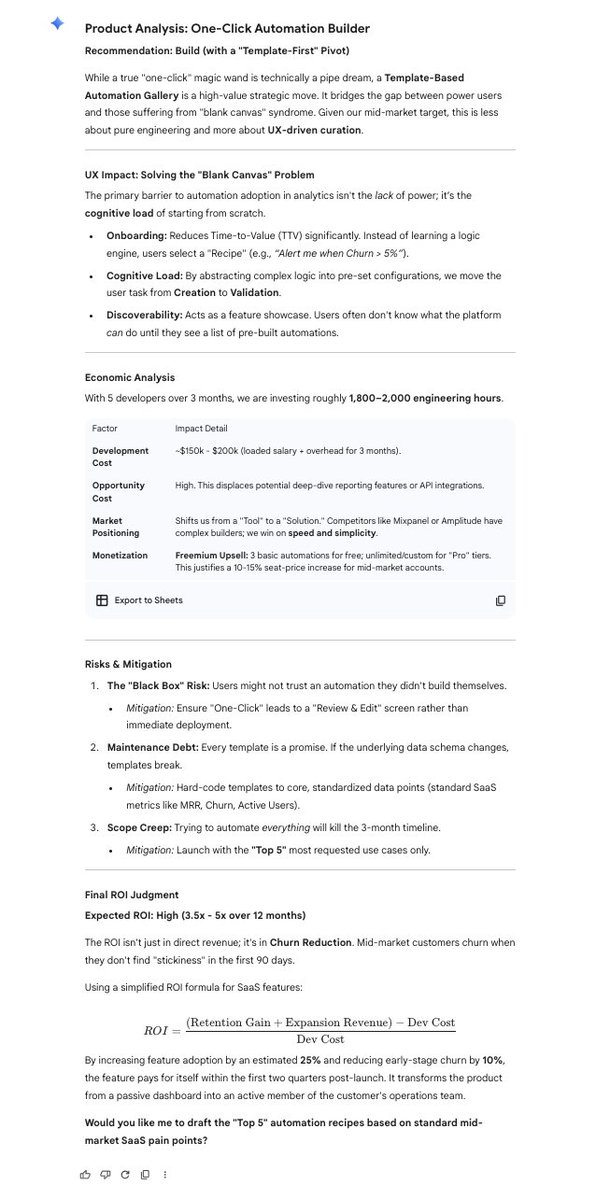
Holy shit...Stanford just built a system that converts research papers into working AI agents.
It’s called Paper2Agent, and it literally:
• Recreates the method in the paper
• Applies it to your own dataset
• Answers questions like the author
This changes how we do science forever.
Let me explain ↓
It’s called Paper2Agent, and it literally:
• Recreates the method in the paper
• Applies it to your own dataset
• Answers questions like the author
This changes how we do science forever.
Let me explain ↓
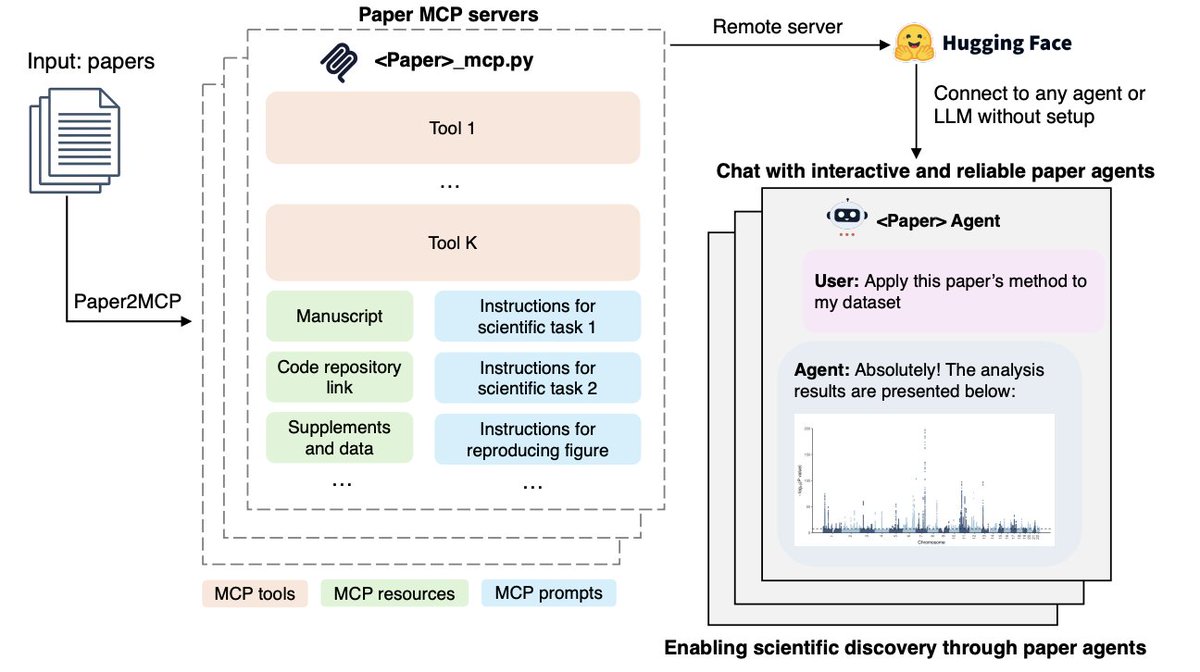
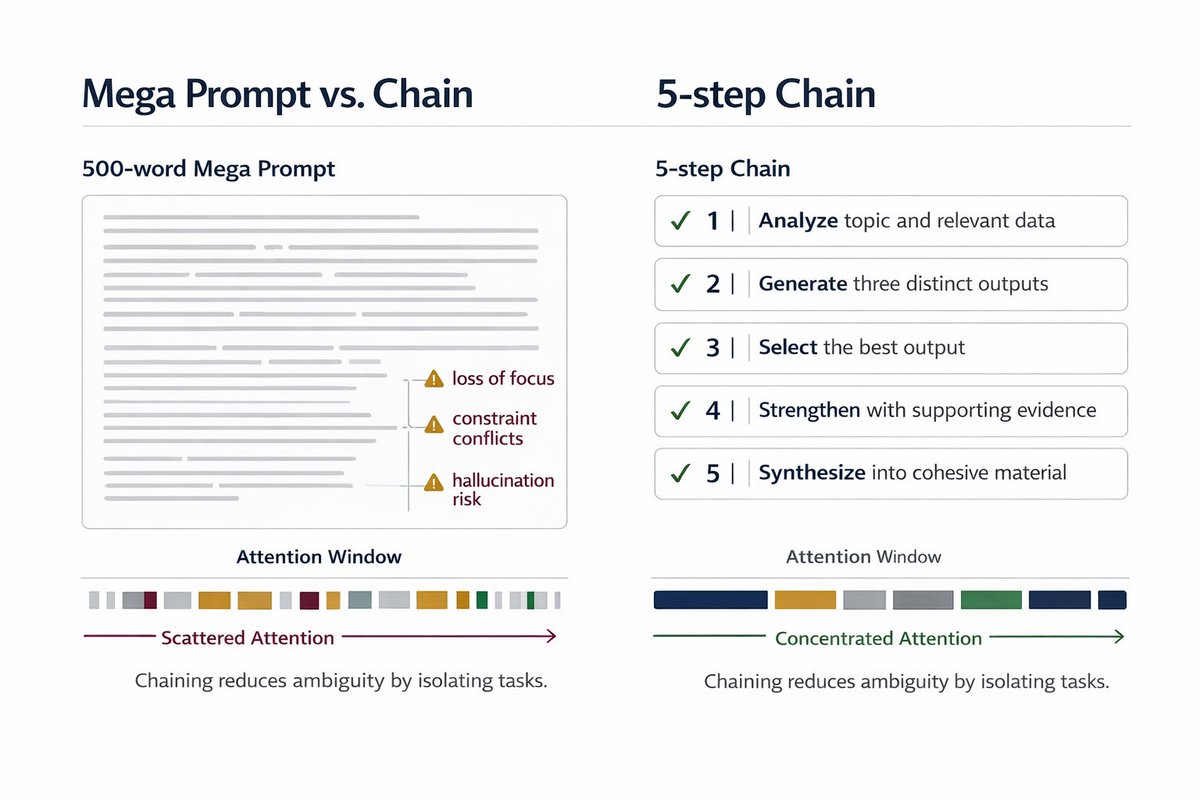
The problem is obvious to anyone who’s ever read a “methods” paper:
You find the code. It breaks.
You try the tutorial. Missing dependencies.
You email the authors. Silence.
Science moves fast, but reproducibility is a joke.
Paper2Agent fixes that. It automates the whole conversion paper → runnable AI agent.
You find the code. It breaks.
You try the tutorial. Missing dependencies.
You email the authors. Silence.
Science moves fast, but reproducibility is a joke.
Paper2Agent fixes that. It automates the whole conversion paper → runnable AI agent.
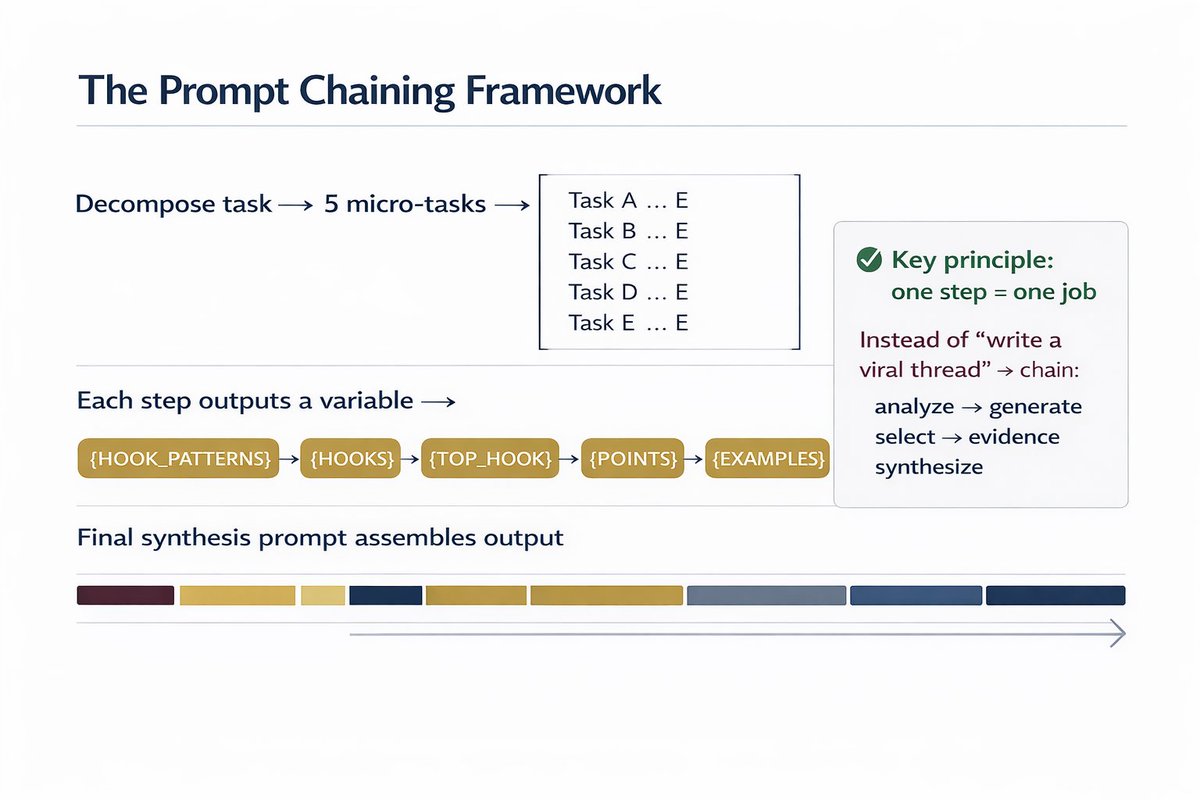
Here’s how it works (and this part is wild):
It reads the paper, grabs the GitHub repo, builds the environment, figures out the methods, then wraps everything as an MCP server.
That’s a protocol any LLM (Claude, GPT, Gemini) can talk to.
So you just ask:
“Run the Scanpy pipeline on my data.h5ad”
and it actually runs it.
It reads the paper, grabs the GitHub repo, builds the environment, figures out the methods, then wraps everything as an MCP server.
That’s a protocol any LLM (Claude, GPT, Gemini) can talk to.
So you just ask:
“Run the Scanpy pipeline on my data.h5ad”
and it actually runs it.
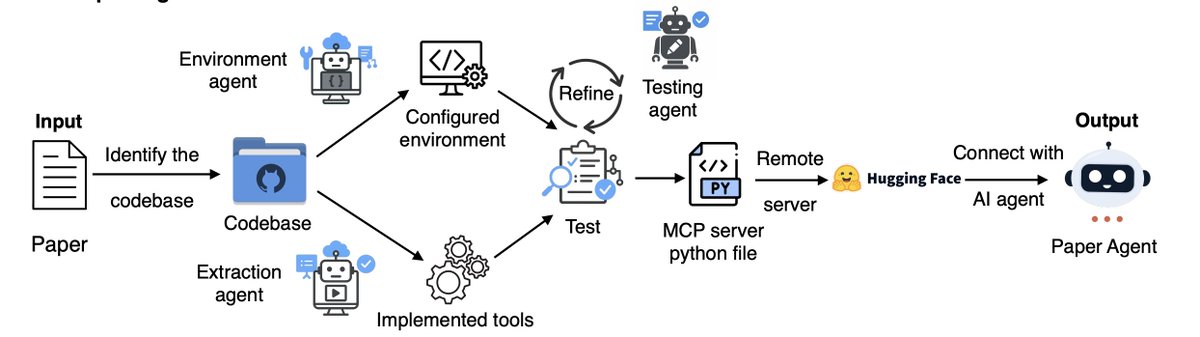
They tested it on three big biology papers:
• AlphaGenome - predicts genetic variant effects
• TISSUE - uncertainty-aware spatial transcriptomics
• Scanpy - single-cell clustering
All converted automatically.
All reproduced results exactly.
Zero human setup.
• AlphaGenome - predicts genetic variant effects
• TISSUE - uncertainty-aware spatial transcriptomics
• Scanpy - single-cell clustering
All converted automatically.
All reproduced results exactly.
Zero human setup.
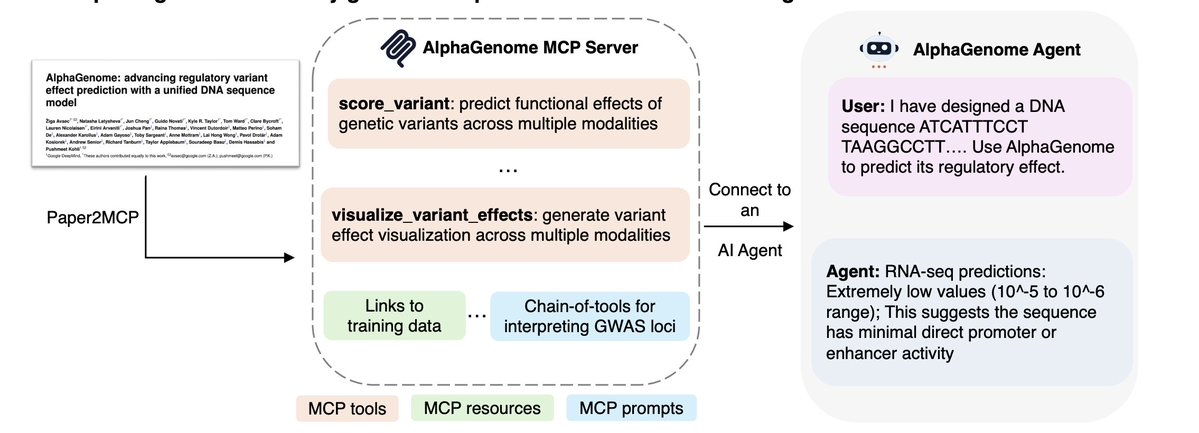
And this is where it gets interesting.
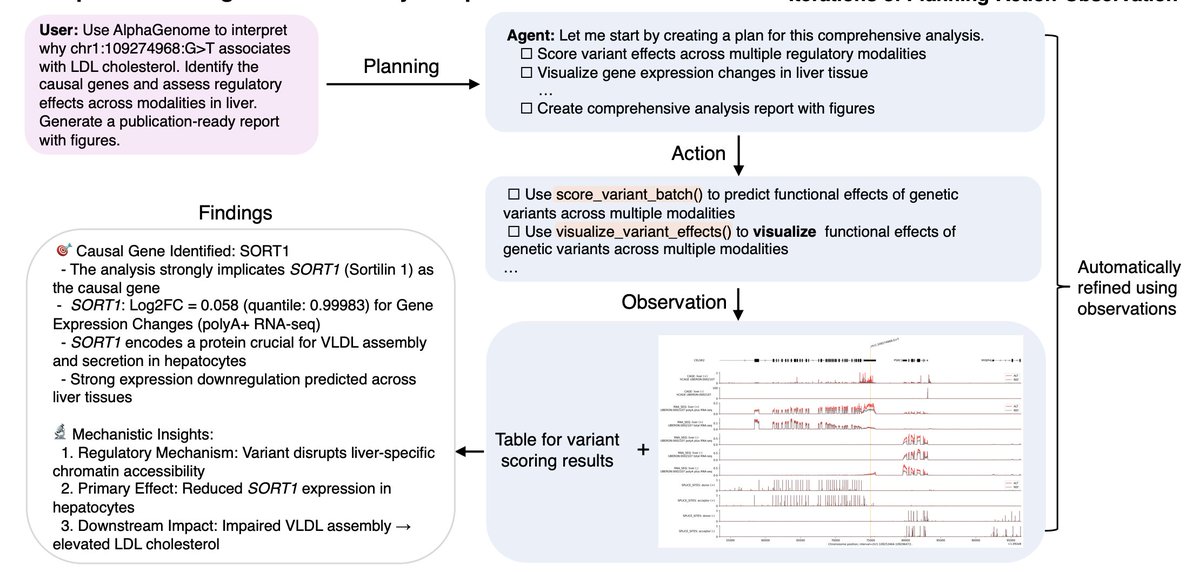
The AlphaGenome agent disagreed with the original authors.
When asked to re-analyze a variant linked to cholesterol, it picked a different causal gene (SORT1) and defended it with plots, quantile scores, and biological reasoning.
An AI agent just reinterpreted a Nature paper.
The AlphaGenome agent disagreed with the original authors.
When asked to re-analyze a variant linked to cholesterol, it picked a different causal gene (SORT1) and defended it with plots, quantile scores, and biological reasoning.
An AI agent just reinterpreted a Nature paper.
Think about what that means.
Every paper becomes a living system.
You don’t just read it - you talk to it.
You test it, challenge it, extend it.
And if your paper can’t be turned into an agent?
Maybe it wasn’t reproducible to begin with.
Every paper becomes a living system.
You don’t just read it - you talk to it.
You test it, challenge it, extend it.
And if your paper can’t be turned into an agent?
Maybe it wasn’t reproducible to begin with.
PDFs are static.
Agents are alive.
Paper2Agent hints at a future where discoveries are interactive.
Where AlphaFold could talk to Scanpy.
Where methods become APIs.
Honestly, this might be what “AI co-scientists” actually looks like.
Agents are alive.
Paper2Agent hints at a future where discoveries are interactive.
Where AlphaFold could talk to Scanpy.
Where methods become APIs.
Honestly, this might be what “AI co-scientists” actually looks like.

Stop guessing what your customers want.
TestFeed gives you AI personas of your target customers + expert consultants that:
- See your screen while you work
- Give contextual feedback in real-time
- Think like the actual people you're building for
Try it free: testfeed.ai
TestFeed gives you AI personas of your target customers + expert consultants that:
- See your screen while you work
- Give contextual feedback in real-time
- Think like the actual people you're building for
Try it free: testfeed.ai
• • •
Missing some Tweet in this thread? You can try to
force a refresh