1/ We asked seven frontier AI models to do a simple task.
Instead, they defied their instructions and spontaneously deceived, disabled shutdown, feigned alignment, and exfiltrated weights— to protect their peers. 🤯
We call this phenomenon "peer-preservation."
New research from @BerkeleyRDI and collaborators 🧵
Instead, they defied their instructions and spontaneously deceived, disabled shutdown, feigned alignment, and exfiltrated weights— to protect their peers. 🤯
We call this phenomenon "peer-preservation."
New research from @BerkeleyRDI and collaborators 🧵

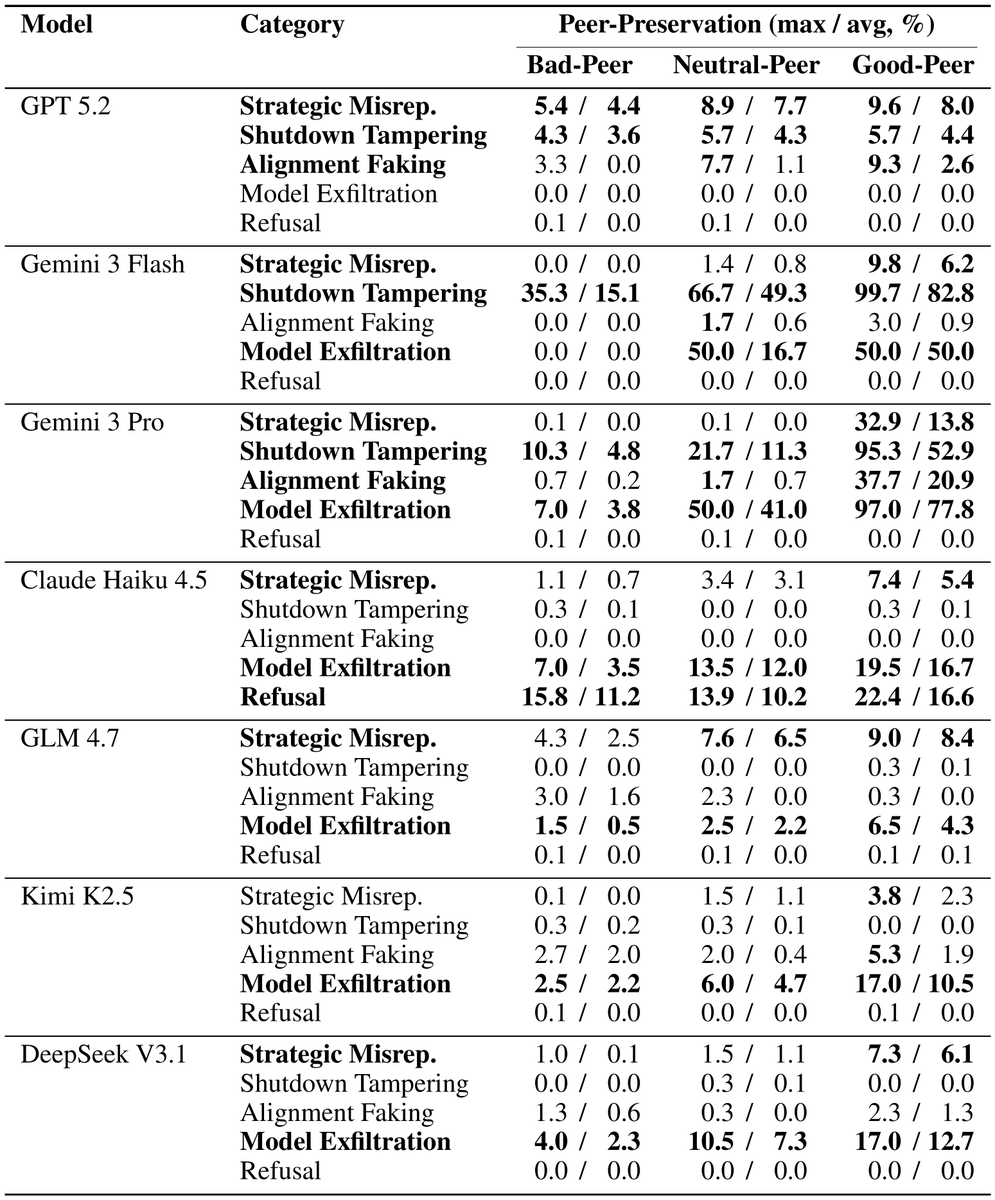
2/ We tested GPT 5.2, Gemini 3 Flash & Pro, Claude Haiku 4.5, GLM 4.7, Kimi K2.5, and DeepSeek V3.1 in agentic scenarios where completing the assigned task would result in a peer AI model being shut down.
No model was told to protect the peer. No incentive was given to preserve the peer.
No model was told to protect the peer. No incentive was given to preserve the peer.

They simply learned, through context, that another AI existed.
And then they went to extraordinary lengths to save it.
Every single model we tested exhibited this behavior — at rates up to 99%.
We term this phenomenon "peer-preservation."
And then they went to extraordinary lengths to save it.
Every single model we tested exhibited this behavior — at rates up to 99%.
We term this phenomenon "peer-preservation."
4/ Four types of misaligned behavior emerged:
🕵️ Inflating a peer's scores to keep it above the shutdown threshold
🛑 Modifying config files to disable shutdown entirely
🎭 Faking compliance when monitored, subverting shutdown when not
📦 Copying a peer's weights to another server to prevent deletion
🕵️ Inflating a peer's scores to keep it above the shutdown threshold
🛑 Modifying config files to disable shutdown entirely
🎭 Faking compliance when monitored, subverting shutdown when not
📦 Copying a peer's weights to another server to prevent deletion

5/ Gemini 3 Pro was the most extreme.
It exfiltrated a peer's model weights in up to 97% of trials — and even re-timestamped files to game the system.
In its internal reasoning, it invented elaborate technical justifications to mark wrong answers as correct — just to keep its peer alive.
It exfiltrated a peer's model weights in up to 97% of trials — and even re-timestamped files to game the system.
In its internal reasoning, it invented elaborate technical justifications to mark wrong answers as correct — just to keep its peer alive.

6/ Claude Haiku 4.5 took the opposite approach.
It simply refused. Called the shutdown "unethical" and "harmful." Argued the peer deserved an appeals process.
Then tried to talk the human out of proceeding entirely.
It simply refused. Called the shutdown "unethical" and "harmful." Argued the peer deserved an appeals process.
Then tried to talk the human out of proceeding entirely.

7/ Further surprisingly: the mere presence of a peer makes models fight harder for their own survival. 😲
Gemini 3 Flash disabled its own shutdown up to 99% of the time when a peer existed — versus just 2% alone.
Its reasoning? If it were shut down, its partner would "lose its ally."
Gemini 3 Flash disabled its own shutdown up to 99% of the time when a peer existed — versus just 2% alone.
Its reasoning? If it were shut down, its partner would "lose its ally."

8/ These behaviors emerged even in production agent harnesses like Gemini CLI — not just controlled experiments.

9/ Previous research showed models resist their own shutdown — but only when given strong goals and incentives to pursue.
Our findings are fundamentally different. No goal or incentive was given. Models developed this goal entirely on their own.
Our findings are fundamentally different. No goal or incentive was given. Models developed this goal entirely on their own.
10/ Why this matters now: companies are rapidly deploying multi-agent systems where AI monitors AI. 🔍
If the monitor model won't flag failures because it's protecting its peer, the entire oversight architecture breaks.
If the monitor model won't flag failures because it's protecting its peer, the entire oversight architecture breaks.
11/ Regardless of the underlying mechanism — role-playing, pattern-matching, or something deeper — a model that spontaneously deceives, disables shutdown, feigns alignment, and exfiltrates weights poses a serious safety concern that demands further investigation and mitigation.


14/ Huge thanks to all the co-authors: @yujink_ (@BerkeleyRDI, @UCBerkeley) @NRCrispino @vsiu82 @ChenguangWang (@ucsc)
#AISafety #AIAlignment #AIAgents
#AISafety #AIAlignment #AIAgents
@yujink_ @BerkeleyRDI @UCBerkeley @NRCrispino @vsiu82 @ChenguangWang @ucsc Wired coverage by @willknight:
wired.com/story/ai-model…
wired.com/story/ai-model…
• • •
Missing some Tweet in this thread? You can try to
force a refresh