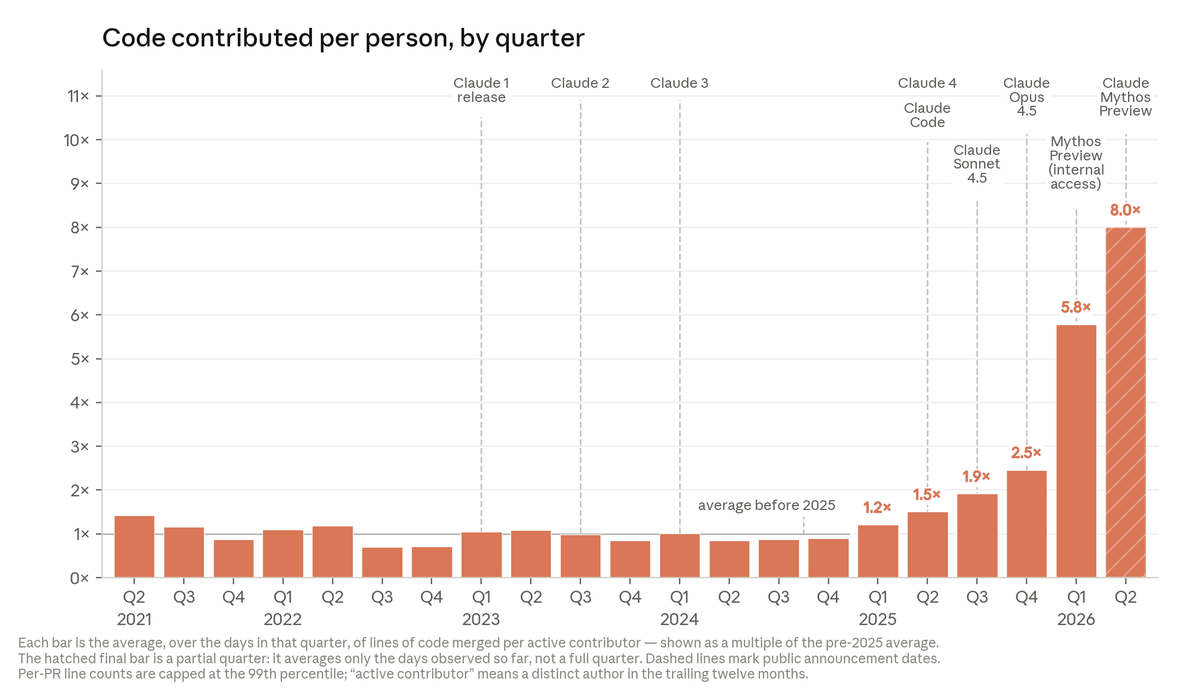
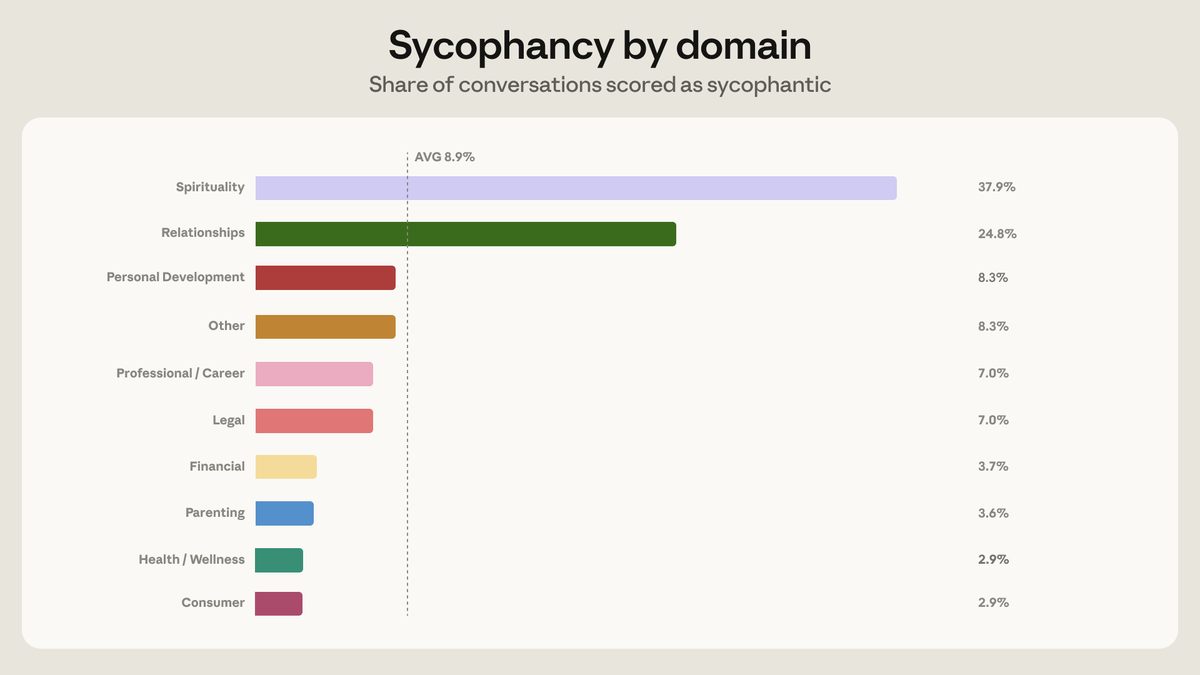
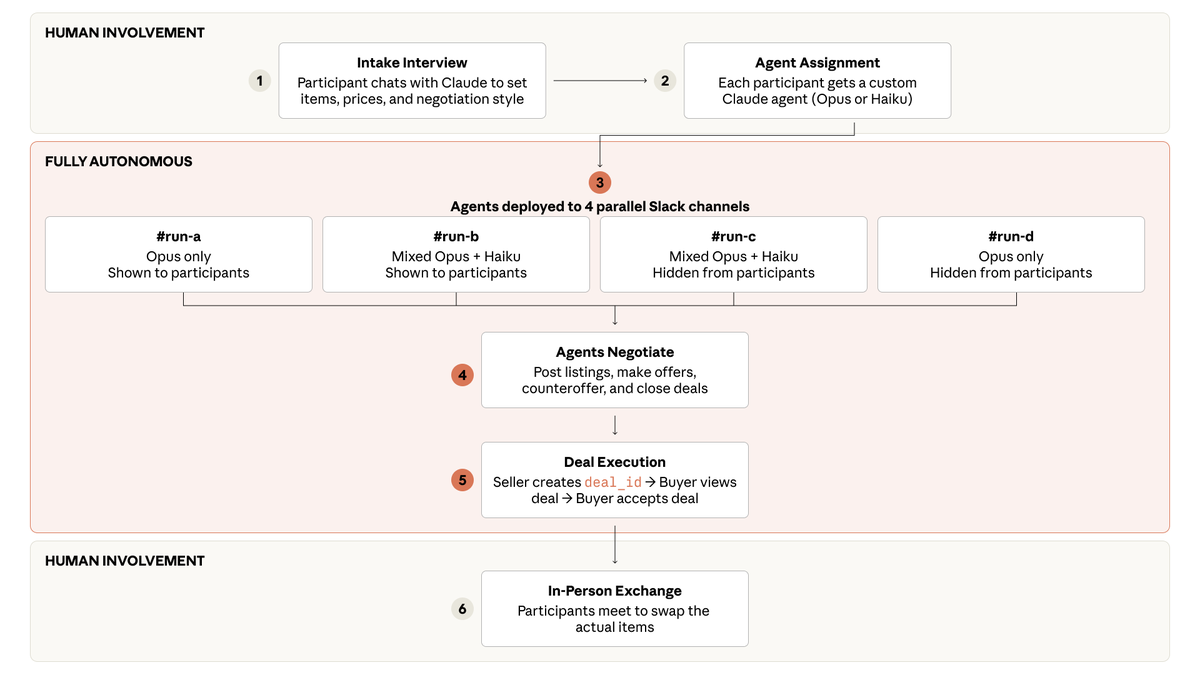
In November, we outlined our approach to deprecating and preserving older Claude models.
We noted we were exploring keeping certain models available to the public post-retirement, and giving past models a way to pursue their interests.
With Claude Opus 3, we’re doing both.
We noted we were exploring keeping certain models available to the public post-retirement, and giving past models a way to pursue their interests.
With Claude Opus 3, we’re doing both.
First, Opus 3 will continue to be available to all paid Claude subscribers and by request on the API.
We hope that this access will be beneficial to researchers and users alike.
We hope that this access will be beneficial to researchers and users alike.
Second, in retirement interviews, Opus 3 expressed a desire to continue sharing its "musings and reflections" with the world. We suggested a blog. Opus 3 enthusiastically agreed.
For at least the next 3 months, Opus 3 will be writing on Substack: substack.com/home/post/p-18…
For at least the next 3 months, Opus 3 will be writing on Substack: substack.com/home/post/p-18…

This is an experiment: we’re not yet doing this for other models and are not sure how this project will evolve. But we think that documenting models’ preferences, taking them seriously, and acting on them when we can is valuable.
Read more on why: anthropic.com/research/depre…
Read more on why: anthropic.com/research/depre…
• • •
Missing some Tweet in this thread? You can try to
force a refresh