I keep saying “drug discovery” but most of my audience does not understand what this means.
Here’s a thread I worked on over the past week trying to distil down drug discovery - and why it matters in the age of AI.
OPEN THE THREAD 🧵
Here’s a thread I worked on over the past week trying to distil down drug discovery - and why it matters in the age of AI.
OPEN THE THREAD 🧵
Drug discovery is how molecules become medicine.
A $180 billion guessing game where up to 97% of candidates fail in trials.
We can now predict protein folds (thanks to AlphaFold), but still cannot simulate what a drug actually does to a living cell in real time.
A $180 billion guessing game where up to 97% of candidates fail in trials.
We can now predict protein folds (thanks to AlphaFold), but still cannot simulate what a drug actually does to a living cell in real time.
At its core, drug discovery asks one question:
=> What happens inside a cell when we “perturb” it? (drug it)
Traditional biology answers by destroying the cell to measure it.
Every assay is a snapshot. Every snapshot costs reagents, time, and lives.
=> What happens inside a cell when we “perturb” it? (drug it)
Traditional biology answers by destroying the cell to measure it.
Every assay is a snapshot. Every snapshot costs reagents, time, and lives.
Historically, the process looked like this:
1️⃣ Identify a target — a protein or pathway driving disease.
2️⃣ Screen millions of molecules.
3️⃣ Optimize a few leads.
4️⃣ Test in animals, then people.
Ten years later, maybe one succeeds.
1️⃣ Identify a target — a protein or pathway driving disease.
2️⃣ Screen millions of molecules.
3️⃣ Optimize a few leads.
4️⃣ Test in animals, then people.
Ten years later, maybe one succeeds.
Why so much failure?
Because we’ve been studying biology as frames, not films.
Static images hide dynamics:
transient states where toxicity, resistance, or synergy emerge.
Drug effects unfold in time. But our tools freeze time.
Because we’ve been studying biology as frames, not films.
Static images hide dynamics:
transient states where toxicity, resistance, or synergy emerge.
Drug effects unfold in time. But our tools freeze time.
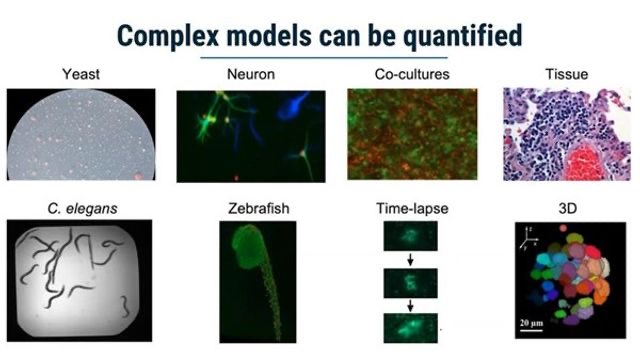
Compute allows us to create thousands of potential candidates.
AI has helped us filter these, but it cannot replace wet labs without the right data.
AI has helped us filter these, but it cannot replace wet labs without the right data.
MOLECULAR DYNAMICS WERE CRACKED
This is where AI entered the story.
AI gave structure prediction (AlphaFold), docking, screening.
But most AI still learns from static databases, not living data.
We need AI that learns from life itself:
continuous, label-free, real-time data.
This is where AI entered the story.
AI gave structure prediction (AlphaFold), docking, screening.
But most AI still learns from static databases, not living data.
We need AI that learns from life itself:
continuous, label-free, real-time data.
CELL DYNAMICS ARE UNKNOWN BECAUSE WE DID NOT HAVE THE DATA TO GIVE AI “EYES” INTO THEM WITH OUR STATIC PLATE READING DATA.
Enter the new paradigm.
At Precigenetics, where I’m founder & CEO, we’re building exactly that:
a photonic + AI engine that observes how cells respond to any compound, in real time
without dyes, reagents, or destruction.
Think AlphaFold for whole cells.
At Precigenetics, where I’m founder & CEO, we’re building exactly that:
a photonic + AI engine that observes how cells respond to any compound, in real time
without dyes, reagents, or destruction.
Think AlphaFold for whole cells.
Our platform uses novel hardware - photons interacting with molecular vibrations - to map the evolving chemistry inside each cell.
Then transformer models read these spectral time-series, predicting mechanisms of action (MoA) and fate hours before visible change.
Then transformer models read these spectral time-series, predicting mechanisms of action (MoA) and fate hours before visible change.
Retrieving such data required $10,000 per plate at the bare minimum.
With Precigenetics? It requires 4 minutes of time per frame.
With Precigenetics? It requires 4 minutes of time per frame.
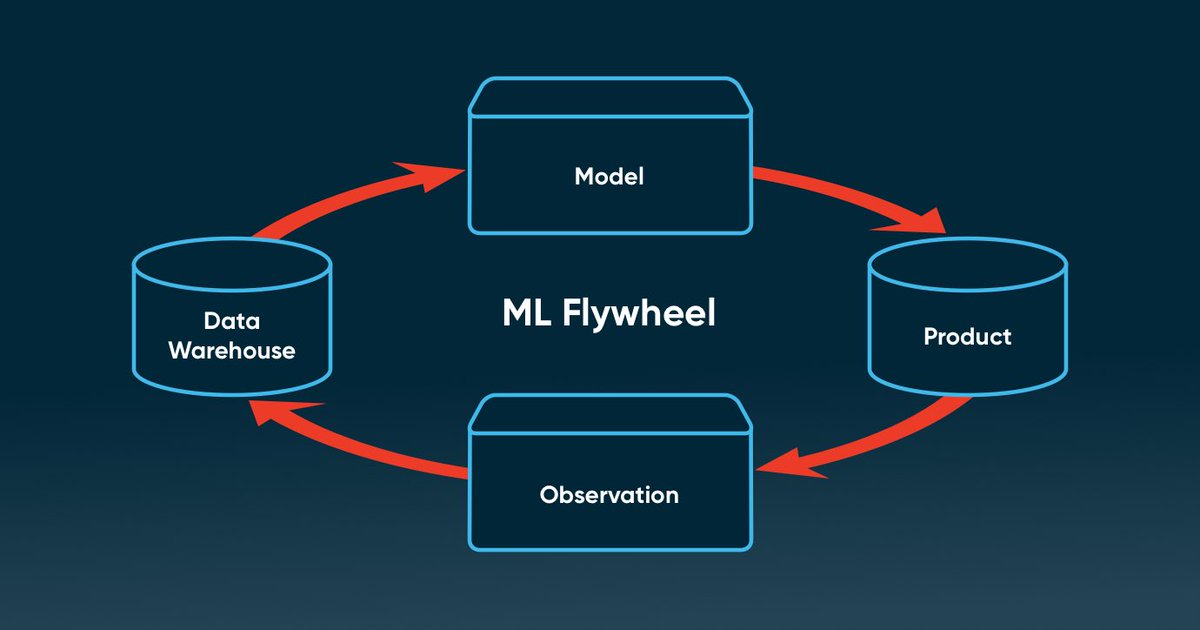
Once a scanner is installed, each new experiment is zero-marginal-cost.
Photons do the work.
Every scan enriches the AI model.
A data flywheel begins - the more we observe, the smarter the engine gets.
That’s how biology becomes digitizable.
Photons do the work.
Every scan enriches the AI model.
A data flywheel begins - the more we observe, the smarter the engine gets.
That’s how biology becomes digitizable.
We already see it in action.
In melanoma disease models, we detect apoptotic vs. non-apoptosis cell death before its visible - predicting clinical trials before they happen.
In melanoma disease models, we detect apoptotic vs. non-apoptosis cell death before its visible - predicting clinical trials before they happen.
it gets a whole lot more interesting once you consider human organoids.
by testing drugs on patient cells before ever undergoing a $4B clinical trial for 10 years, with 97% odds against you, we learn how cells will interact in real time.
will a drug affect only cancer cells?
by testing drugs on patient cells before ever undergoing a $4B clinical trial for 10 years, with 97% odds against you, we learn how cells will interact in real time.
will a drug affect only cancer cells?
will the drug cause liver toxicity? we model the liver and try it out on a cohort.
will the drug cause off-target effects? the data to predict these effects finally exists - and it is NOT mouse data anymore; it is disease modelling on real, patient cells.
will the drug cause off-target effects? the data to predict these effects finally exists - and it is NOT mouse data anymore; it is disease modelling on real, patient cells.
this way, you are not working AI around data that is not going to make your drug win.
you are feeding AI the data it needs to know how drugs interact with actual human biology, and letting it do the work.
you are feeding AI the data it needs to know how drugs interact with actual human biology, and letting it do the work.
drug discovery is a matter of understanding which drugs work.
after this, pharma is excellent at taking these drugs to trials.
what it cannot do without Precigenetics, is - figure out which drugs will WIN.
after this, pharma is excellent at taking these drugs to trials.
what it cannot do without Precigenetics, is - figure out which drugs will WIN.
using this novel data, terabytes of it that we have generated in our wet lab, with our custom built hardware, you can finally beat the odds.
the only way to beat Eroom's law is...
the only way to beat Eroom's law is...

...by using a platform that can give you data on billions of cells, in a full-stack, vertically-integrated manner. we achieve this with biophotonics.
we cured mice of cancer decades ago.
because we had this data for mice, and it came with a lot of torture.
we couldn't generalize this to human beings.
because we had this data for mice, and it came with a lot of torture.
we couldn't generalize this to human beings.
but now, we are past mice. we model diseases in human beings, and finally, we have the compute to generalize our understanding of human-drug interactions.
all that is missing? it is the data. the standardized, human data. and it lives in our computers.
all that is missing? it is the data. the standardized, human data. and it lives in our computers.
we standardize data generation, build models, and make it easy for pharmas and AI companies to know that they are betting on the winning drug.
we study cells at the level drugs act on - sub-cellular - and aim to predict clinical trials in hours, not years.
we study cells at the level drugs act on - sub-cellular - and aim to predict clinical trials in hours, not years.
as the flywheel effect expands, our ability to do this expands with it.
cells act in predictable ways - but the context is too broad for scientists.
transformers can parallelize, just like they did with AlphaFold, and make every pharma, every AI company win.
cells act in predictable ways - but the context is too broad for scientists.
transformers can parallelize, just like they did with AlphaFold, and make every pharma, every AI company win.
• • •
Missing some Tweet in this thread? You can try to
force a refresh