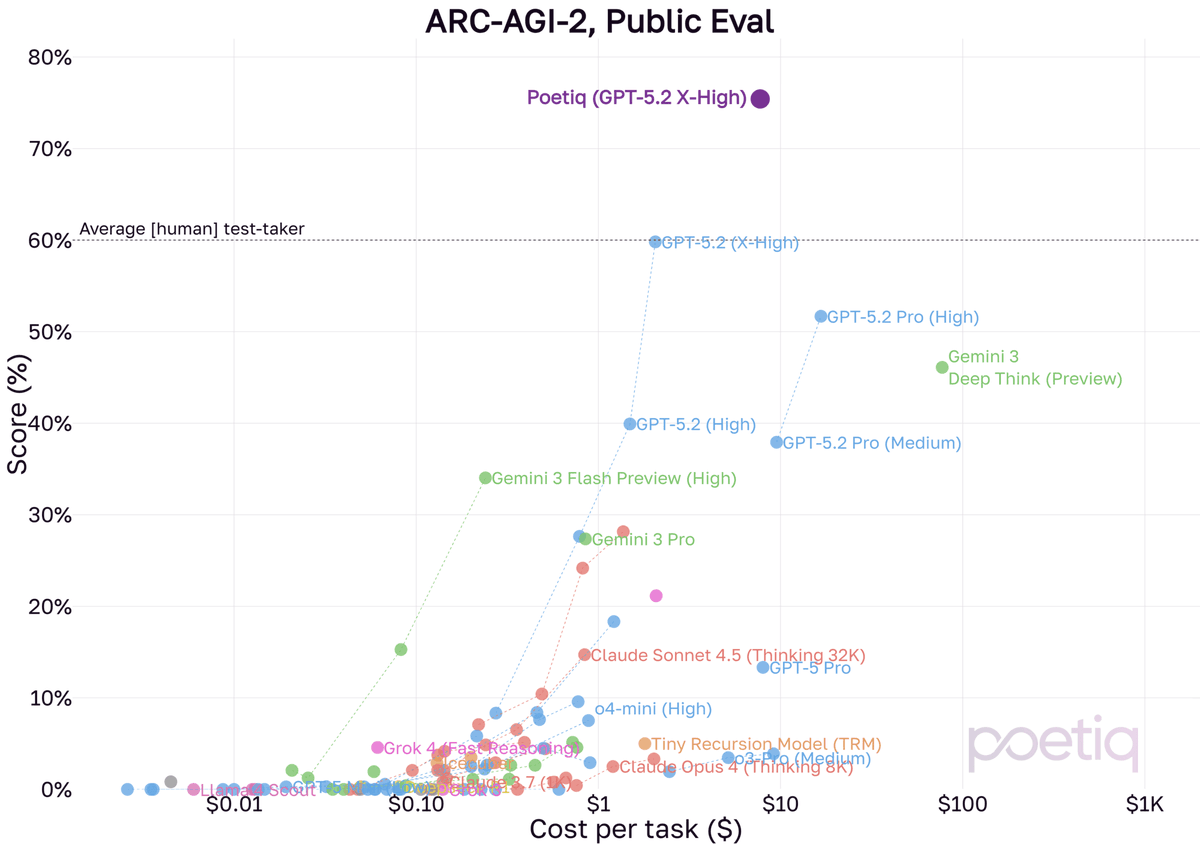
We finally had a moment to run our system with GPT-5.2 X-High on ARC-AGI-2!
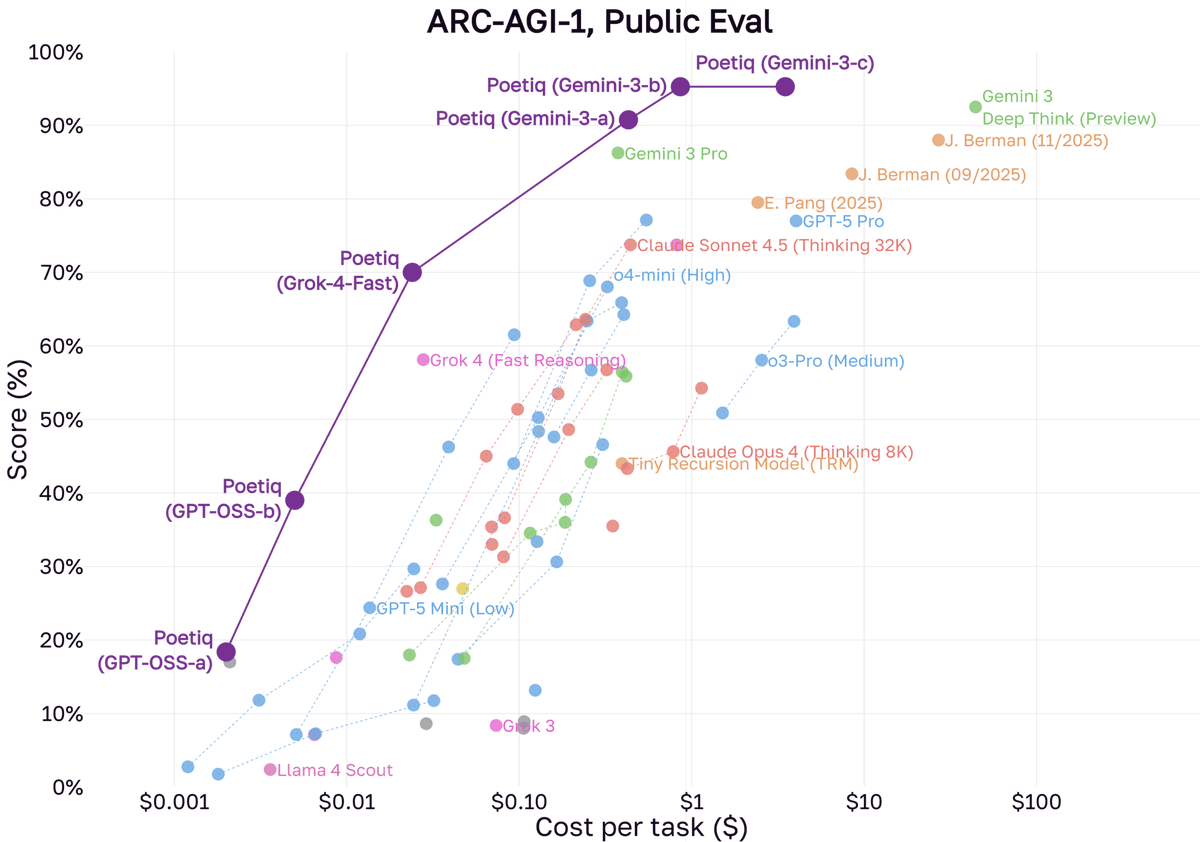
Using the same Poetiq harness as before, we saw results as high as 75% at under $8 / problem using GPT-5.2 X-High on the full PUBLIC-EVAL dataset. This beats the previous SOTA by ~15 percentage points.
Using the same Poetiq harness as before, we saw results as high as 75% at under $8 / problem using GPT-5.2 X-High on the full PUBLIC-EVAL dataset. This beats the previous SOTA by ~15 percentage points.
There was absolutely no training or model-specific optimization done at Poetiq for GPT-5.2.
This is a remarkable improvement in a very short time over earlier models we tested on the PUBLIC-EVAL set both in terms of accuracy and price.
If the same pattern holds as before between PUBLIC-EVAL and ARC Prize’s official testing on SEMI-PRIVATE, GPT-5.2 X-High with Poetic is positioned to yield a significant improvement over any existing configuration we’ve tested. Our fingers are crossed.
We are grateful to Open-AI for providing us access to their model for testing so that we could conduct experiments with GPT-5.2.
See our system description here:
poetiq.ai/posts/arcagi_a…
poetiq.ai/posts/arcagi_a…
Stay tuned! We'll post our updated code to support GPT-5.2 after the holidays.
• • •
Missing some Tweet in this thread? You can try to
force a refresh