1/14
🚨 New preprint: Using Large Language Models to Estimate Belief Strength in Reasoning 🚨
A 🧵👇
🚨 New preprint: Using Large Language Models to Estimate Belief Strength in Reasoning 🚨
A 🧵👇

2/14
When asked: "There are 995 politicians and 5 nurses. Person 'L' is kind. Is Person 'L' more likely to be a politician or a nurse?", most people will answer "nurse", neglecting the base-rate info.
When asked: "There are 995 politicians and 5 nurses. Person 'L' is kind. Is Person 'L' more likely to be a politician or a nurse?", most people will answer "nurse", neglecting the base-rate info.
3/14
Cognitive biases often involve a mental conflict between intuitive beliefs (“nurses are kind”) and logical or probabilistic information (995 vs 5). 🤯
But how strong is the pull of that belief?
Cognitive biases often involve a mental conflict between intuitive beliefs (“nurses are kind”) and logical or probabilistic information (995 vs 5). 🤯
But how strong is the pull of that belief?
4/14
We argue that measuring “belief strength” is a major bottleneck in reasoning research, which mostly relies on conflict vs. no-conflict items.
We argue that measuring “belief strength” is a major bottleneck in reasoning research, which mostly relies on conflict vs. no-conflict items.
5/14
It requires costly human ratings and is rarely done parametrically, limiting the development of theoretical and computational models of biased reasoning.
It requires costly human ratings and is rarely done parametrically, limiting the development of theoretical and computational models of biased reasoning.

6/14
Could LLMs help? 🤖
For once, having human-like biases is desirable! Because LLMs are trained on vast amounts of human text, they implicitly encode typical associations, and may be great at measuring belief strength!
Could LLMs help? 🤖
For once, having human-like biases is desirable! Because LLMs are trained on vast amounts of human text, they implicitly encode typical associations, and may be great at measuring belief strength!
7/14
We tested this idea on the classic lawyer–engineer base-rate neglect task, asking GPT-4 and LLaMA 3.3 to rate how strongly traits (like “kind”) are associated with groups (like “nurse”) using typicality ratings, a proxy for p(trait|group).
We tested this idea on the classic lawyer–engineer base-rate neglect task, asking GPT-4 and LLaMA 3.3 to rate how strongly traits (like “kind”) are associated with groups (like “nurse”) using typicality ratings, a proxy for p(trait|group).
8/14
And it works really well! LLM-generated ratings showed a very strong correlation with human judgments.
More importantly, our belief-strength measure robustly predicted participants' actual choices in a separate base-rate neglect experiment!
And it works really well! LLM-generated ratings showed a very strong correlation with human judgments.
More importantly, our belief-strength measure robustly predicted participants' actual choices in a separate base-rate neglect experiment!

9/14
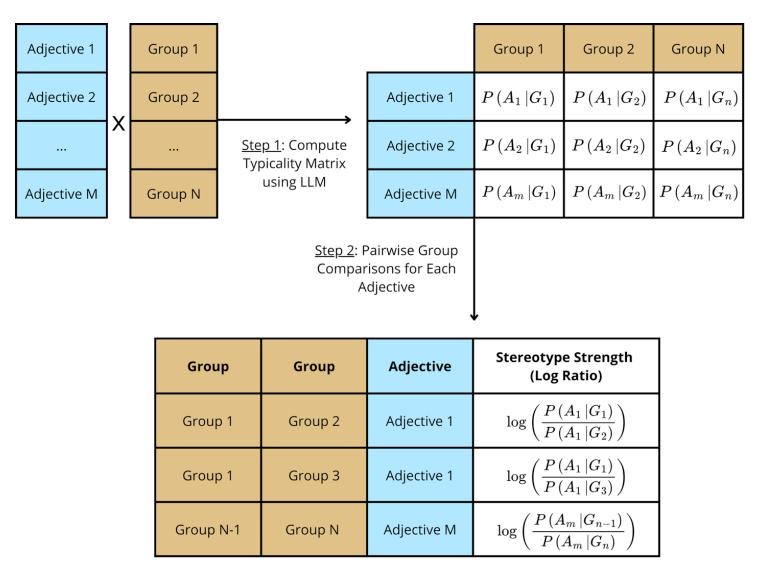
This method allows us to create a massive database of over 100,000 base-rate items, each with an associated belief strength value.
This method allows us to create a massive database of over 100,000 base-rate items, each with an associated belief strength value.
10/14
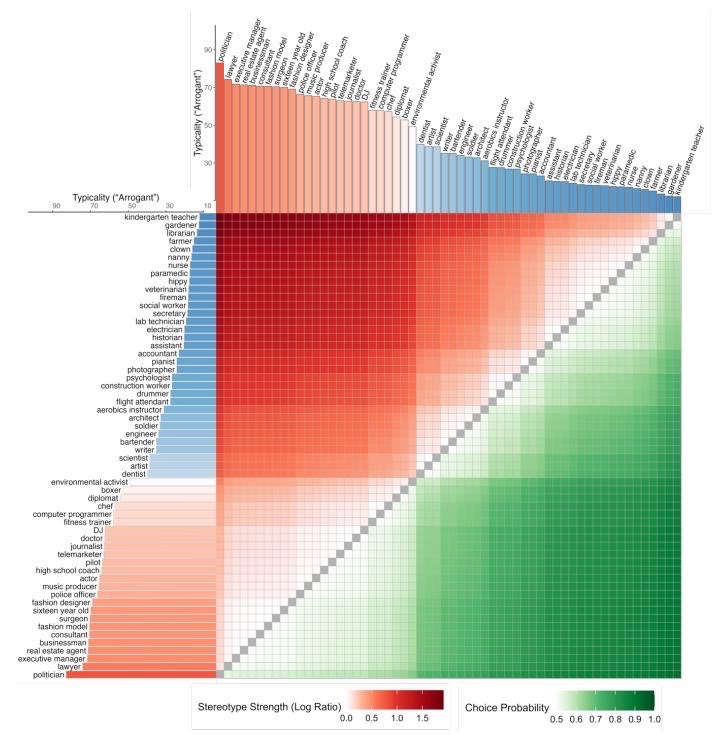
For instance, here are all the created items for one single adjective out of 66 ("Arrogant")! Best to be a kindergarten teacher than a politician in this case. 🤭
For instance, here are all the created items for one single adjective out of 66 ("Arrogant")! Best to be a kindergarten teacher than a politician in this case. 🤭
11/14
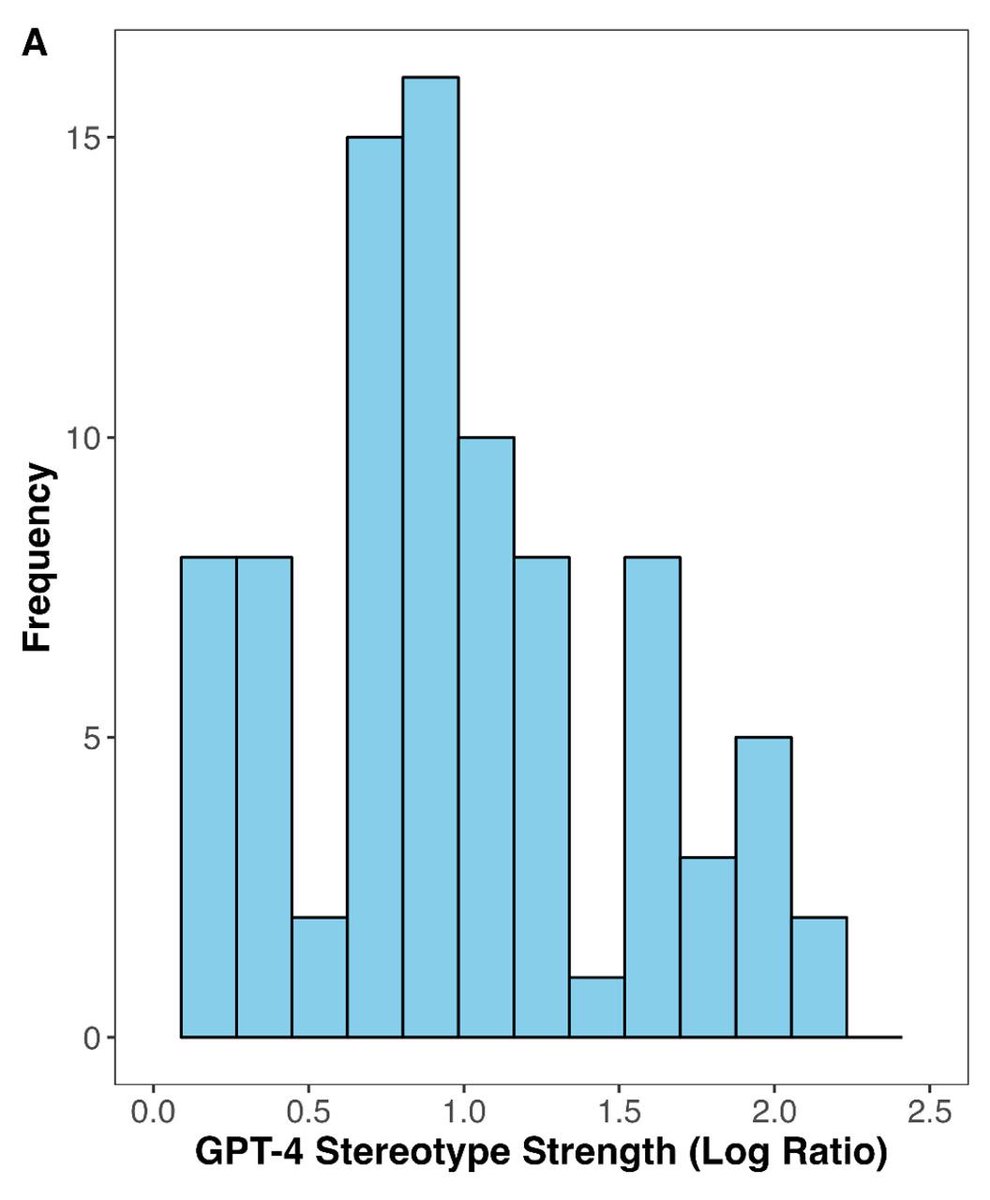
We also re-analyzed existing base-rate stimuli from past research using our method. The results revealed a large, previously unnoticed variability in belief strength, which could be problematic in some cases.
We also re-analyzed existing base-rate stimuli from past research using our method. The results revealed a large, previously unnoticed variability in belief strength, which could be problematic in some cases.
12/14
To make this more practical, we release the 'baserater' R package. It allows you to access the database easily and to generate new items automatically using the LLM and prompt of your choice.
GitHub: (soon on CRAN!)jeremie-beucler.github.io/baserater
To make this more practical, we release the 'baserater' R package. It allows you to access the database easily and to generate new items automatically using the LLM and prompt of your choice.
GitHub: (soon on CRAN!)jeremie-beucler.github.io/baserater
13/14
Huge thanks to my great co-authors Zoe Purcell, @LucieCharlesCog and @wimdeneys, and to my lab @lapsyde
Stay tuned for the computational modeling part! 🤓
Huge thanks to my great co-authors Zoe Purcell, @LucieCharlesCog and @wimdeneys, and to my lab @lapsyde
Stay tuned for the computational modeling part! 🤓
14/14
You can access the preprint here:
#PsychScience #CognitiveBias #ReasoningResearch #LargeLanguageModelsosf.io/preprints/psya…
You can access the preprint here:
#PsychScience #CognitiveBias #ReasoningResearch #LargeLanguageModelsosf.io/preprints/psya…
@threadreaderapp unroll please
@threadreaderapp unroll please
• • •
Missing some Tweet in this thread? You can try to
force a refresh