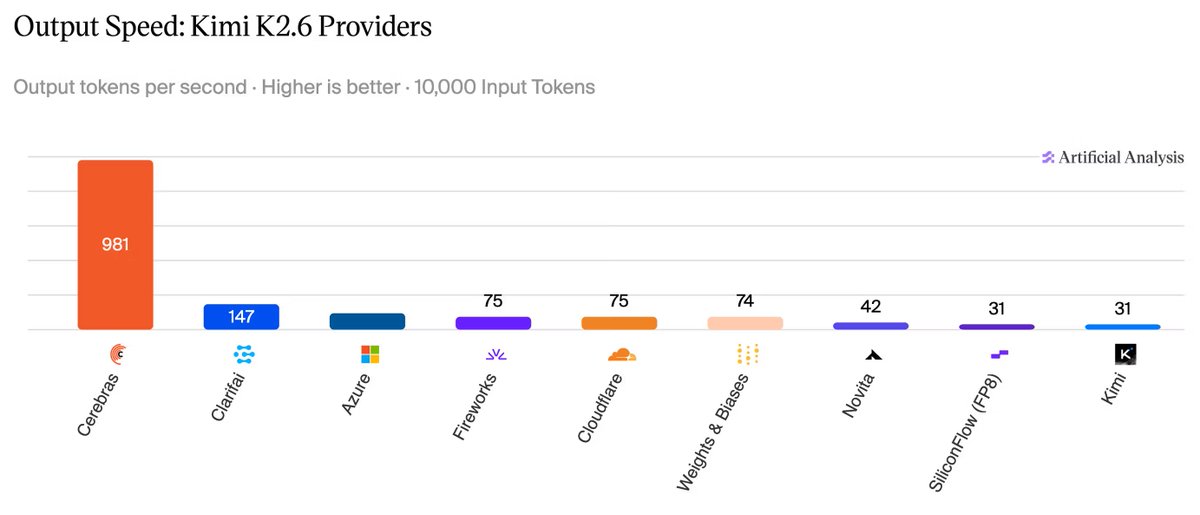
Cerebras is now running Kimi K2.6 – a trillion parameter model – in enterprise trials.
At ~1,000 tokens/s, this is the fastest frontier model performance ever measured by Artificial Analysis @ArtificialAnlys.
At ~1,000 tokens/s, this is the fastest frontier model performance ever measured by Artificial Analysis @ArtificialAnlys.
Learn more: cerebras.ai/blog/cerebras-…
• • •
Missing some Tweet in this thread? You can try to
force a refresh