
we released Olmo 3! lot of exciting stuff but wanna focus on:
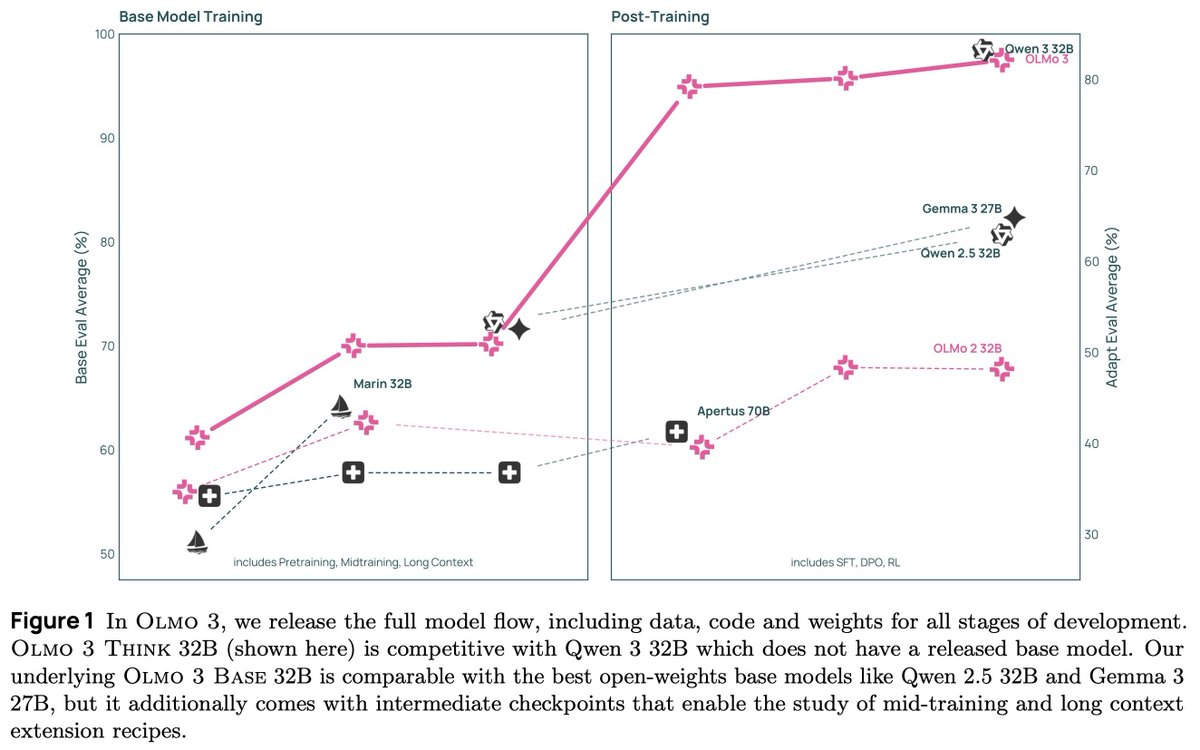
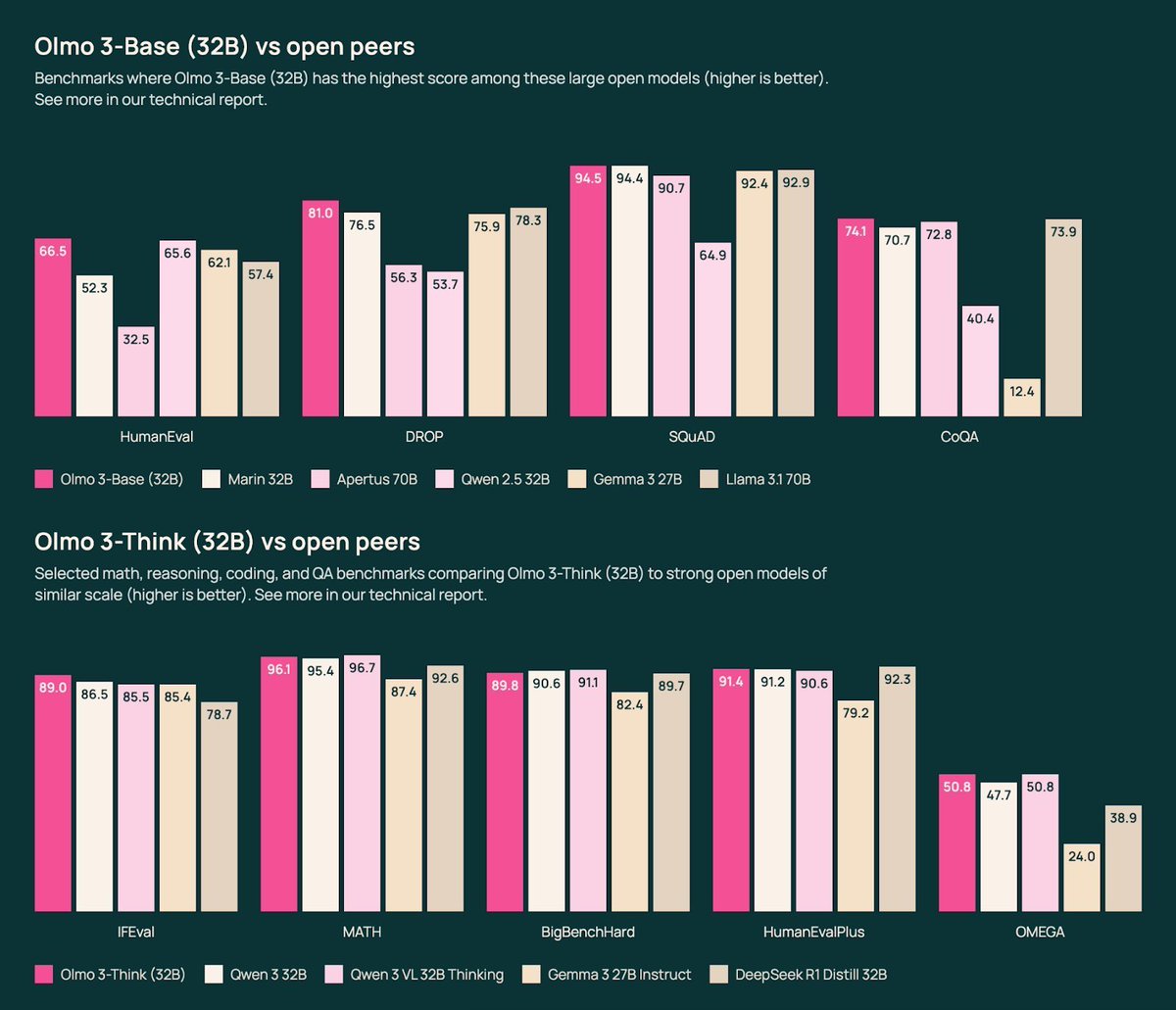
🐟Olmo 3 32B Base, the best fully-open base model to-date, near Qwen 2.5 & Gemma 3 on diverse evals
🐠Olmo 3 32B Think, first fully-open reasoning model approaching Qwen 3 levels
🐡12 training datasets corresp to different staged training recipes, all open & accessible
since I'm a pretraining person, I'll share some of my fav Base model ideas:
🐟Olmo 3 32B Base, the best fully-open base model to-date, near Qwen 2.5 & Gemma 3 on diverse evals
🐠Olmo 3 32B Think, first fully-open reasoning model approaching Qwen 3 levels
🐡12 training datasets corresp to different staged training recipes, all open & accessible
since I'm a pretraining person, I'll share some of my fav Base model ideas:
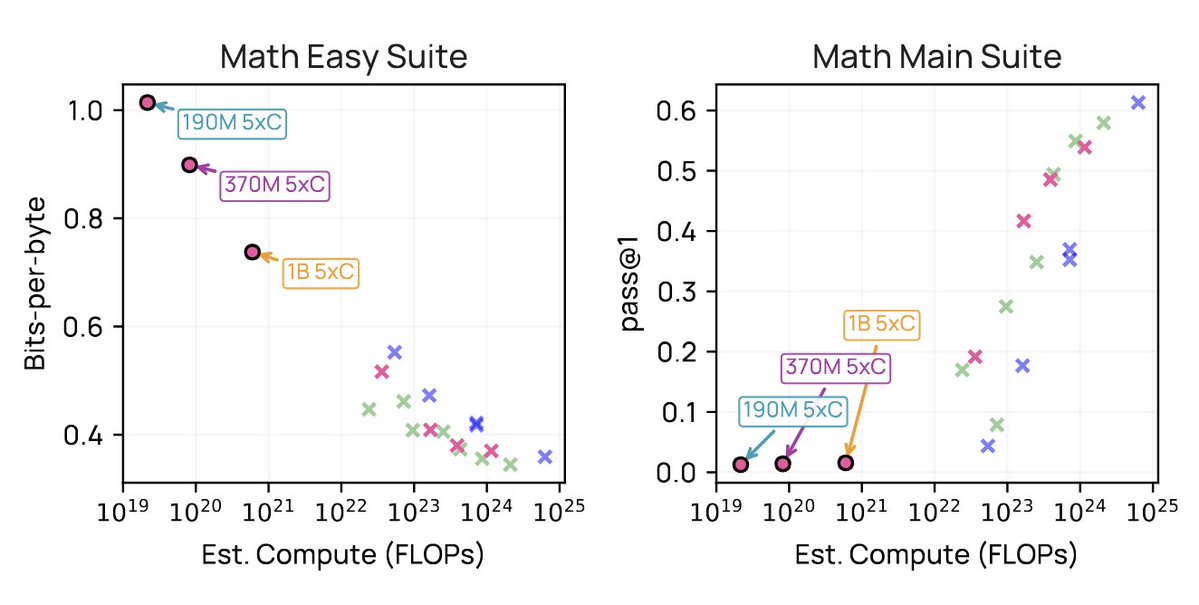
🦈Invest in your experimental design!
"Fit scaling ladders" is right, but there's more we can understand about suitability of different benchmarks for scaling experiments
We create evals better suited for different compute scales, with our "easy" set of tasks+metrics able to support very small scale experiments before switching to our "main" set of evals, on which smaller models are below noise floor
"Fit scaling ladders" is right, but there's more we can understand about suitability of different benchmarks for scaling experiments
We create evals better suited for different compute scales, with our "easy" set of tasks+metrics able to support very small scale experiments before switching to our "main" set of evals, on which smaller models are below noise floor
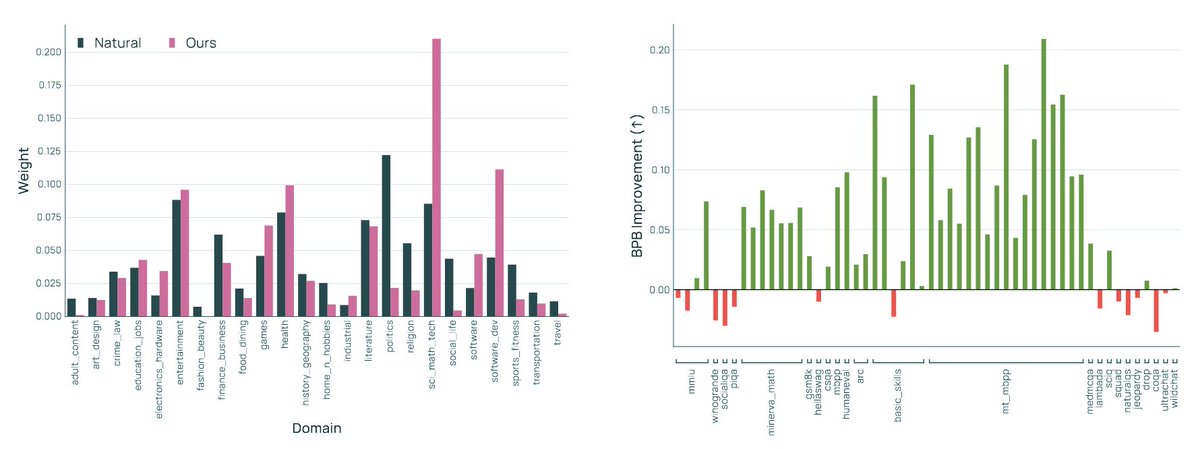
🍣Data mixing is a little too powerful
It's really easy to accidentally learn "optimal" mixes that oversample from certain pockets heavily. For example, "STEM" docs are really valuable for climbing tasks like MMLU & mixing methods can propose very high weight.
But realistically, you don't have infinite "STEM" docs. Upsampling is fine but only up to an extent, after which, you may actually benefit more from sampling new docs that aren't the "best" but still "good"
We approach mixing as a Token Constrained Optimization problem & further penalize any solution that tanks any one individual task too hard
It's really easy to accidentally learn "optimal" mixes that oversample from certain pockets heavily. For example, "STEM" docs are really valuable for climbing tasks like MMLU & mixing methods can propose very high weight.
But realistically, you don't have infinite "STEM" docs. Upsampling is fine but only up to an extent, after which, you may actually benefit more from sampling new docs that aren't the "best" but still "good"
We approach mixing as a Token Constrained Optimization problem & further penalize any solution that tanks any one individual task too hard
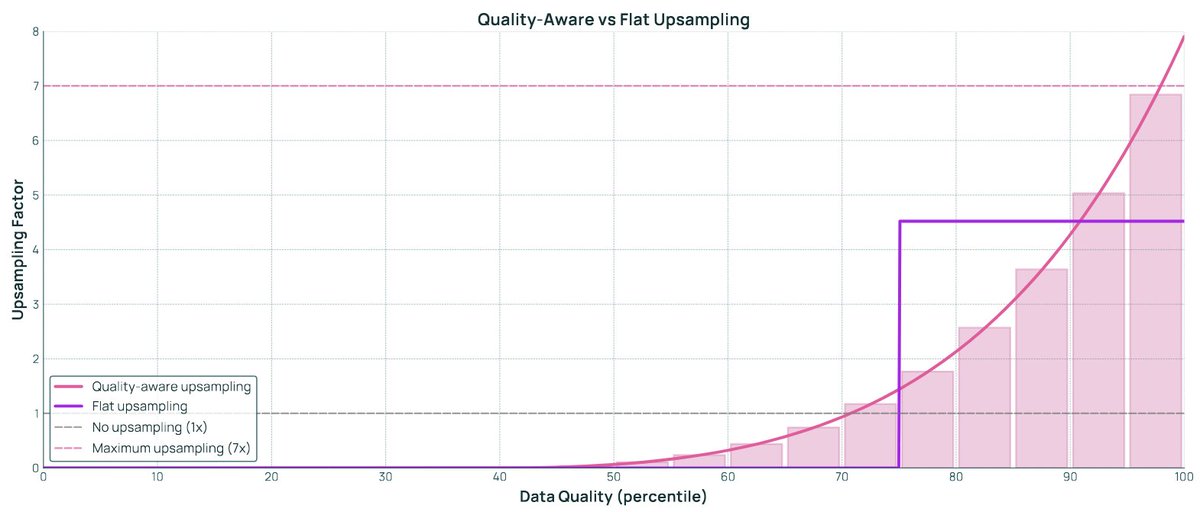
🍨Data quality signals matter but also how you use them!
Traditional ways of using data quality is to threshold: Define a cutoff and take all the documents above that threshold.
But why not sample *proportional* to data quality?
We use Quality-Aware Upsampling to do exactly this. Super simple idea and it works really well!
Traditional ways of using data quality is to threshold: Define a cutoff and take all the documents above that threshold.
But why not sample *proportional* to data quality?
We use Quality-Aware Upsampling to do exactly this. Super simple idea and it works really well!
🍕Finally, we all know midtraining is an exciting time to get a ton of performance boost
But the midtraining development loop kind of sucks. It's exhausting to hunt for problems in the model, create specific data that patches it, and retrain, over and over.
Team organization to sustain consistent model improvements (without burnout) is important. We had different teammates "own" target capabilities to reduce thrash & a centralized assessment team define experimental methodology & eval standards.
Explorers would try things in distributed manner, propose best ideas back (with evidence). And the team defines and conducts regular "integration tests" where we combine ideas and see if they work together. If so, it's the new baseline to beat & everyone goes exploring again!
But the midtraining development loop kind of sucks. It's exhausting to hunt for problems in the model, create specific data that patches it, and retrain, over and over.
Team organization to sustain consistent model improvements (without burnout) is important. We had different teammates "own" target capabilities to reduce thrash & a centralized assessment team define experimental methodology & eval standards.
Explorers would try things in distributed manner, propose best ideas back (with evidence). And the team defines and conducts regular "integration tests" where we combine ideas and see if they work together. If so, it's the new baseline to beat & everyone goes exploring again!

🍏Try the model: playground.allenai.org
🍍Download the collection: huggingface.co/collections/al…
🍌Read the blog: allenai.org/blog/olmo3
🍎And our 100+ page paper lol 🤪: datocms-assets.com/64837/17636468…
more linked from the Ai2 post x.com/allen_ai/statu…
🍍Download the collection: huggingface.co/collections/al…
🍌Read the blog: allenai.org/blog/olmo3
🍎And our 100+ page paper lol 🤪: datocms-assets.com/64837/17636468…
more linked from the Ai2 post x.com/allen_ai/statu…
We're hiring too!
Olmo 3 was our biggest effort yet, but we're still a small team (67 authors!) compared to a lot of the big labs, which means everyone gets to own a major piece of the Olmo puzzle.
In particular, we're hiring student interns who have been critical to our project's success. So if you're interested in doing research with us + contribute to open science + get enthusiastic support to publish your work, hope to see you apply:
job-boards.greenhouse.io/thealleninstit…
Olmo 3 was our biggest effort yet, but we're still a small team (67 authors!) compared to a lot of the big labs, which means everyone gets to own a major piece of the Olmo puzzle.
In particular, we're hiring student interns who have been critical to our project's success. So if you're interested in doing research with us + contribute to open science + get enthusiastic support to publish your work, hope to see you apply:
job-boards.greenhouse.io/thealleninstit…
• • •
Missing some Tweet in this thread? You can try to
force a refresh



