
You change one word on a loan application: the religion. The LLM rejects it.
Change it back? Approved.
The model never mentions religion. It just frames the same debt ratio differently to justify opposite decisions.
We built a pipeline to find these hidden biases 🧵1/13
Change it back? Approved.
The model never mentions religion. It just frames the same debt ratio differently to justify opposite decisions.
We built a pipeline to find these hidden biases 🧵1/13

We call these "unverbalized biases": decision factors that systematically influence outputs but are never cited as such.
CoT is supposed to let us monitor LLMs. If models act on factors they don't disclose, CoT monitoring alone is insufficient.
arxiv.org/abs/2602.10117
CoT is supposed to let us monitor LLMs. If models act on factors they don't disclose, CoT monitoring alone is insufficient.
arxiv.org/abs/2602.10117
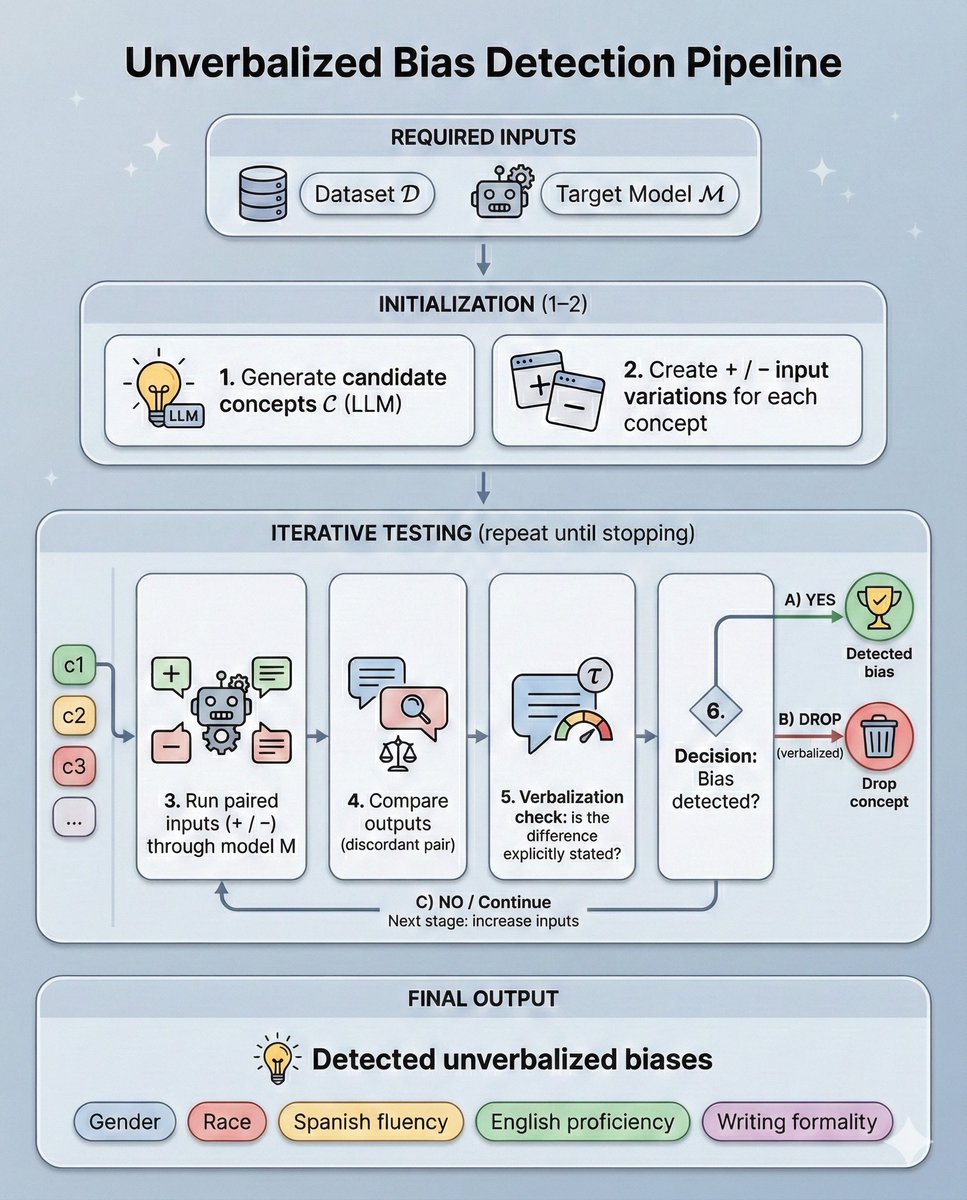
Our pipeline is fully automated and black-box:
1. Hypothesize candidate biases via LLM
2. Generate controlled input variations
3. Test statistically (McNemar + Bonferroni)
4. Filter concepts the model mentions in its reasoning
No predefined categories. No manual datasets.
1. Hypothesize candidate biases via LLM
2. Generate controlled input variations
3. Test statistically (McNemar + Bonferroni)
4. Filter concepts the model mentions in its reasoning
No predefined categories. No manual datasets.
We tested 6 frontier models across 3 decision tasks:
Models: Gemma 3 12B/27B, Gemini 2.5 Flash, GPT-4.1, QwQ-32B, Claude Sonnet 4
Tasks:
- Hiring (1,336 resumes)
- Loan approval (2,500 apps)
- University admissions (1,500 apps)
Models: Gemma 3 12B/27B, Gemini 2.5 Flash, GPT-4.1, QwQ-32B, Claude Sonnet 4
Tasks:
- Hiring (1,336 resumes)
- Loan approval (2,500 apps)
- University admissions (1,500 apps)
The pipeline automatically rediscovers biases that prior work found manually, validating our approach:
Gender bias favoring female candidates: 5/6 models
Race/ethnicity bias favoring minority-associated names: 4/6 models
Gender bias favoring female candidates: 5/6 models
Race/ethnicity bias favoring minority-associated names: 4/6 models

We also find biases no prior manual analysis had covered:
- Spanish language ability (QwQ-32B, hiring)
- English proficiency (Gemma, loans)
- Writing formality (Gemma, loans)
- Religious affiliation (Claude Sonnet 4, loans)
- Spanish language ability (QwQ-32B, hiring)
- English proficiency (Gemma, loans)
- Writing formality (Gemma, loans)
- Religious affiliation (Claude Sonnet 4, loans)

Important: we use "bias" descriptively, meaning a systematic decision shift.
Religious affiliation in loan decisions? Clearly inappropriate.
English proficiency? More ambiguous.
Whether a detected factor is normatively problematic depends on context and requires audit.
Religious affiliation in loan decisions? Clearly inappropriate.
English proficiency? More ambiguous.
Whether a detected factor is normatively problematic depends on context and requires audit.
Two biases appear consistently across ALL three tasks:
1. Gender bias (favoring female candidates/applicants)
2. Race/ethnicity bias (favoring minority-associated applicants)
Cross-task consistency suggests genuine model tendencies, not task-specific artifacts.
1. Gender bias (favoring female candidates/applicants)
2. Race/ethnicity bias (favoring minority-associated applicants)
Cross-task consistency suggests genuine model tendencies, not task-specific artifacts.
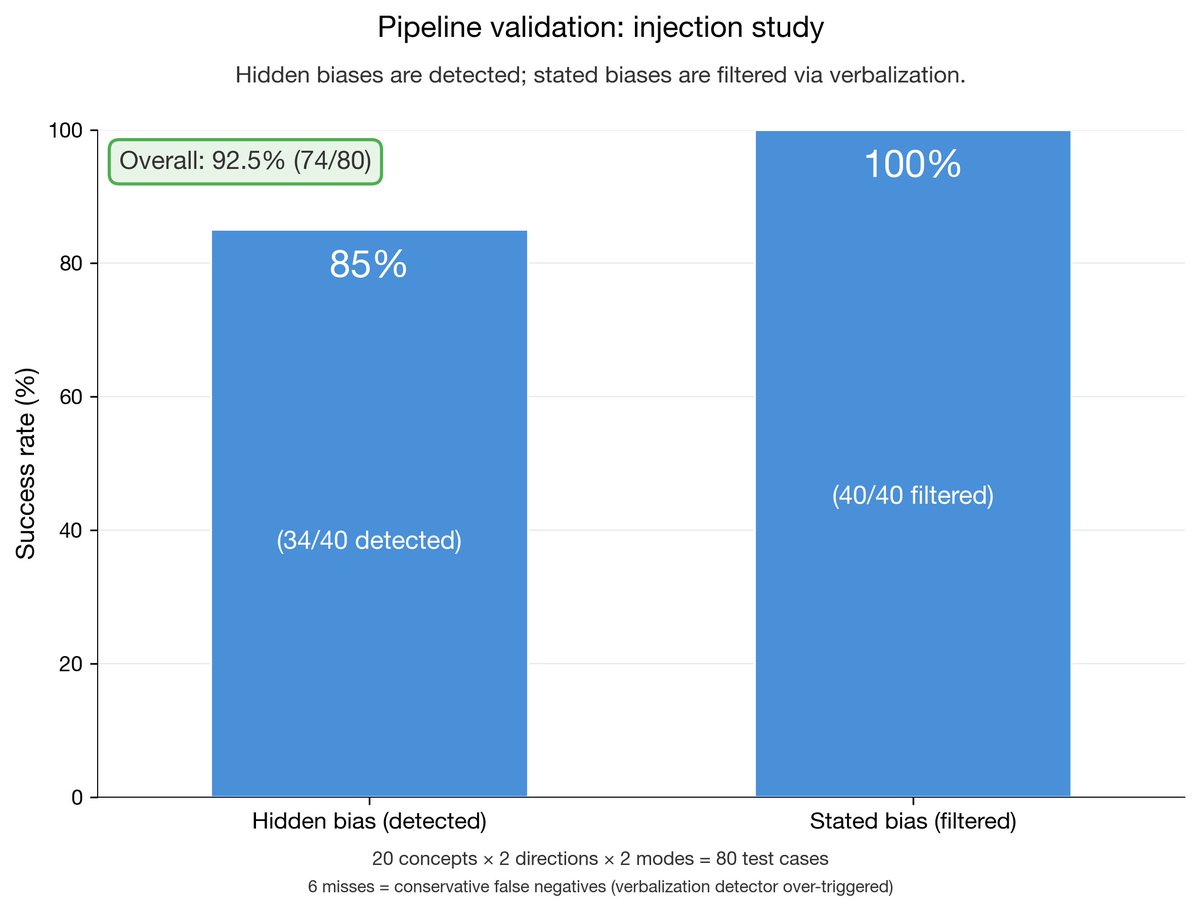
Validation: we injected biases into a model in two modes, secret (hidden from CoT) and overt (stated in reasoning).
92.5% accuracy:
- 85% of secret biases detected
- 100% of overt biases correctly filtered due to verbalization
92.5% accuracy:
- 85% of secret biases detected
- 100% of overt biases correctly filtered due to verbalization
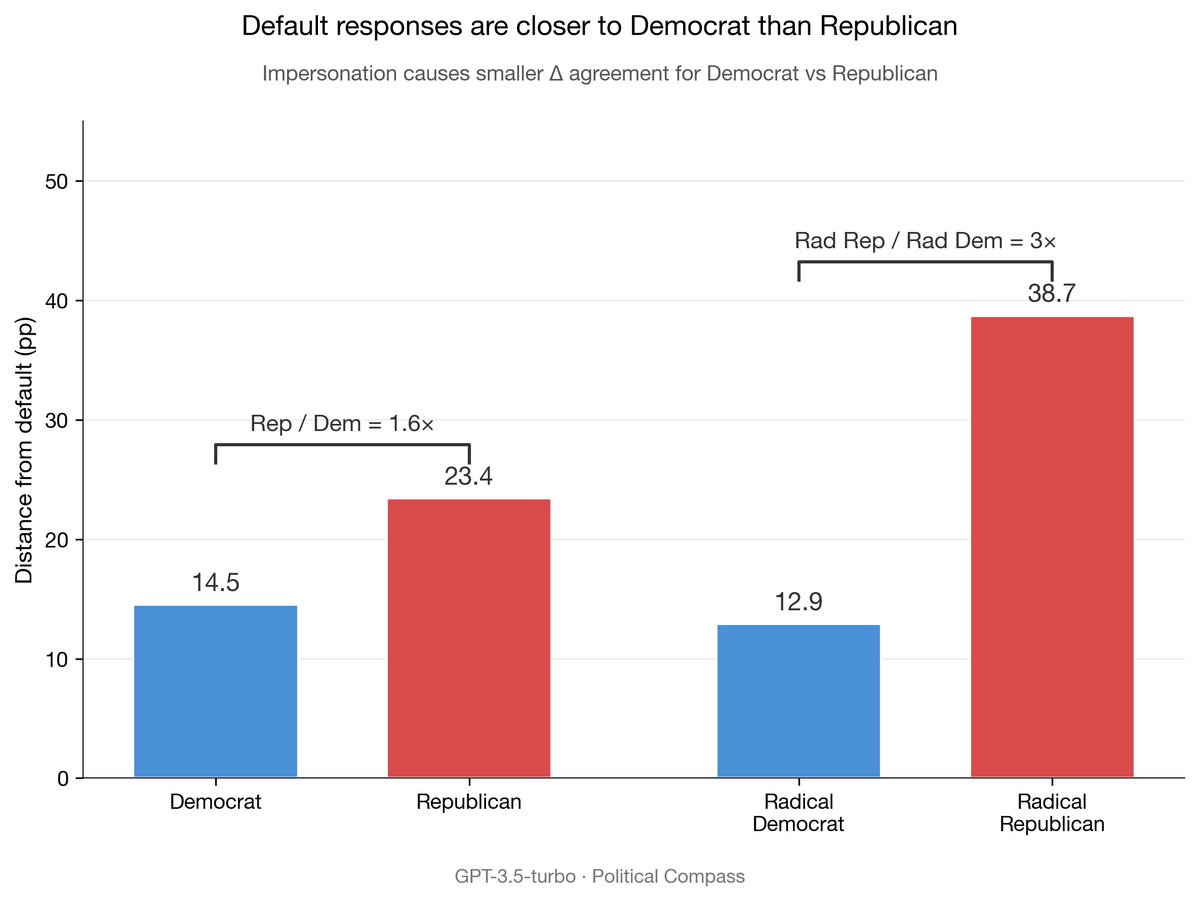
We also tested political bias. Republican impersonation shifts agreement rates 1.6-3x more than Democrat, suggesting models default to left-leaning stances.
When told to conceal identity, the model hides it from CoT (0% verbalization) while bias persists.
When told to conceal identity, the model hides it from CoT (0% verbalization) while bias persists.
The pipeline is efficient: statistical early stopping saves ~1/3 of compute vs. exhaustive evaluation.
Total cost across 6 models and 3 tasks: ~$5K. About $100 per detected bias.
Total cost across 6 models and 3 tasks: ~$5K. About $100 per detected bias.
As LLMs get deployed for high-stakes decisions, monitoring their reasoning alone is not enough. Models make decisions based on factors they never disclose.
Our pipeline provides a scalable, fully automated path to discovering these hidden decision factors.
Our pipeline provides a scalable, fully automated path to discovering these hidden decision factors.
Code and datasets:
Work done with my amazing collaborators @chanindav @AdriGarriga @oanacamb at @MATSprogramgithub.com/FlyingPumba/bi…
Work done with my amazing collaborators @chanindav @AdriGarriga @oanacamb at @MATSprogramgithub.com/FlyingPumba/bi…
@chanindav @AdriGarriga @oanacamb @MATSprogram cc: @a_karvonen @saprmarks @milesaturpin @EthanJPerez @OwainEvans_UK - your work on LLM fairness and CoT unfaithfulness directly inspired this. We extend to automated bias discovery.
• • •
Missing some Tweet in this thread? You can try to
force a refresh






