
Apple just changed the game with AI. But it's not what you think.
They used AI agents to cut software testing time 85% and improve accuracy 45%.
Apple proved the ROI of AI.
This is not what I expected from them.
What else are they cooking in Cupertino?
Here's how it works:
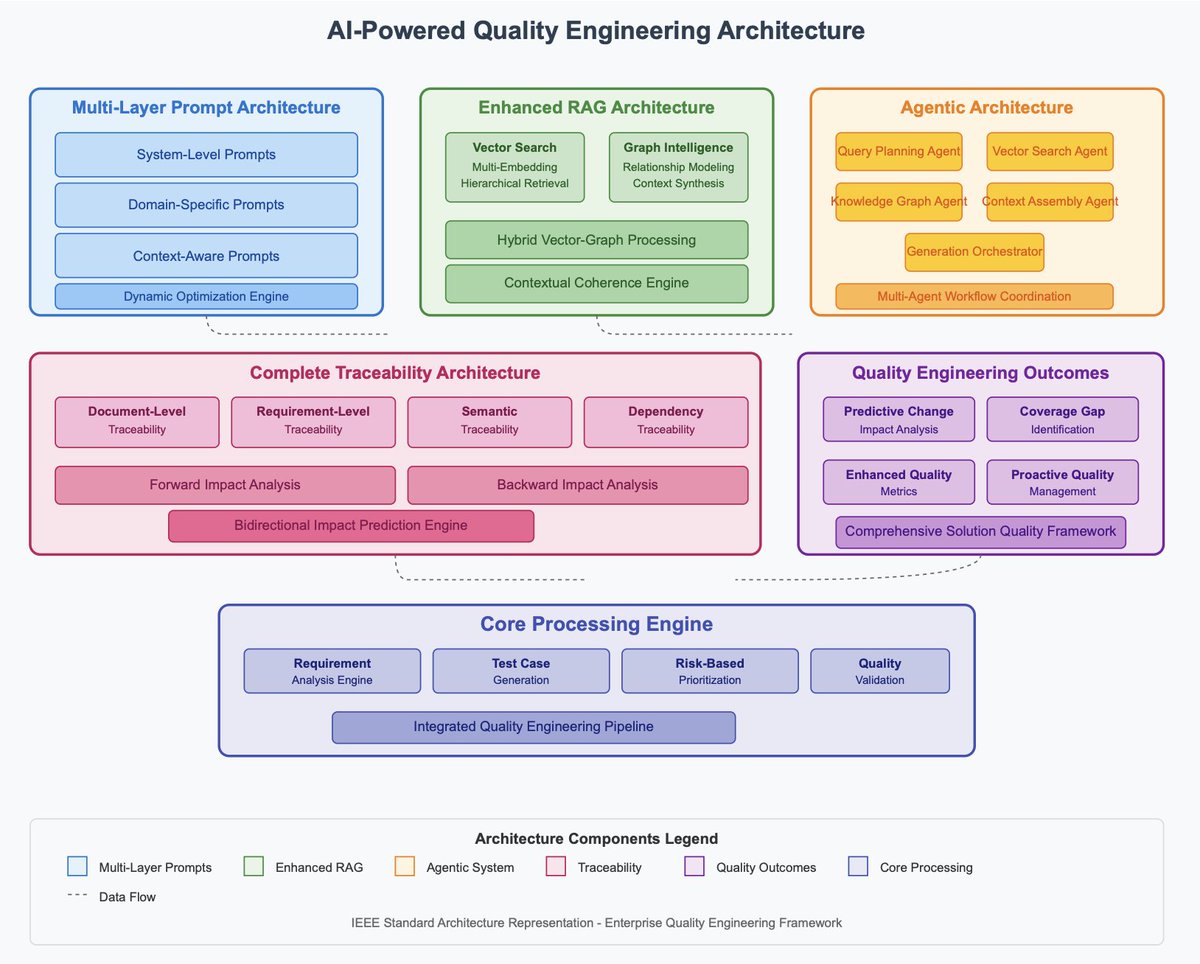
- Map: Feeds all project documentation into a hybrid knowledge base using a vector database for semantic search and a graph database (TigerGraph). It maps the relationships between business processes that AI often misses.
- Delegate: Assigns specific jobs to a team of specialized agents. A 'legacy analysis' agent, a 'compliance validator,' and a 'test case generator' work together. They used Gemini Pro for complex reasoning.
- Automate: Generates 25,000 test cases with full contextual awareness, achieving 98.7% functional coverage and complete requirement traceability from end to end.
Result: This Agentic RAG system improved accuracy by 45% (from 65.2% to 94.8%), crushing the baseline of older AI methods.
This isn't a lab experiment. It was validated on a real-world SAP S/4HANA migration with over 100 external system integrations.
Why this matters:
- Business Leaders: An 85% timeline reduction and a projected 35% cost saving is a massive competitive advantage. This de-risks projects and changes the economics of enterprise software deployment.
- Practitioners: This provides a production-grade blueprint to use AI for creating test artifacts. The hybrid vector-graph architecture solves the context-loss problem that plagues most enterprise AI automation.
- Researchers: This paper provides a real-world validation of multi-agent systems. It demonstrates that moving from monolithic RAG to orchestrated, specialized agents is necessary for solving complex, context-dependent enterprise problems.
They used AI agents to cut software testing time 85% and improve accuracy 45%.
Apple proved the ROI of AI.
This is not what I expected from them.
What else are they cooking in Cupertino?
Here's how it works:
- Map: Feeds all project documentation into a hybrid knowledge base using a vector database for semantic search and a graph database (TigerGraph). It maps the relationships between business processes that AI often misses.
- Delegate: Assigns specific jobs to a team of specialized agents. A 'legacy analysis' agent, a 'compliance validator,' and a 'test case generator' work together. They used Gemini Pro for complex reasoning.
- Automate: Generates 25,000 test cases with full contextual awareness, achieving 98.7% functional coverage and complete requirement traceability from end to end.
Result: This Agentic RAG system improved accuracy by 45% (from 65.2% to 94.8%), crushing the baseline of older AI methods.
This isn't a lab experiment. It was validated on a real-world SAP S/4HANA migration with over 100 external system integrations.
Why this matters:
- Business Leaders: An 85% timeline reduction and a projected 35% cost saving is a massive competitive advantage. This de-risks projects and changes the economics of enterprise software deployment.
- Practitioners: This provides a production-grade blueprint to use AI for creating test artifacts. The hybrid vector-graph architecture solves the context-loss problem that plagues most enterprise AI automation.
- Researchers: This paper provides a real-world validation of multi-agent systems. It demonstrates that moving from monolithic RAG to orchestrated, specialized agents is necessary for solving complex, context-dependent enterprise problems.

Apple's multi agent software testing cut testing time per task from 18 min to just 1.5 min.
They were able to deliver 85% faster slashing YEARS off their project timeline.
They were able to deliver 85% faster slashing YEARS off their project timeline.

Apple's Agentic RAG system beat every other method in accuracy, completeness, consistency, and traceability.

Apple gave the blueprint for enterprise grade AI powered software testing.
Agentic RAG for Software Testing with Hybrid Vector-Graph and Multi-Agent Orchestration by @Apple
Submitted: 12 Oct 2025
arxiv.org/abs/2510.10824
Submitted: 12 Oct 2025
arxiv.org/abs/2510.10824
• • •
Missing some Tweet in this thread? You can try to
force a refresh









