Kimi Linear Tech Report is dropped! 🚀
huggingface.co/moonshotai/Kim…
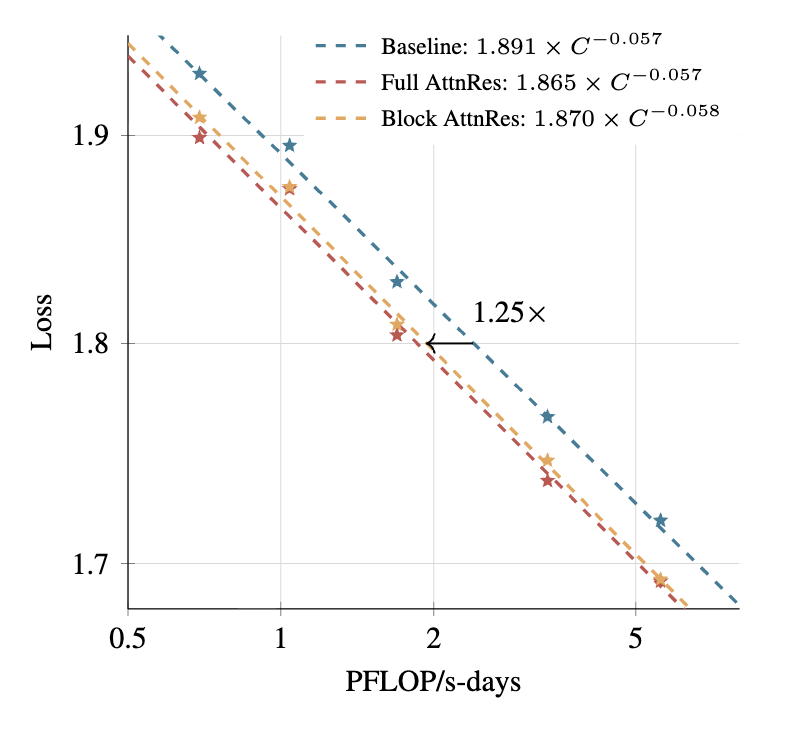
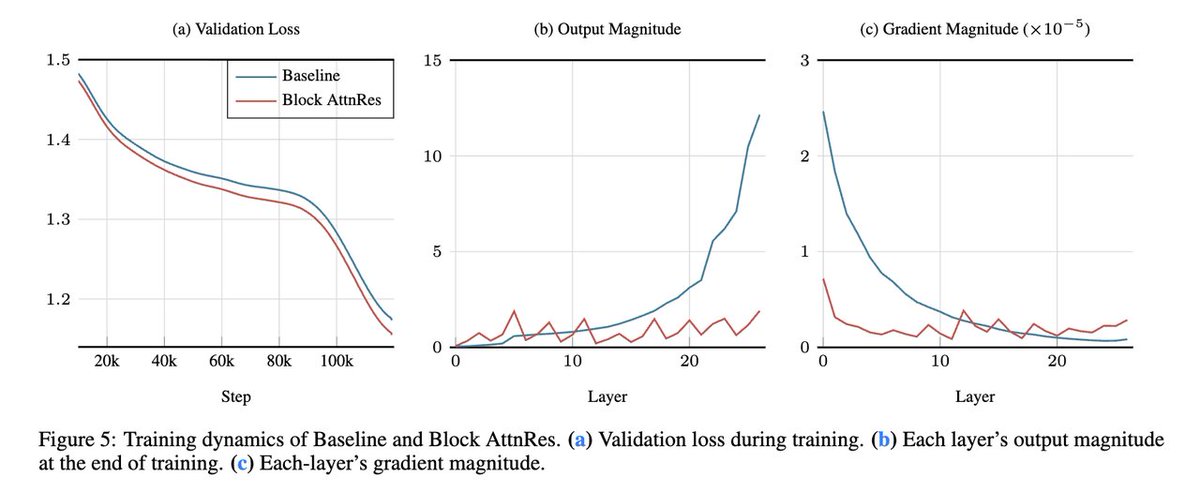
Kimi Linear: A novel architecture that outperforms full attention with faster speeds and better performance—ready to serve as a drop-in replacement for full attention, featuring our open-sourced KDA kernels! Kimi Linear offers up to a 75% reduction in KV cache usage and up to 6x decoding throughput at a 1M context length.
Key highlights:
🔹 Kimi Delta Attention: A hardware-efficient linear attention mechanism that refines the gated delta rule.
🔹 Kimi Linear Architecture: The first hybrid linear architecture to surpass pure full attention quality across the board.
🔹 Empirical Validation: Scaled, fair comparisons + open-sourced KDA kernels, vLLM integration, and checkpoints.
The future of agentic-oriented attention is here! 💡
huggingface.co/moonshotai/Kim…
Kimi Linear: A novel architecture that outperforms full attention with faster speeds and better performance—ready to serve as a drop-in replacement for full attention, featuring our open-sourced KDA kernels! Kimi Linear offers up to a 75% reduction in KV cache usage and up to 6x decoding throughput at a 1M context length.
Key highlights:
🔹 Kimi Delta Attention: A hardware-efficient linear attention mechanism that refines the gated delta rule.
🔹 Kimi Linear Architecture: The first hybrid linear architecture to surpass pure full attention quality across the board.
🔹 Empirical Validation: Scaled, fair comparisons + open-sourced KDA kernels, vLLM integration, and checkpoints.
The future of agentic-oriented attention is here! 💡
• • •
Missing some Tweet in this thread? You can try to
force a refresh