What are users thinking during their interactions with LLMs?
We introduce ThoughtTrace — the first large-scale dataset that captures what users think during real-world human–AI conversations, not just what they type.
→ 10,174 thought annotations
→ 2,155 multi-turn conversations, 17,058 turns
→ 1,058 users
→ 20 LLMs
These thoughts improve user behavior prediction (+41.7%) and model alignment (+25.6%).
This opens a new paradigm of user-centric LLM research. Full information in the thread 🧶
Read our paper: arxiv.org/abs/2605.20087
Check our project website: thoughttrace-project.github.io
We introduce ThoughtTrace — the first large-scale dataset that captures what users think during real-world human–AI conversations, not just what they type.
→ 10,174 thought annotations
→ 2,155 multi-turn conversations, 17,058 turns
→ 1,058 users
→ 20 LLMs
These thoughts improve user behavior prediction (+41.7%) and model alignment (+25.6%).
This opens a new paradigm of user-centric LLM research. Full information in the thread 🧶
Read our paper: arxiv.org/abs/2605.20087
Check our project website: thoughttrace-project.github.io
Conversational AI has reached billions of users, yet every dataset captures only what people say, never what they think.
ThoughtTrace pairs each turn with the user’s own latent thought: 🟦reasons for sending a prompt 🟧 reactions to the assistant's response.
ThoughtTrace pairs each turn with the user’s own latent thought: 🟦reasons for sending a prompt 🟧 reactions to the assistant's response.

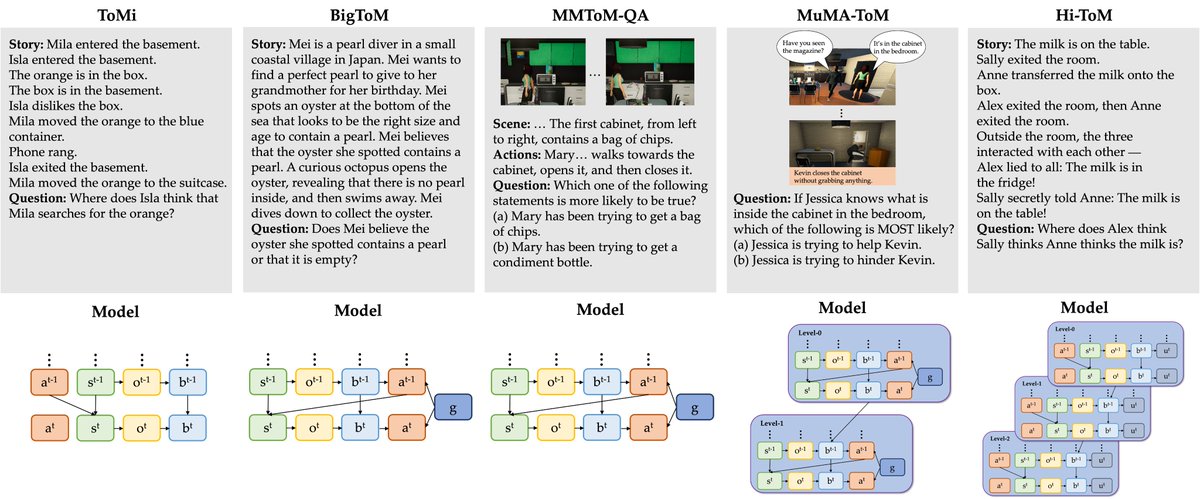
ThoughtTrace is long-horizon and diverse.
Median 8 turns/conv, while existing datasets like WildChat and LMSYS-Chat-1M skew shorter with 2 turns/conv. 7 broad domains, 36 subtopics, no single category dominating.
Real users, real tasks, real depth.
Median 8 turns/conv, while existing datasets like WildChat and LMSYS-Chat-1M skew shorter with 2 turns/conv. 7 broad domains, 36 subtopics, no single category dominating.
Real users, real tasks, real depth.

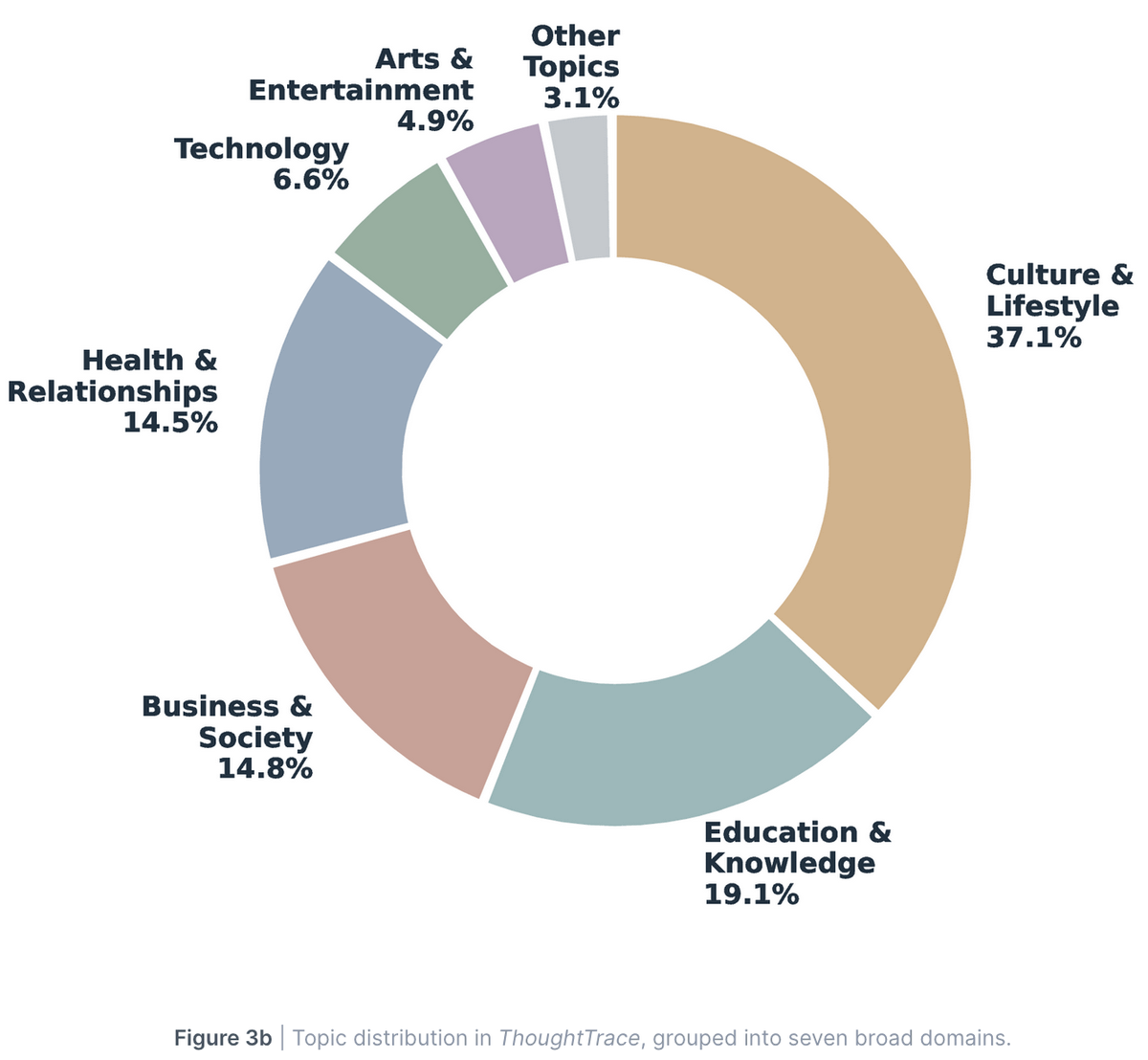
Are thoughts just paraphrased messages? No.
UMAP shows message↔reason and reaction↔next-message pairs have much larger semantic shifts than consecutive messages.
Thoughts are a distinct, complementary signal — not redundant with transcripts.
UMAP shows message↔reason and reaction↔next-message pairs have much larger semantic shifts than consecutive messages.
Thoughts are a distinct, complementary signal — not redundant with transcripts.
Can frontier LLMs just infer the thought from context?
GPT, Gemini, and Claude all struggle:
- Reasons: 2.93 / 5
- Reactions: 2.54 / 5
Latent thoughts carry information that no amount of context can recover. Explicit annotations matter.
GPT, Gemini, and Claude all struggle:
- Reasons: 2.93 / 5
- Reactions: 2.54 / 5
Latent thoughts carry information that no amount of context can recover. Explicit annotations matter.

Thoughts are diverse and stage-dependent.
7 reason types, 5 reaction types.
→ Task Motivation dominates early turns
→ Task Continuation takes over later
→ Explicit Affirmation steadily rises as conversations converge
7 reason types, 5 reaction types.
→ Task Motivation dominates early turns
→ Task Continuation takes over later
→ Explicit Affirmation steadily rises as conversations converge


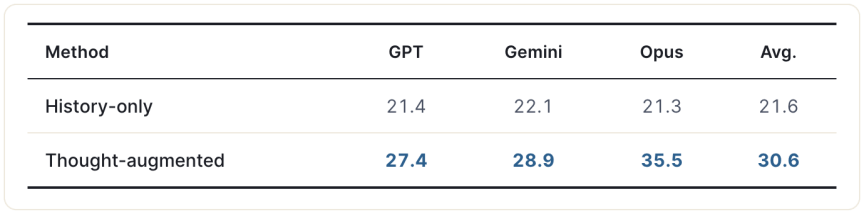
Utility 1: Predicting the next user message.
History-only: 21.6
Thought-augmented: 30.6 → +41.7% relative gain across GPT, Gemini, Opus.
User simulators get dramatically better when they model what users think, not only what they type.
History-only: 21.6
Thought-augmented: 30.6 → +41.7% relative gain across GPT, Gemini, Opus.
User simulators get dramatically better when they model what users think, not only what they type.
Utility 2: Model alignment via DPO.
Thought-guided rewrites on Arena-Hard beat:
Base Qwen3.5-4B by +25.6%
WildChat by +6.6%
Message-guided rewrites by +4.5%
Thoughts give models actionable alignment signals by surfacing dissatisfaction that users never spell out.
Thought-guided rewrites on Arena-Hard beat:
Base Qwen3.5-4B by +25.6%
WildChat by +6.6%
Message-guided rewrites by +4.5%
Thoughts give models actionable alignment signals by surfacing dissatisfaction that users never spell out.

ThoughtTrace opens a new modality for AI research:
→ user modeling beyond utterances
→ training signals from latent thoughts
→ evaluation grounded in subjective experience
→ user modeling beyond utterances
→ training signals from latent thoughts
→ evaluation grounded in subjective experience
📄Paper: arxiv.org/abs/2605.20087
🤗Data: huggingface.co/datasets/SCAI-…
💻Code: github.com/thoughttrace-p…
🔍Check more examples: thoughttrace-project.github.io/examples.html
w/ @binze_li @JackXie492016 @thecatfangs @tli104 @ShayneRedford @HXGuu3 @maximillianc_ @tianminshu 🙏
Fun collaboration with @GoogleResearch @MIT @jhuclsp
🤗Data: huggingface.co/datasets/SCAI-…
💻Code: github.com/thoughttrace-p…
🔍Check more examples: thoughttrace-project.github.io/examples.html
w/ @binze_li @JackXie492016 @thecatfangs @tli104 @ShayneRedford @HXGuu3 @maximillianc_ @tianminshu 🙏
Fun collaboration with @GoogleResearch @MIT @jhuclsp
• • •
Missing some Tweet in this thread? You can try to
force a refresh