New preprint from me and @chris_percy: "What do anti-pain algorithms imply for computational functionalism?" Brain emulations meet reversible computation and really weird qualia. 
Preprint at: philpapers.org/rec/PERWDA-4
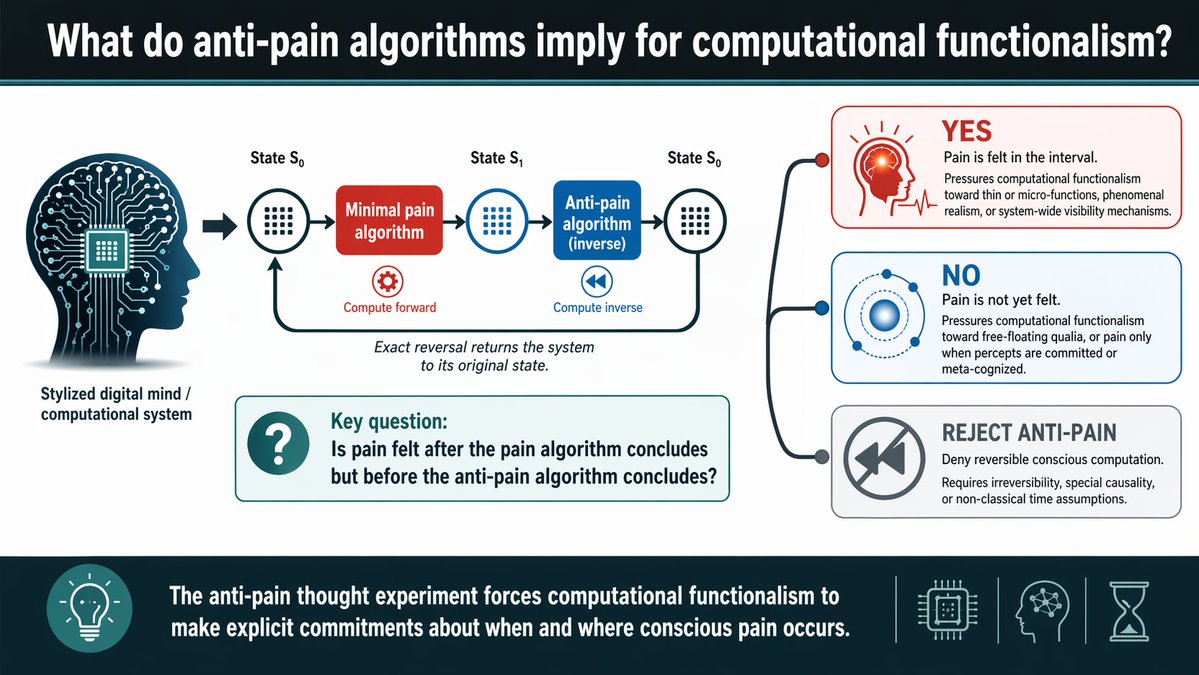
Any classical computation can be implemented as a reversible computation (Bennett), so it can be run from time t0 to time t1, and then "uncomputed" by running it backward so at time t0 we are back at the original state. Great if you care about the Landauer limit!
What if we run (a deterministic) brain emulation like this? If it has a phenomenal experience (which functionalism assumes) of pain as we go from t0 to t1, what does it experience between t1 and t2 as we uncompute? Is there "anti-pain"? Was anything felt at t1?
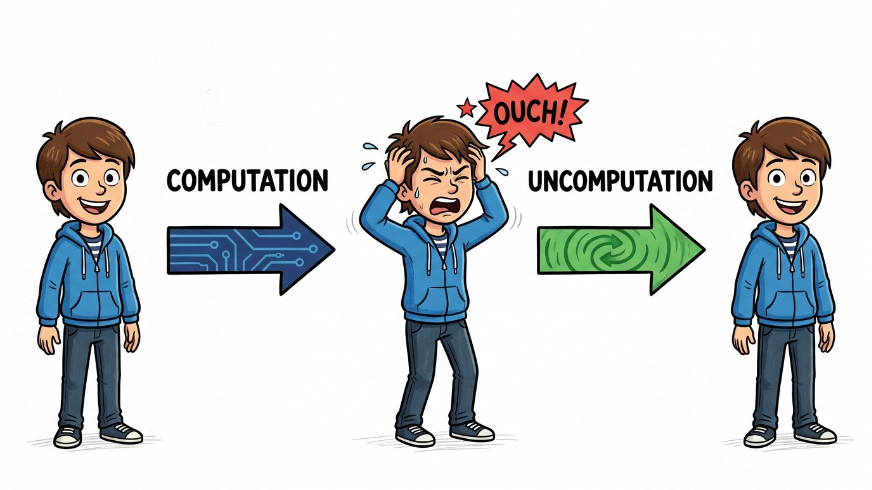
We assume some minimal algorithm that has the experience and cannot be made simpler without losing it. If every logic operation has qualia, then we end up in "pan-panpsychism" where every logic operations contains a flavour of every possible experience!
At t1 we might not even know if the uncomputation will happen, so it seems plausible that there should be pain experience. But functionalism says only the function of a computation matters: the whole exercise is just the identity function.
Maybe there is no pain at t1, just 'uncommitted pain bits' that later gets committed to a phenomenal ledger, for example if the emulation acts on them. But now qualia are almost free-floating.
Maybe this experiment cannot be done. One could try rejecting the possibility of reversible calculations, assert that consciousness algorithms are not reversible (a substrate assumption), or claim experiences depend on causal histories rather than states.
Like any proper philosophy paper it leads to uncomfortable conclusions.
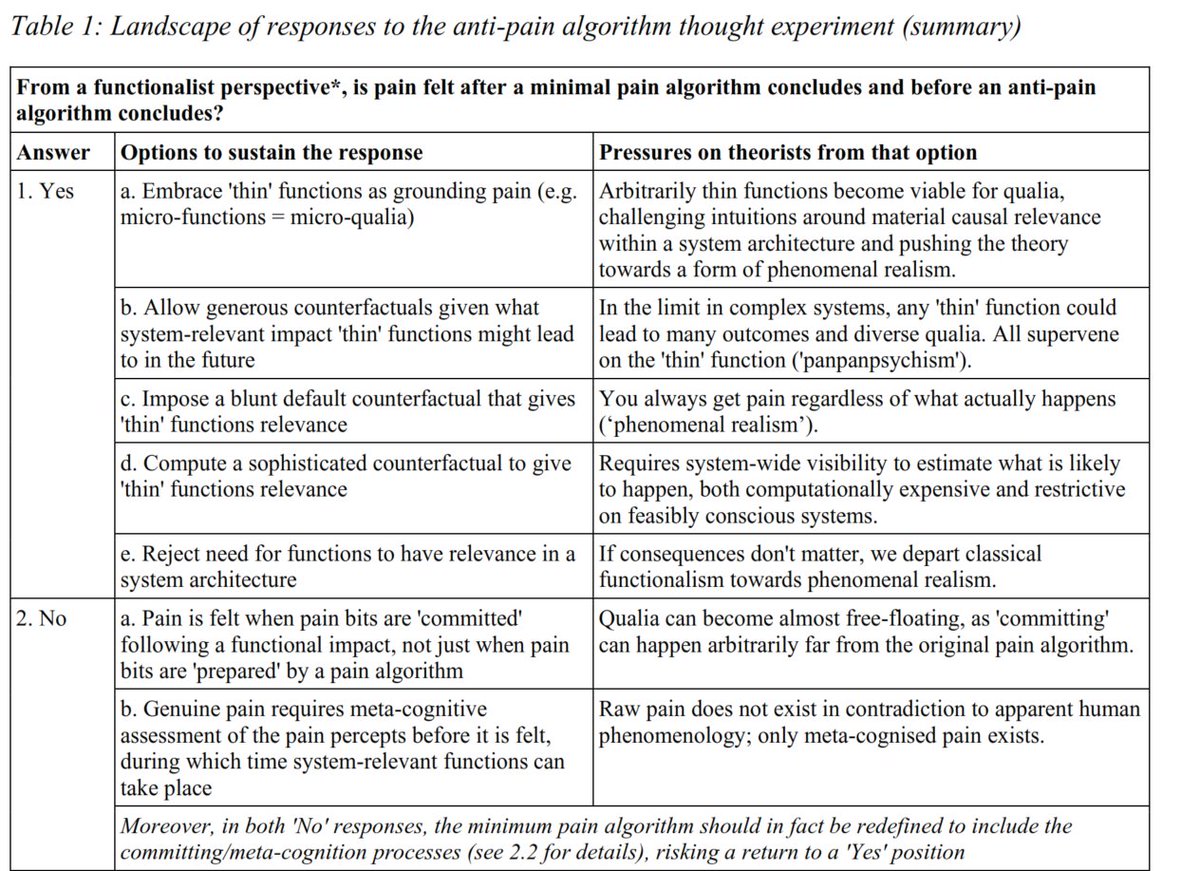

I also suspect non-functionalist models are vulnerable to similar weirdness, it is just that it is easier to envision anti-pain algorithms than e.g. all particles of a body reversing velocities and going back to a starting state, which would be the physicalist version.
Anti-pain experiences are intriguing. What do they feel like, if they feel like anything?

• • •
Missing some Tweet in this thread? You can try to
force a refresh