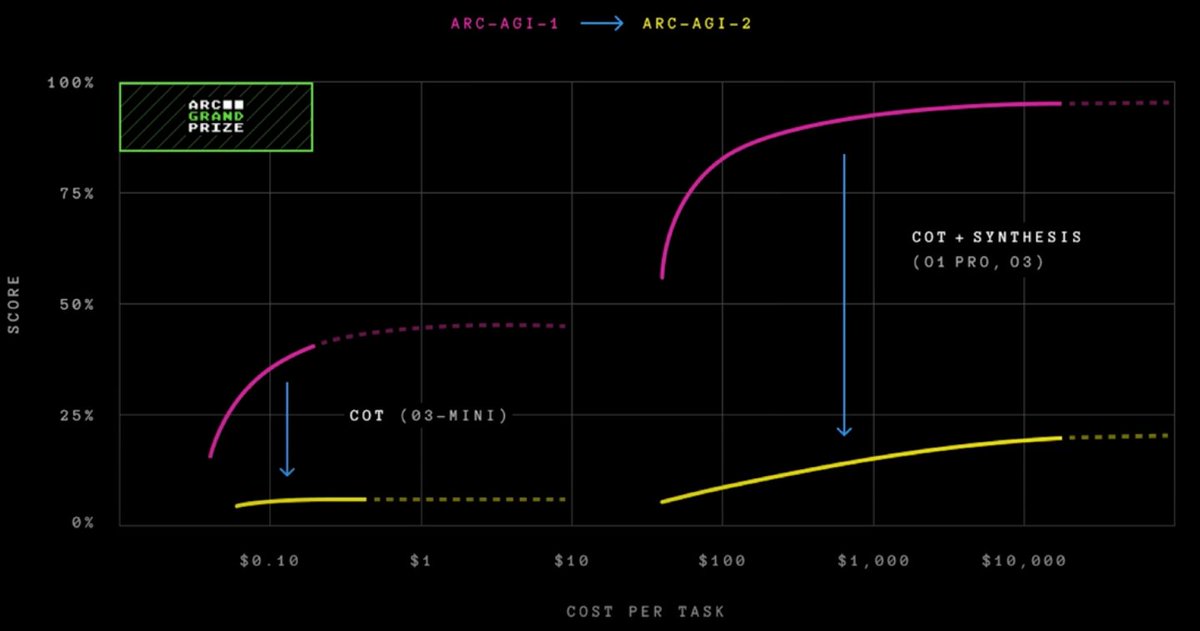
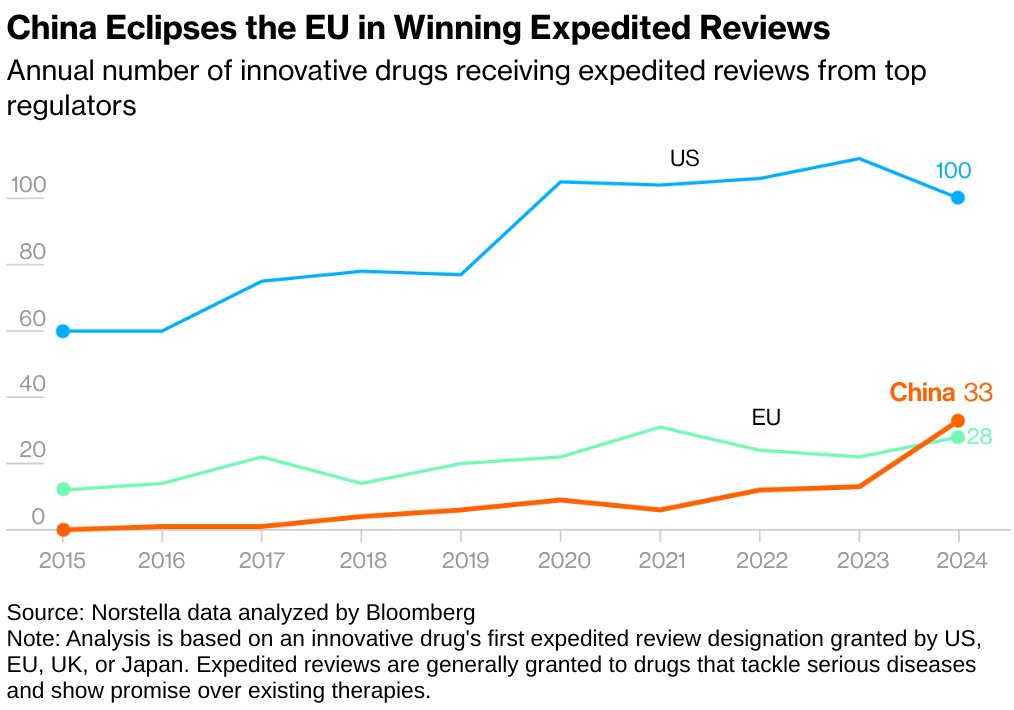
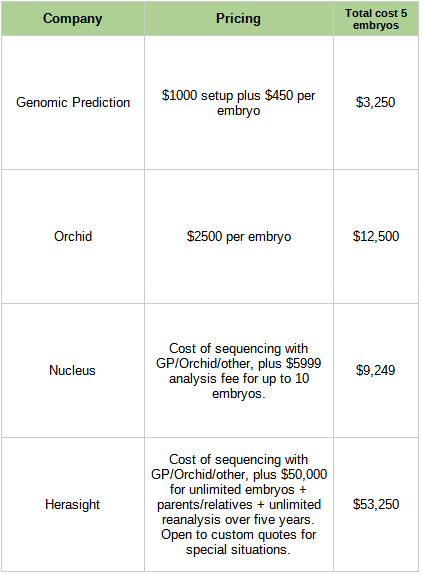Psychometry and Philip K. Dick
We have a tendency to assume that high V individuals such as famous writers or pundits or even philosophers have correspondingly high M and S (spatial) capabilities.
In the interview I link below, Dick recounts how he was forced to leave UC Berkeley because of the ROTC requirement. Despite his best efforts he could not reassemble an M1 rifle. He says that out of 1000 ROTC students he was the only one unable to do so. In his high school geometry class he received an "F-" because he had zero comprehension of the diagrams or how to think through axiomatic proofs.
In US culture a "good talker" or "convincing talker" is typically assumed to be highly intelligent across all psychometric factors. For example, such people are able to influence public policy, raise huge startup investment rounds, make geostrategic pronouncements, etc. without any additional evidence that they possess other aspects of high intelligence, necessary to understand reality at a deeper level.
Below I link to the Dick interview (relevant remarks at ~10 minutes), and a famous psychometric study of eminent scientists by Harvard professor Anne Roe that evaluated Verbal, Mathematical, and Spatial reasoning abilities. There are interesting patterns in the results. See also Lubinski and Benbow's studies of mathematically and verbally precocious individuals, identified as children.
We have a tendency to assume that high V individuals such as famous writers or pundits or even philosophers have correspondingly high M and S (spatial) capabilities.
In the interview I link below, Dick recounts how he was forced to leave UC Berkeley because of the ROTC requirement. Despite his best efforts he could not reassemble an M1 rifle. He says that out of 1000 ROTC students he was the only one unable to do so. In his high school geometry class he received an "F-" because he had zero comprehension of the diagrams or how to think through axiomatic proofs.
In US culture a "good talker" or "convincing talker" is typically assumed to be highly intelligent across all psychometric factors. For example, such people are able to influence public policy, raise huge startup investment rounds, make geostrategic pronouncements, etc. without any additional evidence that they possess other aspects of high intelligence, necessary to understand reality at a deeper level.
Below I link to the Dick interview (relevant remarks at ~10 minutes), and a famous psychometric study of eminent scientists by Harvard professor Anne Roe that evaluated Verbal, Mathematical, and Spatial reasoning abilities. There are interesting patterns in the results. See also Lubinski and Benbow's studies of mathematically and verbally precocious individuals, identified as children.
1950s study of eminent scientists by Harvard psychologist Anne Roe: The Making of a Scientist (1952). Her study is by far the most systematic and sophisticated that I am aware of. She selected 64 eminent scientists -- well known, but not quite at the Nobel level -- in a more or less random fashion, using, e.g., membership lists of scholarly organizations and expert evaluators in the particular subfields. Roughly speaking, there were three groups: physicists (divided into experimental and theoretical subgroups), biologists (including biochemists and geneticists) and social scientists (psychologists, anthropologists).
Roe devised her own high-end intelligence tests as follows: she obtained difficult problems in verbal, spatial and mathematical reasoning from the Educational Testing Service, which administers the SAT, but also performs bespoke testing research for, e.g., the US military. Using these problems, she created three tests (V, S and M), which were administered to the 64 scientists, and also to a cohort of PhD students at Columbia Teacher's College. The PhD students also took standard IQ tests and the results were used to norm the high-end VSM tests using an SD = 15. Most IQ tests are not good indicators of true high level ability (e.g., beyond +3 SD or so).
Average ages of subjects: mid-40s for physicists, somewhat older for other scientists
Overall normed scores:
Test (Low / Median / High)
V 121 / 166 / 177
S 123 / 137 / 164
M 128 / 154 / 194
Roe comments: (1) V test was too easy for some takers, so top score no ceiling. (2) S scores tend to decrease with age (correlation .4). Peak (younger) performance would have been higher. (3) M test was found to be too easy for the physicists; only administered to other groups.
It is unlikely that any single individual obtained all of the low scores, so each of the 64 would have been strongly superior in at least one or more areas.
Median scores (raw) by group:
group (V / S / M)
Biologists 56.6 / 9.4 / 16.8
Exp. Physics 46.6 / 11.7 / *
Theo. Physics 64.2 / 13.8 / *
Psychologists 57.7 / 11.3 / 15.6
Anthropologists 61.1 / 8.2 / 9.2
The lowest score in each category among the 12 theoretical physicists would have been roughly V 160 (!) S 130 M >> 150. (Ranges for all groups are given, but I'm too lazy to reproduce them here.) It is hard to estimate the M scores of the physicists since when Roe tried the test on a few of them they more or less solved every problem modulo some careless mistakes. Note the top raw scores (27 out of 30 problems solved) among the non-physicists (obtained by 2 geneticists and a psychologist), are quite high but short of a full score. The corresponding normed score is 194!
The lowest V scores in the 120-range were only obtained by 2 experimental physicists, all other scientists scored well above this level -- note the median is 166.
infoproc.blogspot.com/2008/07/annals…
en.wikipedia.org/wiki/Anne_Roe
Roe devised her own high-end intelligence tests as follows: she obtained difficult problems in verbal, spatial and mathematical reasoning from the Educational Testing Service, which administers the SAT, but also performs bespoke testing research for, e.g., the US military. Using these problems, she created three tests (V, S and M), which were administered to the 64 scientists, and also to a cohort of PhD students at Columbia Teacher's College. The PhD students also took standard IQ tests and the results were used to norm the high-end VSM tests using an SD = 15. Most IQ tests are not good indicators of true high level ability (e.g., beyond +3 SD or so).
Average ages of subjects: mid-40s for physicists, somewhat older for other scientists
Overall normed scores:
Test (Low / Median / High)
V 121 / 166 / 177
S 123 / 137 / 164
M 128 / 154 / 194
Roe comments: (1) V test was too easy for some takers, so top score no ceiling. (2) S scores tend to decrease with age (correlation .4). Peak (younger) performance would have been higher. (3) M test was found to be too easy for the physicists; only administered to other groups.
It is unlikely that any single individual obtained all of the low scores, so each of the 64 would have been strongly superior in at least one or more areas.
Median scores (raw) by group:
group (V / S / M)
Biologists 56.6 / 9.4 / 16.8
Exp. Physics 46.6 / 11.7 / *
Theo. Physics 64.2 / 13.8 / *
Psychologists 57.7 / 11.3 / 15.6
Anthropologists 61.1 / 8.2 / 9.2
The lowest score in each category among the 12 theoretical physicists would have been roughly V 160 (!) S 130 M >> 150. (Ranges for all groups are given, but I'm too lazy to reproduce them here.) It is hard to estimate the M scores of the physicists since when Roe tried the test on a few of them they more or less solved every problem modulo some careless mistakes. Note the top raw scores (27 out of 30 problems solved) among the non-physicists (obtained by 2 geneticists and a psychologist), are quite high but short of a full score. The corresponding normed score is 194!
The lowest V scores in the 120-range were only obtained by 2 experimental physicists, all other scientists scored well above this level -- note the median is 166.
infoproc.blogspot.com/2008/07/annals…
en.wikipedia.org/wiki/Anne_Roe

• • •
Missing some Tweet in this thread? You can try to
force a refresh