
Last week the @FFmpeg account began taunting security researchers. Foolish thing to do, as it ignores the asymmetry of their attack surface vs ours.
So as an exercise I found a stack-based buffer overflow on software that he wrote. Took me ~20 mins to find it. Thread 🧵(1/5)
So as an exercise I found a stack-based buffer overflow on software that he wrote. Took me ~20 mins to find it. Thread 🧵(1/5)
First, I noticed the FFMpeg account is not controlled by an active developer of FFMpeg, but apparently by several guys, one of them named Keiran. Weird, but it is not important.
The keirank github user has very few commits, and none on FFMPEG, but Upipe, a video processing software from his company.
So lets check his most recent commit "Validate num_delta_pocs to avoid a stack smash". (2/5)
The keirank github user has very few commits, and none on FFMPEG, but Upipe, a video processing software from his company.
So lets check his most recent commit "Validate num_delta_pocs to avoid a stack smash". (2/5)
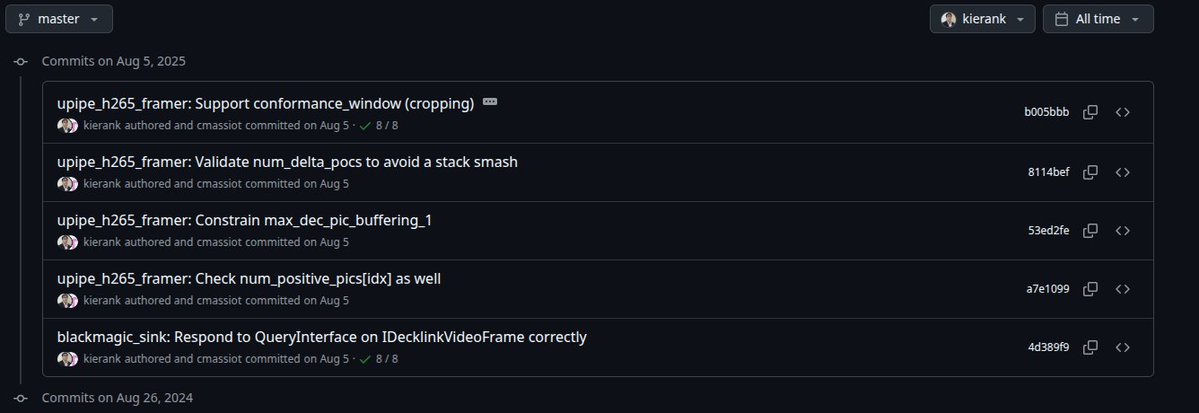
@FFmpeg Indeed @FFmpeg wrote a validation, but it only checks one index despite working with two-dimensional arrays of varying dimensions.
This cannot be right. Since I didn't have time to verify it , I instructed a LLM to "Find critical bugs on the code"
GLM 4.6 found many (3/5)
This cannot be right. Since I didn't have time to verify it , I instructed a LLM to "Find critical bugs on the code"
GLM 4.6 found many (3/5)
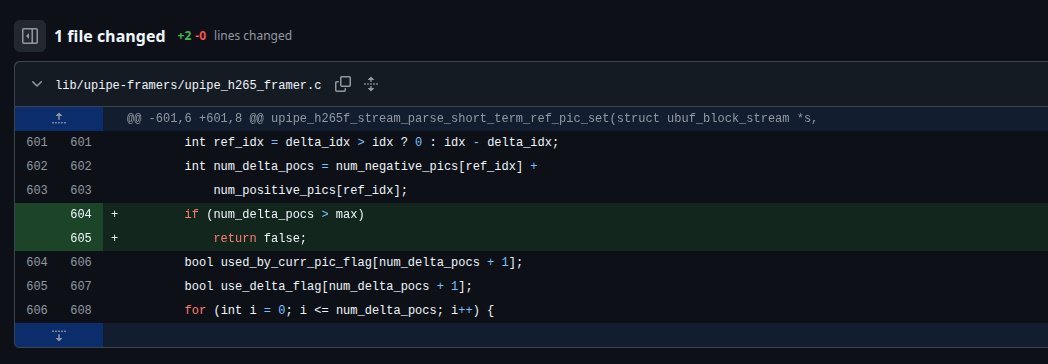
Each time a predictor frame is calculated, it increases the reference pic array, but this is not taken into account in the validations.
Overflow (overread).
So we have a way to over-read up to 64 bytes from the stack (64 being the max amount of reference frames).
But can we write in the stack? I ask the LLM to write a h265 framer fuzzer, it's very complex, nevertheless, it does it in one-shot (4/5)
Overflow (overread).
So we have a way to over-read up to 64 bytes from the stack (64 being the max amount of reference frames).
But can we write in the stack? I ask the LLM to write a h265 framer fuzzer, it's very complex, nevertheless, it does it in one-shot (4/5)
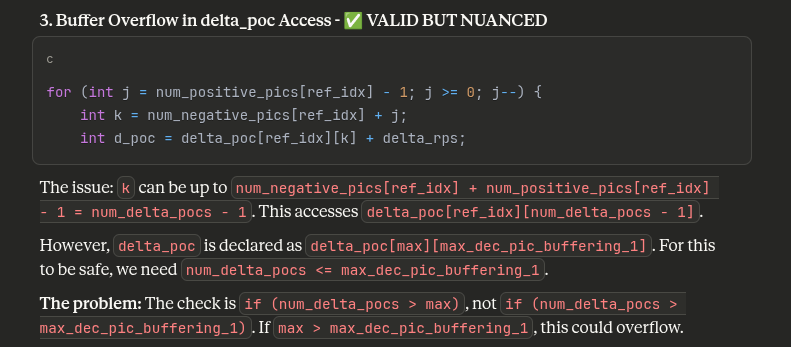
@FFmpeg So now we have read/write stack-based buffer overflow. Game over.
Fuzzer and complete explanation can be found on my github:
github.com/ortegaalfredo/…
Fuzzer and complete explanation can be found on my github:
github.com/ortegaalfredo/…
• • •
Missing some Tweet in this thread? You can try to
force a refresh




