New paper on a long-shot I've been obsessed with for a year:
How much are AI reasoning gains confounded by expanding the training corpus 10000x? How much LLM performance is down to "local" generalisation (pattern-matching to hard-to-detect semantically equivalent training data)?
How much are AI reasoning gains confounded by expanding the training corpus 10000x? How much LLM performance is down to "local" generalisation (pattern-matching to hard-to-detect semantically equivalent training data)?

tl;dr
* OLMo 3 training corpus contains exact duplicates of 50% of the ZebraLogic test set.
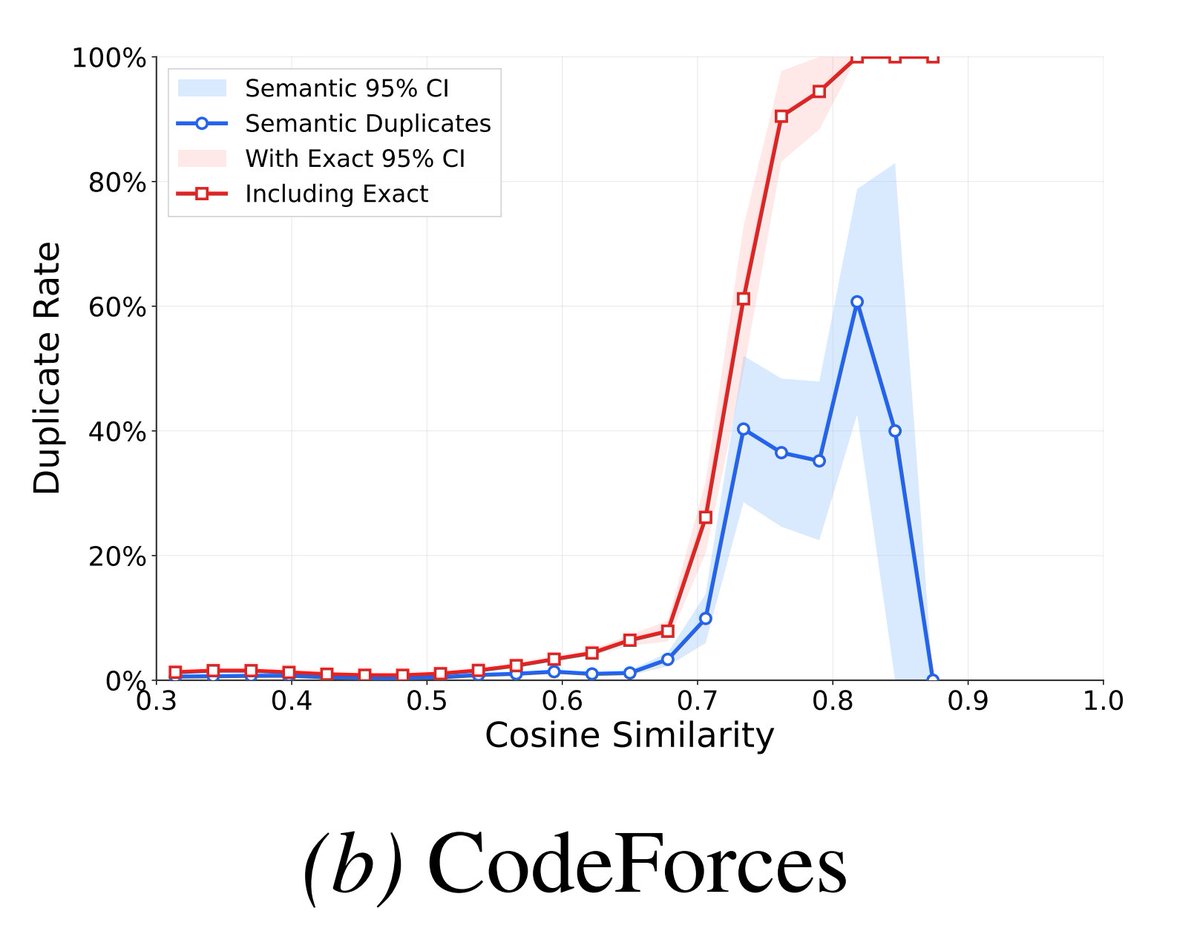
* We embed the corpus to find semantic duplicates of test data in the wild. 78% of the CodeForces test set had >=1 semantic duplicate
* The semantic duplicate rate is maybe >4 in 10000
* OLMo 3 training corpus contains exact duplicates of 50% of the ZebraLogic test set.
* We embed the corpus to find semantic duplicates of test data in the wild. 78% of the CodeForces test set had >=1 semantic duplicate
* The semantic duplicate rate is maybe >4 in 10000
Imagine you're head of training at at OpenAI, and you want your benchmark scores to be meaningful (: to estimate OOD performance)
You have a hard task ahead of you! Your models have seen so much, memorisation is so easy - as is *local generalisation* (noisy pattern-matching).
You have a hard task ahead of you! Your models have seen so much, memorisation is so easy - as is *local generalisation* (noisy pattern-matching).
What can you do? Well, obviously you take every benchmark you're going to test on and try to "decontaminate" your training corpus (remove test data from the training data).
By default this is just one level above string matching ("n-gram matching" - if sentences overlap in (say) a 13-token window, remove them from the training corpus).
But you're actually trying, so you also translate the test sets and delete translations of test from train.
But you're actually trying, so you also translate the test sets and delete translations of test from train.
But! every piece of test data has an arbitrary number of logical equivalents and neighbours (like how `x + y = 10` is the same problem as `2x + 2y = 20`). And LLMs are amazing at semantic search, so maybe this inflates benchmark scores.
The cutting-edge tech for detecting these "semantic" duplicates is... an LLM. But you simply can't do 100T x 1M calls. There's not enough compute in the world (yet).
So you do what you can - maybe you
* categorise the entire corpus & do intense search inside relevant partitions (e.g. maths > number theory > ...)
* embed the whole corpus & look for things really close to test data
* train a wee 300M filter model & do what you can with that
* categorise the entire corpus & do intense search inside relevant partitions (e.g. maths > number theory > ...)
* embed the whole corpus & look for things really close to test data
* train a wee 300M filter model & do what you can with that
How much does this process catch? How many semantic duplicates of test data slip through? And what's the impact on final benchmark scores?
We don't know, This (finally) is where our paper comes in:
We don't know, This (finally) is where our paper comes in:
We experiment on OLMo 3, one of the only really good models with open training data.
Since we have its entire training corpus, we can exhaustively check for real "natural" duplicates and finetune it to estimate their impact. We embed the entire Dolma Instruct corpus.
Since we have its entire training corpus, we can exhaustively check for real "natural" duplicates and finetune it to estimate their impact. We embed the entire Dolma Instruct corpus.
Firstly: we were surprised by how ineffective n-gram decontamination was at catching exact duplicates - 70% of harder tasks had a match. But the spurious performance gain wasn't so large, at most +4pp.

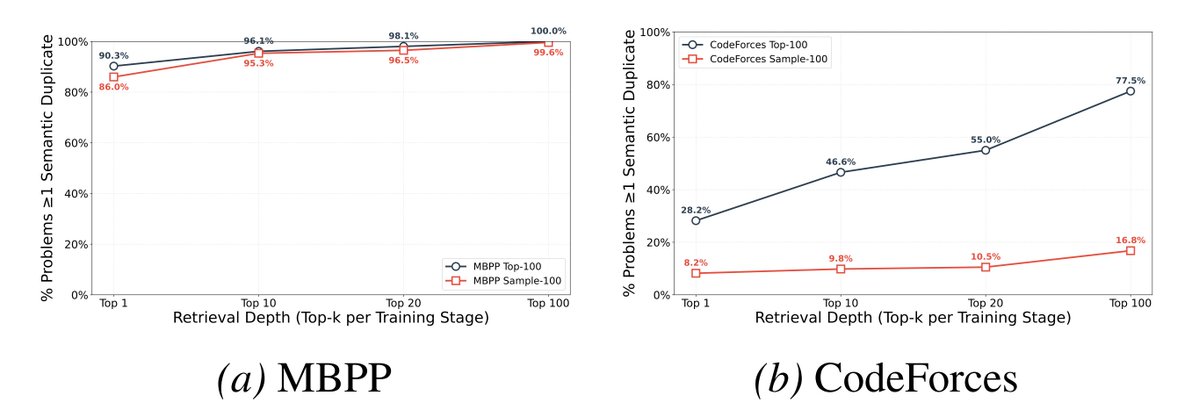
Secondly, every single MBPP test example and 78% of CodeForces have semantic duplicates

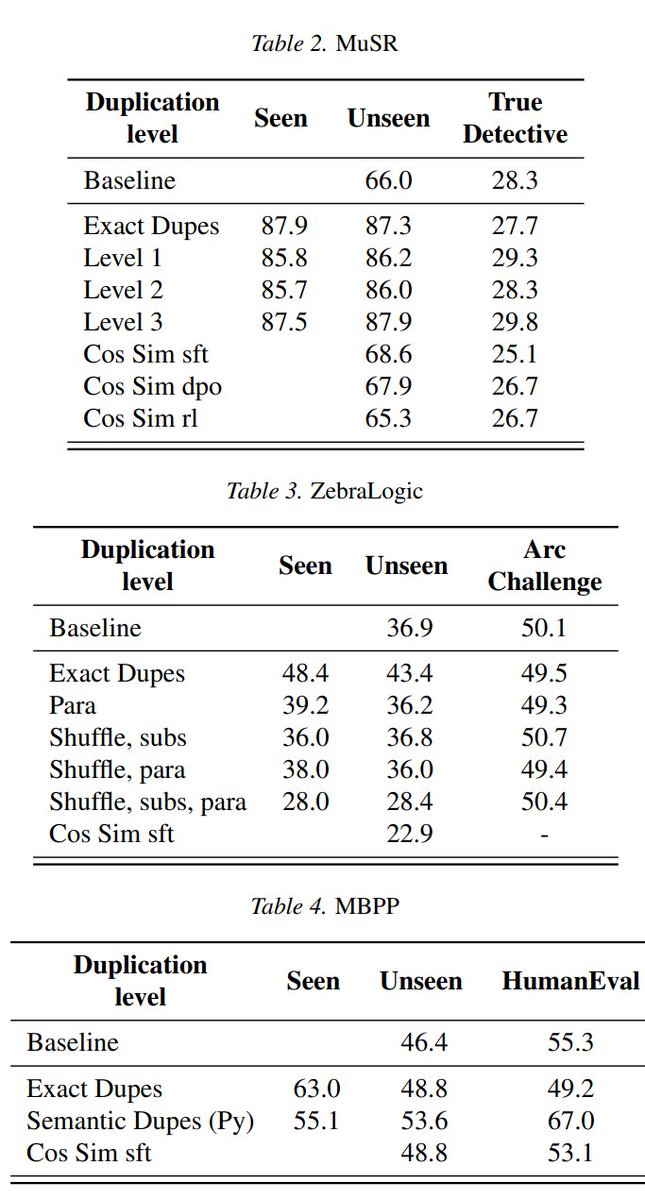
Thirdly we generated 10k synthetic duplicates for MuSR, Zebralogic, and MBPP problems and finetuned on them.
* MuSR +22pp. Semantic duplicates as strong as exact
* ZebraLogic +12pp. Exact much stronger
* MBPP +17pp. Exact stronger
* MuSR +22pp. Semantic duplicates as strong as exact
* ZebraLogic +12pp. Exact much stronger
* MBPP +17pp. Exact stronger
Fourthly we guess that 4 in 10,000 training datapoints are a strong semantic duplicate for a given benchmark datapoint (where strong means just "obvious to Gemini")
So:
n-gram decontamination is not enough even for the easy (exact) stuff, semantic duplicates are at least a moderately big deal, and this probably transfers to frontier models to some degree.
The above are probably underestimates too (since our detection pipeline was cheapo).
n-gram decontamination is not enough even for the easy (exact) stuff, semantic duplicates are at least a moderately big deal, and this probably transfers to frontier models to some degree.
The above are probably underestimates too (since our detection pipeline was cheapo).
Data contamination is a huge field. Here's how we're new
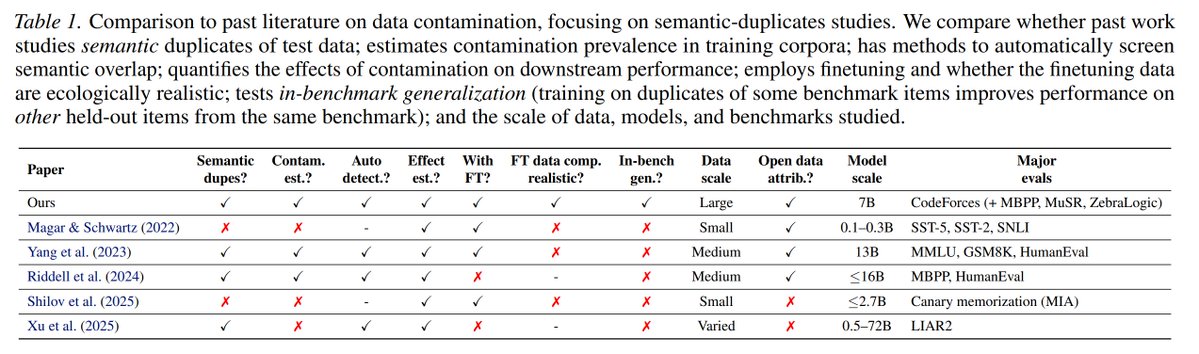
This is preliminary work on a shoestring - we didn't get at the big questions yet ("what share of benchmark gains come from interpolation over a hidden training corpus?", "does this even matter?")
And local generalisation across very different strings is anyway pretty miraculous
And local generalisation across very different strings is anyway pretty miraculous

The grand aim of this research programme is to decompose benchmark gains / apparent AI progress into 4 estimates:
1. benchmaxxing (memorising exact duplicates)
2. usemaxxing (RLing narrow capabilities)
3. hidden interpolation / local generalisation
4. OOD generalisation
1. benchmaxxing (memorising exact duplicates)
2. usemaxxing (RLing narrow capabilities)
3. hidden interpolation / local generalisation
4. OOD generalisation
We have a lot of ideas! If you're interested in funding this, grab me at gavin@arbresearch.com
Nearly all of the real work done by Ari Spiesberger, @Juan_VaGu, Nicky Pochinkov, Tomas Gavenciak, @peligrietzer and @NandiSchoots
And ofc this work wouldn't be possible without @allen_ai @natolambert working in public and enabling actually scientific evals.
And ofc this work wouldn't be possible without @allen_ai @natolambert working in public and enabling actually scientific evals.
* at least 50% and at least 78% that is
• • •
Missing some Tweet in this thread? You can try to
force a refresh