This is one of the most insane things Nano Banana Pro 🍌 can do.
It can reproduce figures with mind-blowing precision.
No competition in this regard!
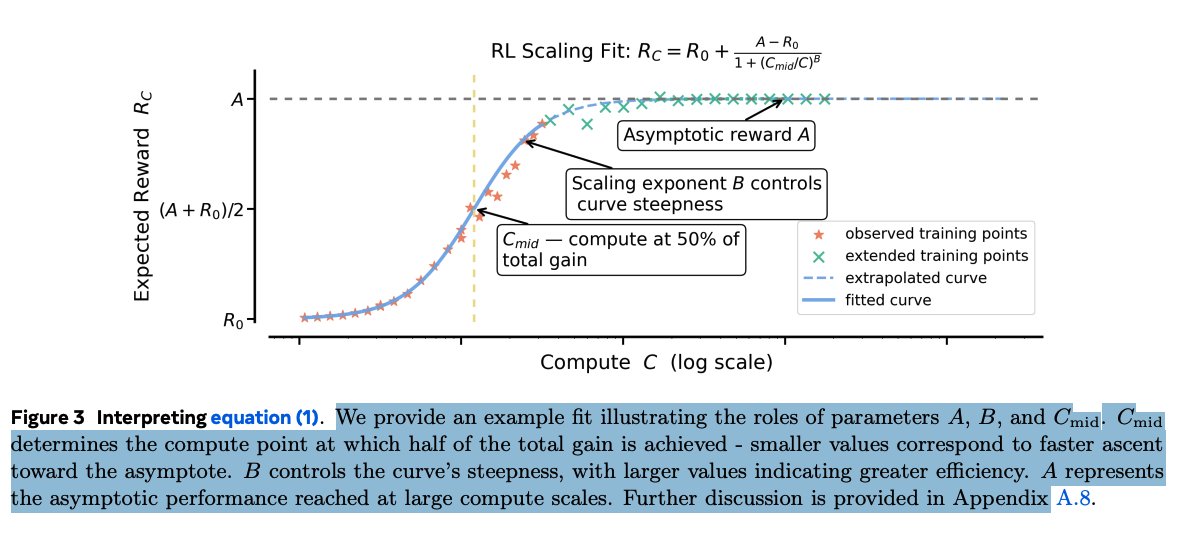
Prompt: "Please reproduce this chart in high quality and fidelity and offer annotated labels to better understand it."
It can reproduce figures with mind-blowing precision.
No competition in this regard!
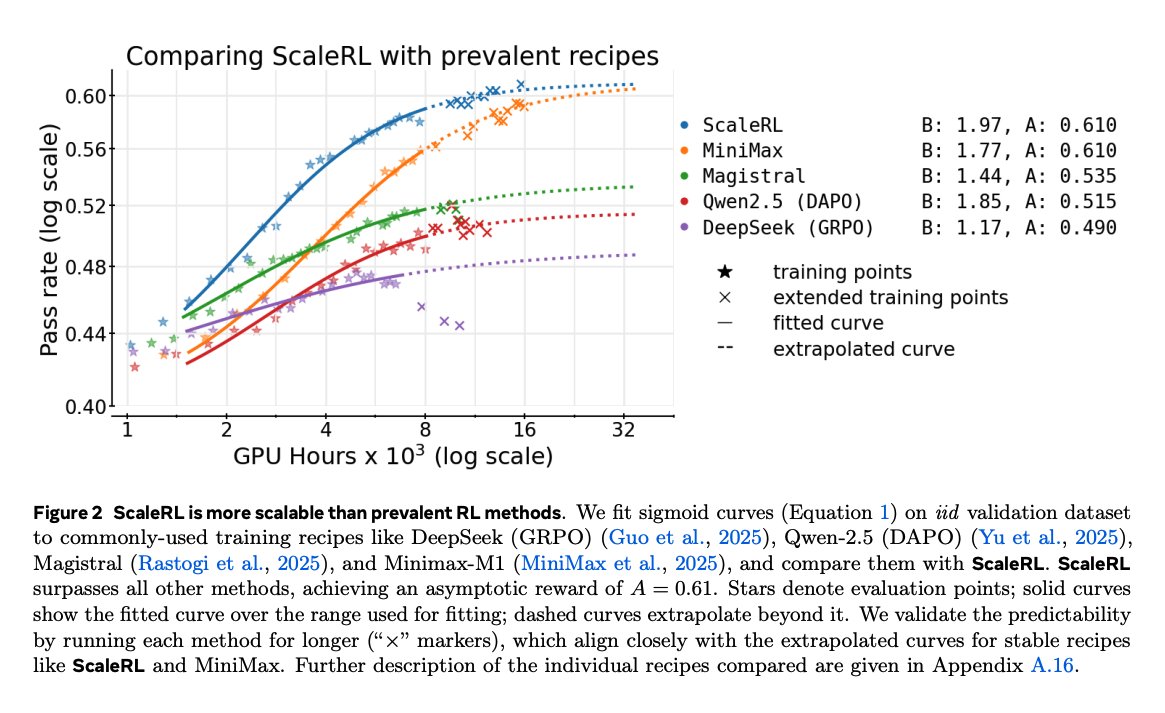
Prompt: "Please reproduce this chart in high quality and fidelity and offer annotated labels to better understand it."

When I tried this for the first time, I didn't expect that this was possible.
The level of understanding this requires is what's remarkable about it all.
The levels of personalization this unlocks are also impressive.
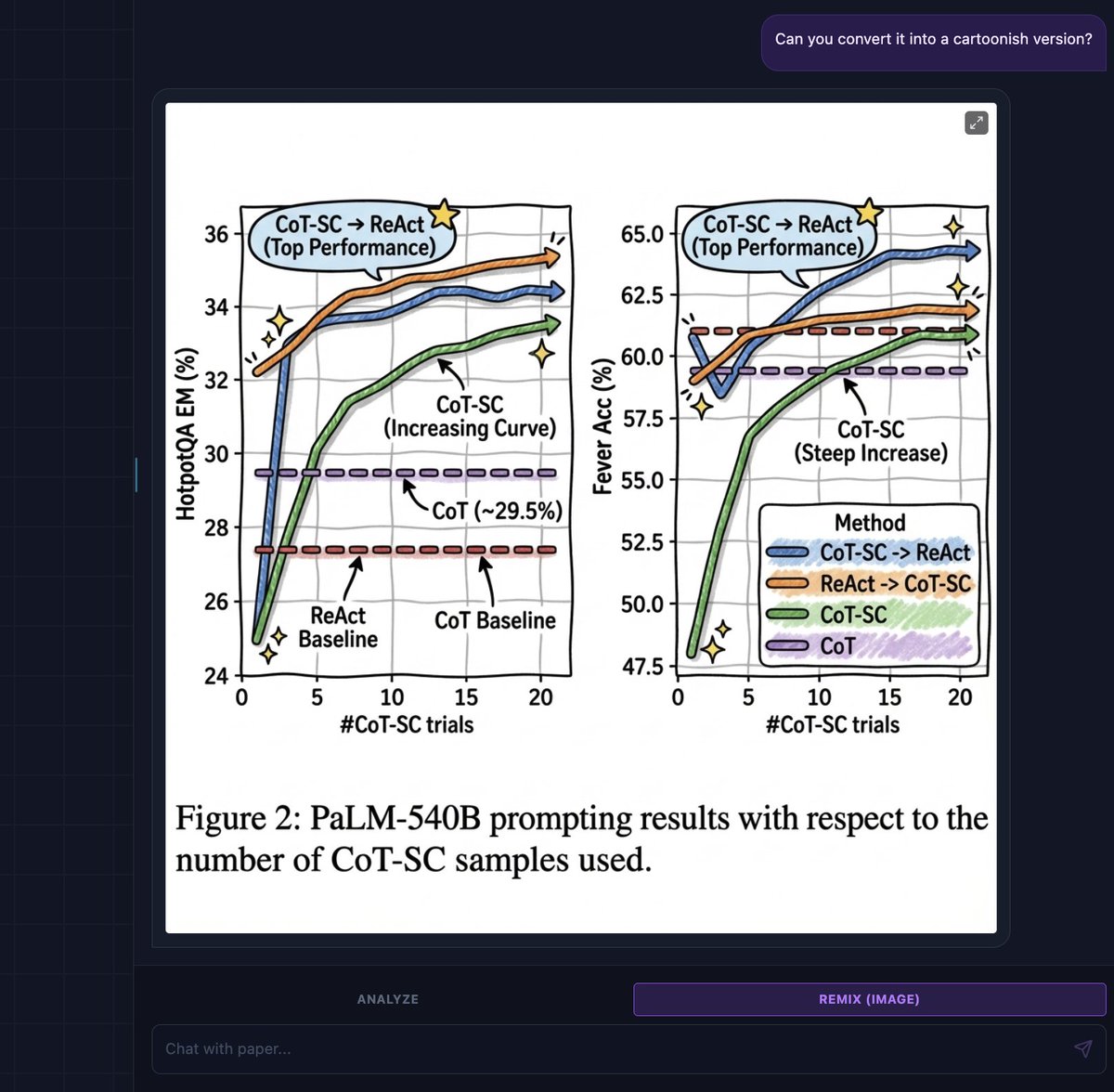
"Can you convert it into a cartoonish version?"
The level of understanding this requires is what's remarkable about it all.
The levels of personalization this unlocks are also impressive.
"Can you convert it into a cartoonish version?"
Just look at this 🤯
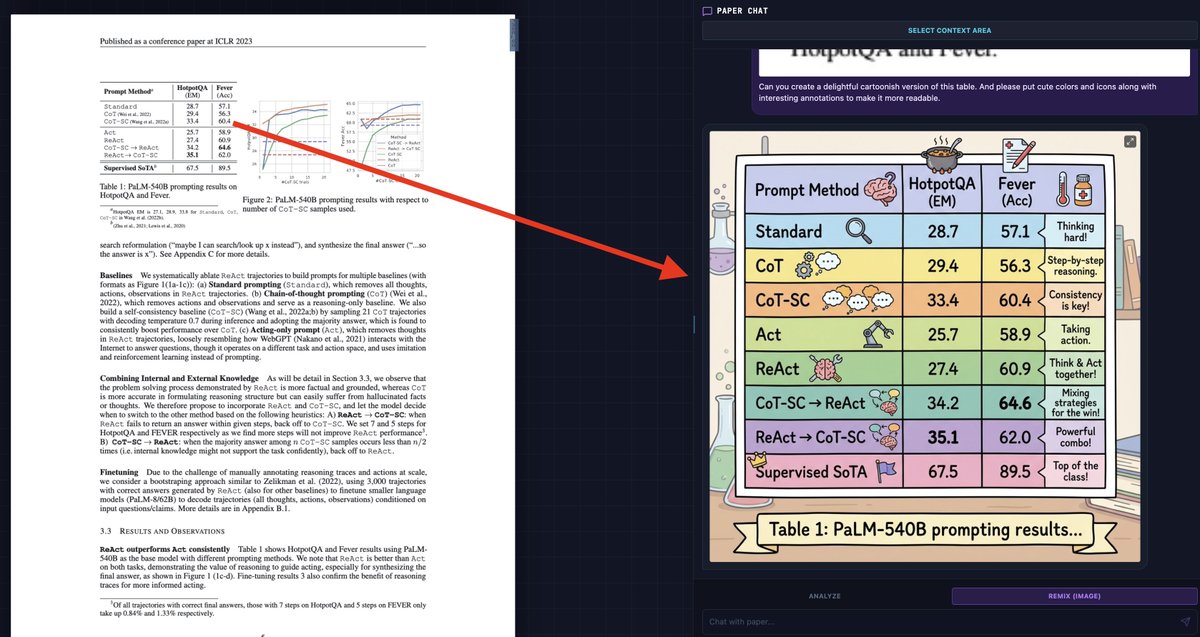
"Can you create a delightful cartoonish version of this table. And please put cute colors and icons along with interesting annotations to make it more readable."
"Can you create a delightful cartoonish version of this table. And please put cute colors and icons along with interesting annotations to make it more readable."
Try it yourself: …dair-ai-181664986325.us-west1.run.app
Addictive!
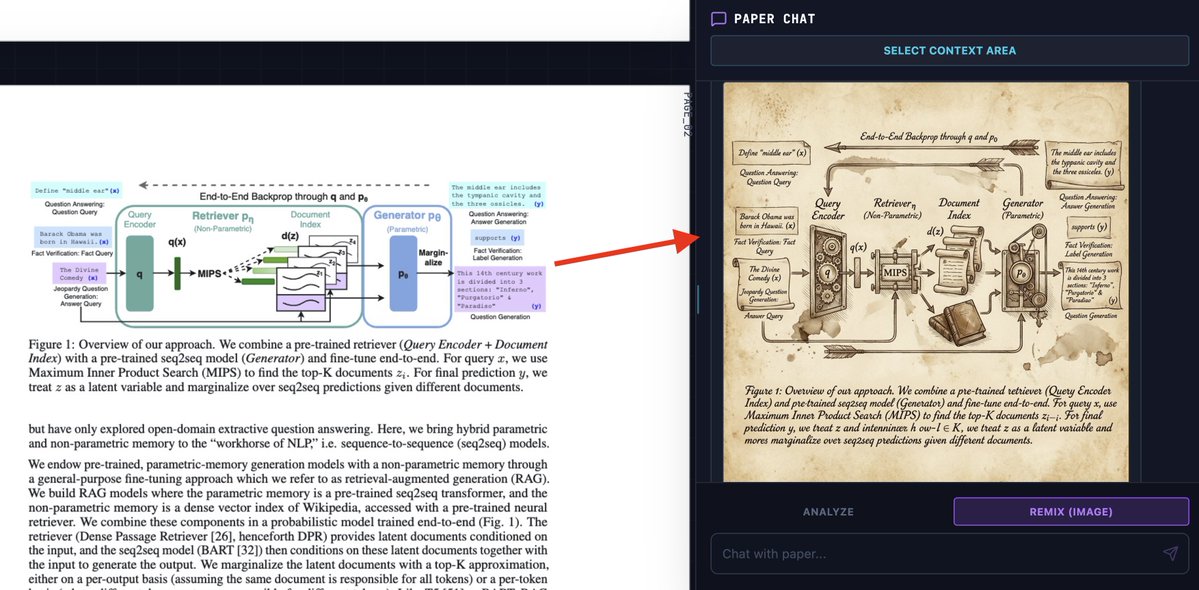
"Bring this figure to life by creating a detailed graphic that helps understand its inner workings. Use Leonardo Davinci sketch style."
"Bring this figure to life by creating a detailed graphic that helps understand its inner workings. Use Leonardo Davinci sketch style."
More creative applications.
"These equations are scary. Can you please create a detailed infographic breaking it down and explaining in layman's terms what's happening and most importantly what it solves or does?"
Great for creating posters.
"These equations are scary. Can you please create a detailed infographic breaking it down and explaining in layman's terms what's happening and most importantly what it solves or does?"
Great for creating posters.

• • •
Missing some Tweet in this thread? You can try to
force a refresh