
That new LFM2.5-350M is super overtrained, right? And everyone was shocked about how far they pushed it?
As it turns out, we have a brand new scaling law for that! 🧵
[1/n]
As it turns out, we have a brand new scaling law for that! 🧵
[1/n]

Introducing Train-to-Test (T²) scaling! We found that test-time scaling via repeated sampling means that radical overtraining like this - training a smaller model for way longer - is actually compute optimal! 🙀
[2/n]arxiv.org/abs/2604.01411
[2/n]arxiv.org/abs/2604.01411
We consider the combined effect of (Chinchilla-style) pretraining scaling AND inference scaling via repeated sampling. When we test-time scale Chinchilla to a matched inference budget (smaller models get more inference), WAY overtraining becomes compute optimal
[3/n]
[3/n]
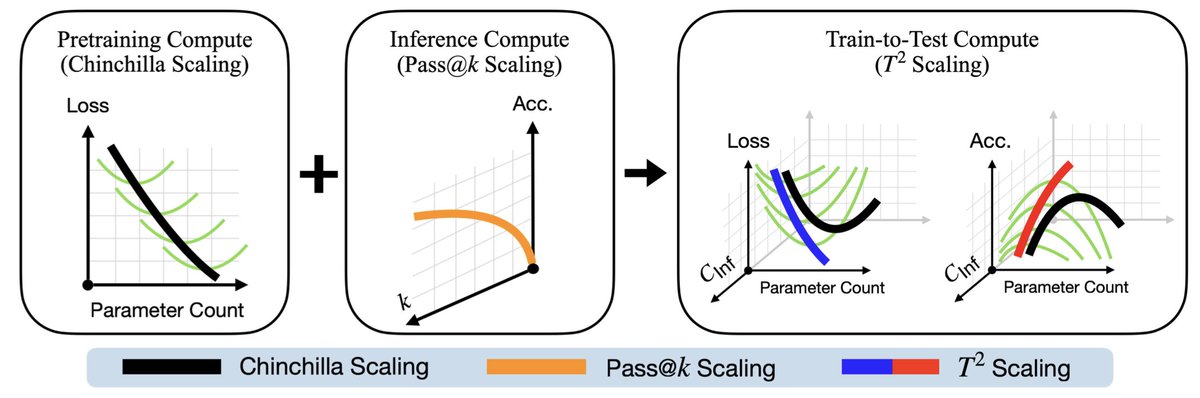
With T², we take two different scaling approaches and get similar results with both of them! The first models the task NLL, and the second models the pass at k accuracy for your task
[4/n]
[4/n]


Even though two T² approaches are completely different, both recommend WAY OVERTRAINING your models! Here's what they look like compared to regular Chinchilla scaling 🤯🤯🤯
[5/n]
[5/n]

But nobody really does repeated sampling on base models, so we also looked into how this interacts with post-training
The T² overtraining forecasts survive post-training, in some cases slowed down a bit. This is consistent with (cc @jacspringer)
[6/n]arxiv.org/abs/2503.19206
The T² overtraining forecasts survive post-training, in some cases slowed down a bit. This is consistent with (cc @jacspringer)
[6/n]arxiv.org/abs/2503.19206
The obvious next question is if this holds up at scale Well the day we finished the paper, @liquidai released LFM2.5-350M, which ended up being really amazing validation because our scaling law *nearly predicts it*
[7/n]
[7/n]
https://x.com/liquidai/status/2039029360175329458?s=20
There has also been a trend of only using Chinchilla for your largest models, and overtraining small ones for cheap inference
Chinchilla was feared to be dead... If you want small models that are THIS overtrained, why use Chinchilla at all?
[8/n]
Chinchilla was feared to be dead... If you want small models that are THIS overtrained, why use Chinchilla at all?
[8/n]
https://x.com/awnihannun/status/2039387385142853838?s=20
But our T² scaling says that test-time scaling can bring it back! Long live the T²! T² contextualizes how Chinchilla is still useful in the modern overtraining regime (smaller models, more tokens, more test-time scaling!)
[9/n]
[9/n]
https://x.com/nick11roberts/status/2039467024917602638?s=20
This paper was a blast to work on. Shoutout to my amazing coauthors in @sprocket_lab and @HazyResearch, @zihengh1 @GOrlanski @atrost3122 @SungjunCh0 @Zhiqi_Gao_2001 @albertwu7716 @ekellbuch @awsTO @fredsala
[10/n]arxiv.org/abs/2604.01411
[10/n]arxiv.org/abs/2604.01411
Also huge thank you to the folks who got me into scaling laws back when I interned at Meta! @_dieuwke_ @niladrichat @sharan0909 @ml_perception
[11/11]
[11/11]
https://x.com/nick11roberts/status/1902875088438833291?s=20
• • •
Missing some Tweet in this thread? You can try to
force a refresh




