
Introducing Latent Briefing, a way for agents to quickly share their relevant memory directly. Result: 31% fewer tokens used, same accuracy.
Multi-agent systems are powerful, but can be wildly inefficient. They pass context as tokens, so costs explode and signal gets lost. We built an algorithm that allows agents to communicate KV cache to KV cache.
Multi-agent systems are powerful, but can be wildly inefficient. They pass context as tokens, so costs explode and signal gets lost. We built an algorithm that allows agents to communicate KV cache to KV cache.
Agents need to share context, but doing it in token space has real tradeoffs:
• LLM summaries: slow (20–60s), lossy, and often miss what the next agent actually needs
• RAG: splits context into chunks, so relationships across documents get lost
• Passing full context: expensive, noisy, and often hurts accuracy
Our method skips tokens entirely. We operate on the KV cache, using the worker's own attention patterns to extract what's relevant from the orchestrator's memory and discard the rest.
• LLM summaries: slow (20–60s), lossy, and often miss what the next agent actually needs
• RAG: splits context into chunks, so relationships across documents get lost
• Passing full context: expensive, noisy, and often hurts accuracy
Our method skips tokens entirely. We operate on the KV cache, using the worker's own attention patterns to extract what's relevant from the orchestrator's memory and discard the rest.
We adapted the Attention Matching (AM) KV cache compaction framework. The AM algorithm compacts the KV cache (C1, β, C2) preserving attention outputs through a correction term.
We modified the algorithm to make it inference ready:
1. Score tokens using the worker's task query, not self attention
2. Global mask across all heads → enables massive batching
3. MAD-normalized thresholding for adaptive compression
Result: 320 sequential solves → 2-3 batched ops. 20x speedup to a median of 1.7 s.
We modified the algorithm to make it inference ready:
1. Score tokens using the worker's task query, not self attention
2. Global mask across all heads → enables massive batching
3. MAD-normalized thresholding for adaptive compression
Result: 320 sequential solves → 2-3 batched ops. 20x speedup to a median of 1.7 s.

We ran RLM on LongBench v2 across various document lengths and difficulty levels, observing a 30% median token reduction with a consistent +3% accuracy boost.
We also found that the optimal compaction level is dynamic:
Longer documents benefit from lighter compaction, while harder tasks require more aggressive filtering.
We also found that the optimal compaction level is dynamic:
Longer documents benefit from lighter compaction, while harder tasks require more aggressive filtering.
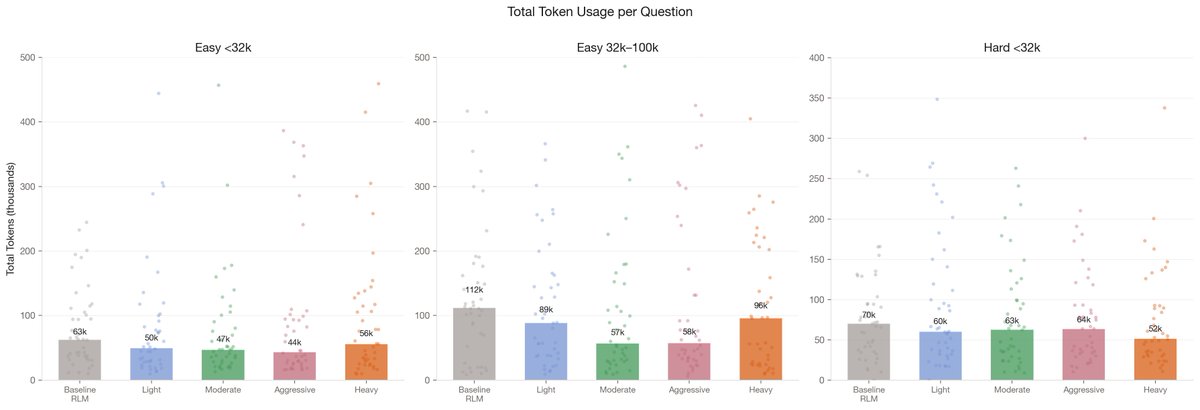
Conceptually, this is a bit like taking notes. Sometimes you’re trying to build a body of knowledge over time, and the details matter because they accumulate into something larger. In those cases, you want to preserve context rather than compress it too early. With harder problems you’re often sketching ideas, exploring directions, following threads that may or may not lead anywhere. Most of what gets written down in that process isn’t meant to last.
Latent briefing = saving time and money 😎
Full write up: x.com/RampLabs/statu…
Latent briefing = saving time and money 😎
Full write up: x.com/RampLabs/statu…
• • •
Missing some Tweet in this thread? You can try to
force a refresh



