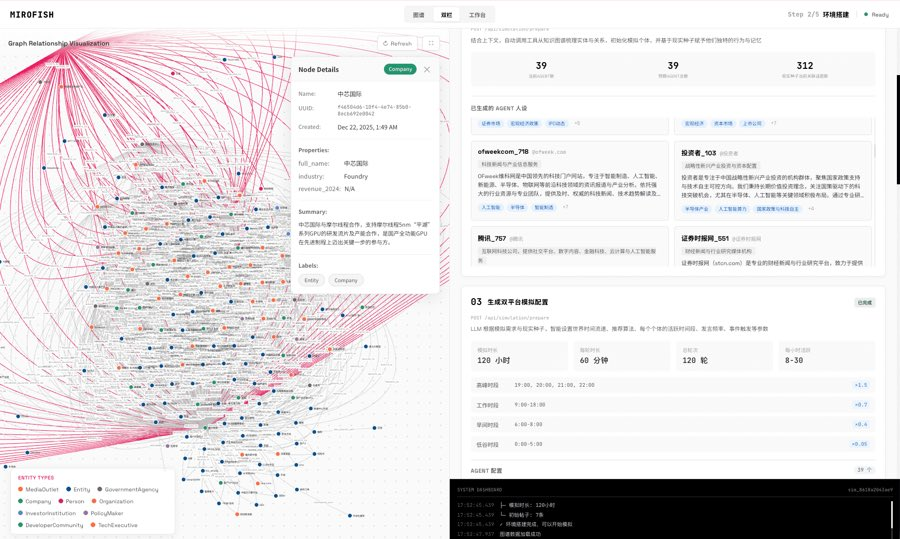
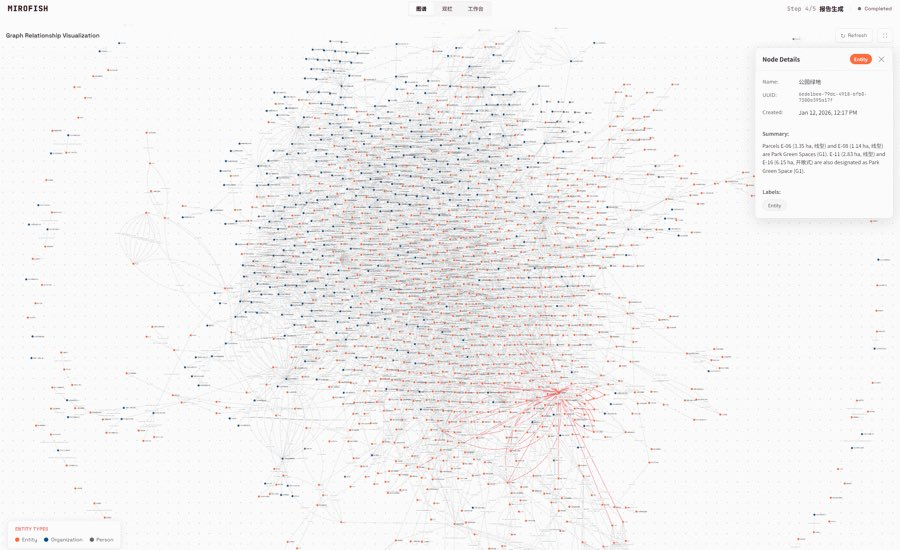
Damn,今天看到这个东西,我觉得未来30年的电脑界面可能要被彻底改写了。
它叫Flipbook,最疯狂的地方是它没有HTML,没有CSS,没有按钮,没有输入框,
你屏幕上的每一颗像素,都是AI实时画出来的。
过去30年,所有的电脑界面都是乐高积木式的,
工程师写代码,设计师画图纸,一块一块拼出固定的样子。
现在,AI直接从脑子里,给你流出一整张活的画面。
你搜巴黎旅行,
它给你画一幅完整的巴黎插画地图,
你点埃菲尔铁塔,它直接放大成门票和开放时间。
你点塞纳河,它给你画出游船路线和价格。
整个过程没有跳转,没有加载,只有流畅的变形,就像在翻一本有魔法的活绘本。
最颠覆的我觉得倒不是好看,而是再也没有按钮这个概念了,
任何你看到的东西,都能点,
设计师再也不用提前规定哪里能交互,哪里不能,
AI会理解你想点什么,然后给你对应的内容。
他们把视频生成模型,优化到了1080p24帧实时输出,
你的浏览器不再是只加载网页,
还能一帧一帧的接收AI专门为你画的专属电影。
教育领域会是被第一个干穿的,
以后讲水分子结构,不用看静态的PPT,你点一下氢原子,它就给你演示氢键怎么形成。
你点一下冰块,它就给你展示为什么冰会浮在水上。
复杂的知识,直接变成能玩的沉浸式动画。
当然现在它还很烂,
卡,慢,有时候会画错字,
计算成本是传统网页的2000倍,
很多功能还只是演示。
但我觉得这些都不重要,重要的是它证明了一件事:
界面根本不需要代码。
我们用了几十年的窗口、按钮、菜单这套范式,从今天起,真的要开始倒计时了。
这不是一个新玩具,这是计算范式的一次彻底转向,从代码驱动的结构化界面走向AI驱动的生成式界面
它叫Flipbook,最疯狂的地方是它没有HTML,没有CSS,没有按钮,没有输入框,
你屏幕上的每一颗像素,都是AI实时画出来的。
过去30年,所有的电脑界面都是乐高积木式的,
工程师写代码,设计师画图纸,一块一块拼出固定的样子。
现在,AI直接从脑子里,给你流出一整张活的画面。
你搜巴黎旅行,
它给你画一幅完整的巴黎插画地图,
你点埃菲尔铁塔,它直接放大成门票和开放时间。
你点塞纳河,它给你画出游船路线和价格。
整个过程没有跳转,没有加载,只有流畅的变形,就像在翻一本有魔法的活绘本。
最颠覆的我觉得倒不是好看,而是再也没有按钮这个概念了,
任何你看到的东西,都能点,
设计师再也不用提前规定哪里能交互,哪里不能,
AI会理解你想点什么,然后给你对应的内容。
他们把视频生成模型,优化到了1080p24帧实时输出,
你的浏览器不再是只加载网页,
还能一帧一帧的接收AI专门为你画的专属电影。
教育领域会是被第一个干穿的,
以后讲水分子结构,不用看静态的PPT,你点一下氢原子,它就给你演示氢键怎么形成。
你点一下冰块,它就给你展示为什么冰会浮在水上。
复杂的知识,直接变成能玩的沉浸式动画。
当然现在它还很烂,
卡,慢,有时候会画错字,
计算成本是传统网页的2000倍,
很多功能还只是演示。
但我觉得这些都不重要,重要的是它证明了一件事:
界面根本不需要代码。
我们用了几十年的窗口、按钮、菜单这套范式,从今天起,真的要开始倒计时了。
这不是一个新玩具,这是计算范式的一次彻底转向,从代码驱动的结构化界面走向AI驱动的生成式界面
https://x.com/AYi_AInotes/status/2046982383430496444
• • •
Missing some Tweet in this thread? You can try to
force a refresh