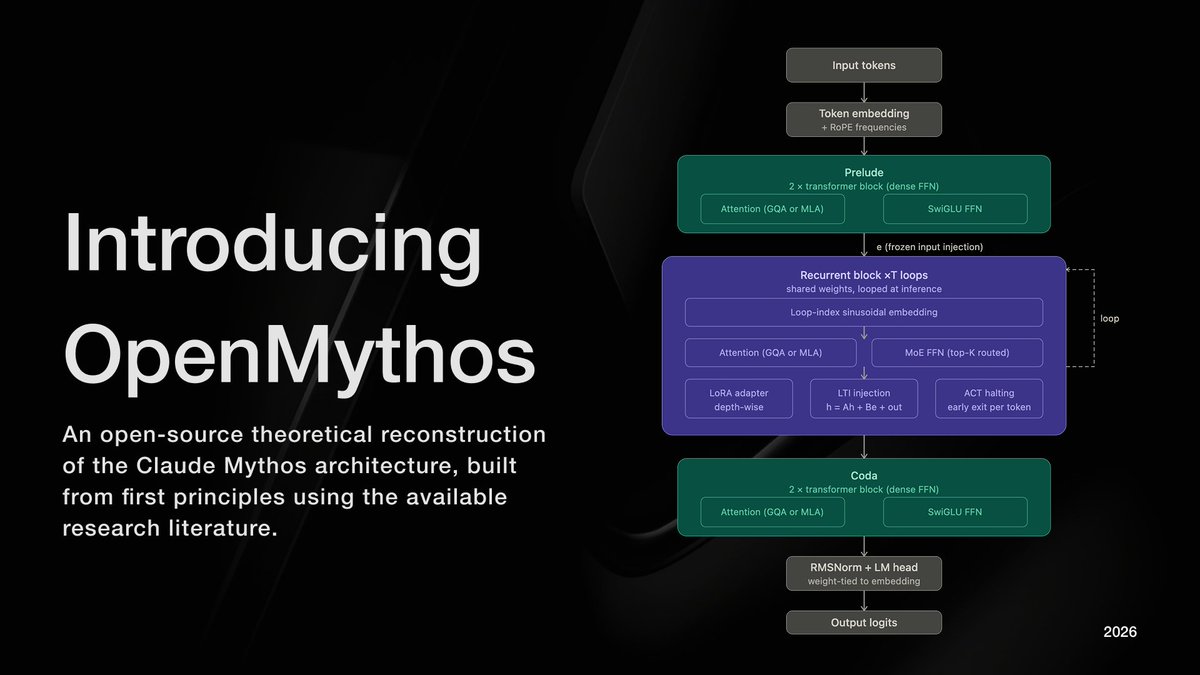
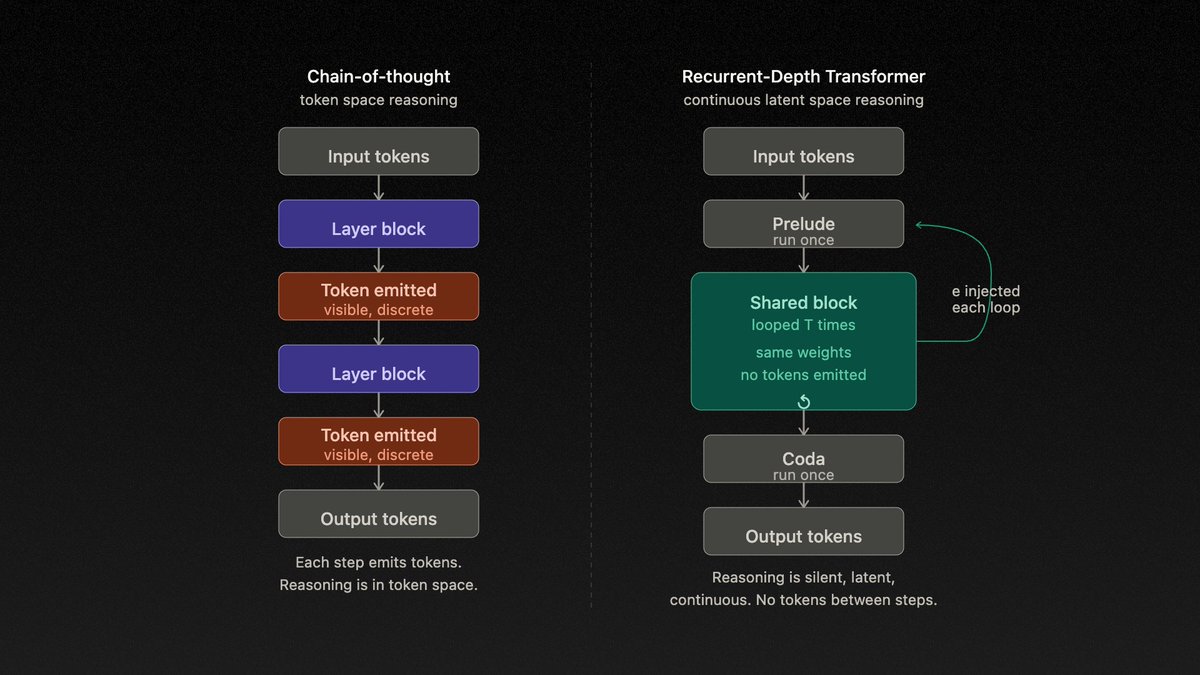
AGI has an assembly index.
In assembly theory (Sharma, Czégel, Lachmann, Kempes, Walker & Cronin, Nature 2023), the assembly index a of an object is the minimum number of recursive joining operations required to construct it from a basis set of elementary parts, where each intermediate is reusable once formed.
The framework was developed to distinguish biotic from abiotic matter: empirically, molecules with a ≳ 15 are not produced by undirected chemistry at detectable abundance, and their occurrence is treated as evidence of an underlying selection process a causal history capable of preserving and recombining intermediates.
The index is thus not a measure of static complexity but of contingent depth: the length of the shortest causal chain compatible with the object's existence.
A thread 🧵⬇️
In assembly theory (Sharma, Czégel, Lachmann, Kempes, Walker & Cronin, Nature 2023), the assembly index a of an object is the minimum number of recursive joining operations required to construct it from a basis set of elementary parts, where each intermediate is reusable once formed.
The framework was developed to distinguish biotic from abiotic matter: empirically, molecules with a ≳ 15 are not produced by undirected chemistry at detectable abundance, and their occurrence is treated as evidence of an underlying selection process a causal history capable of preserving and recombining intermediates.
The index is thus not a measure of static complexity but of contingent depth: the length of the shortest causal chain compatible with the object's existence.
A thread 🧵⬇️

2 /
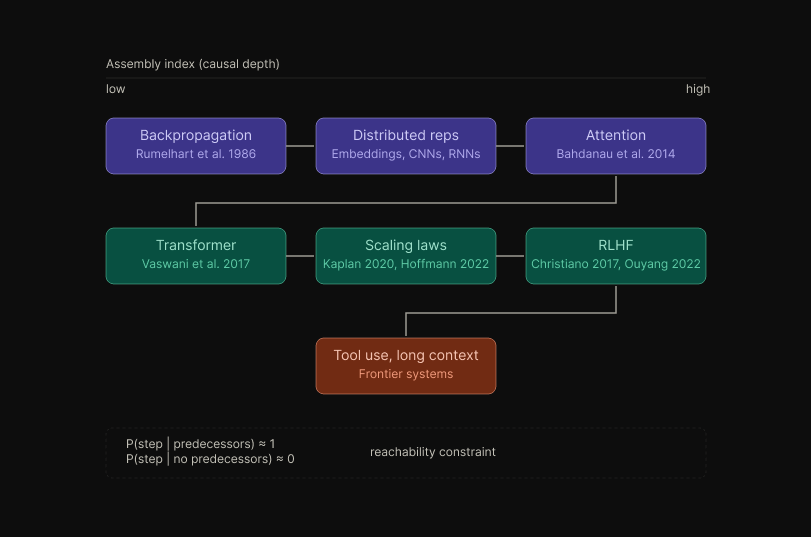
The construction extends naturally to algorithm-space.
Treat the space of learning systems as an assembly space whose elementary operations are formal primitives (differentiable composition, attention, value iteration, policy gradients, in-context conditioning) and whose objects are trainable architectures.
Under this mapping, contemporary frontier systems occupy a regime of high a, reached through an ordered trajectory backpropagation (Rumelhart et al., 1986) → distributed representations → convolutional and recurrent inductive biases → the attention mechanism (Bahdanau et al., 2014) → the transformer (Vaswani et al., 2017) → neural scaling laws (Kaplan et al., 2020; Hoffmann et al., 2022) → RLHF (Christiano et al., 2017; Ouyang et al., 2022) → tool use and extended-context reasoning.
Each transition is conditionally near-zero-probability absent its predecessors. The trajectory is a constraint on reachability.
The construction extends naturally to algorithm-space.
Treat the space of learning systems as an assembly space whose elementary operations are formal primitives (differentiable composition, attention, value iteration, policy gradients, in-context conditioning) and whose objects are trainable architectures.
Under this mapping, contemporary frontier systems occupy a regime of high a, reached through an ordered trajectory backpropagation (Rumelhart et al., 1986) → distributed representations → convolutional and recurrent inductive biases → the attention mechanism (Bahdanau et al., 2014) → the transformer (Vaswani et al., 2017) → neural scaling laws (Kaplan et al., 2020; Hoffmann et al., 2022) → RLHF (Christiano et al., 2017; Ouyang et al., 2022) → tool use and extended-context reasoning.
Each transition is conditionally near-zero-probability absent its predecessors. The trajectory is a constraint on reachability.
3 /
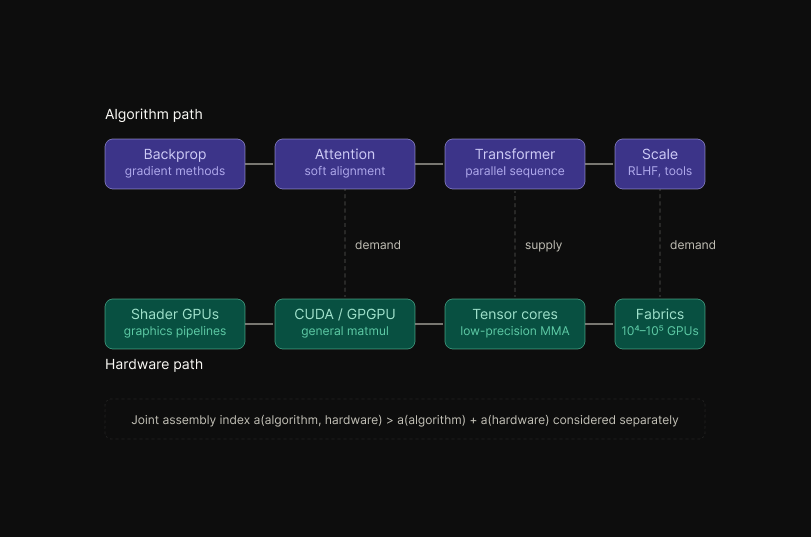
A parallel assembly path governs the physical substrate. Programmable shading hardware was repurposed for general-purpose matrix arithmetic (CUDA, 2007), specialized into tensor cores, and embedded in high-bandwidth interconnect fabrics (NVLink, InfiniBand) capable of maintaining gradient synchrony across 10^4–10^5 accelerators.
Algorithmic and hardware paths are mutually gating: the transformer is computationally inert without dense matmul throughput, and dense matmul throughput is economically unjustified without an architecture that consumes it.
The joint assembly index of the algorithm-hardware pair is therefore strictly greater than either component considered in isolation, and capability gains are bounded by the slower of the two trajectories.
A parallel assembly path governs the physical substrate. Programmable shading hardware was repurposed for general-purpose matrix arithmetic (CUDA, 2007), specialized into tensor cores, and embedded in high-bandwidth interconnect fabrics (NVLink, InfiniBand) capable of maintaining gradient synchrony across 10^4–10^5 accelerators.
Algorithmic and hardware paths are mutually gating: the transformer is computationally inert without dense matmul throughput, and dense matmul throughput is economically unjustified without an architecture that consumes it.
The joint assembly index of the algorithm-hardware pair is therefore strictly greater than either component considered in isolation, and capability gains are bounded by the slower of the two trajectories.
4 /
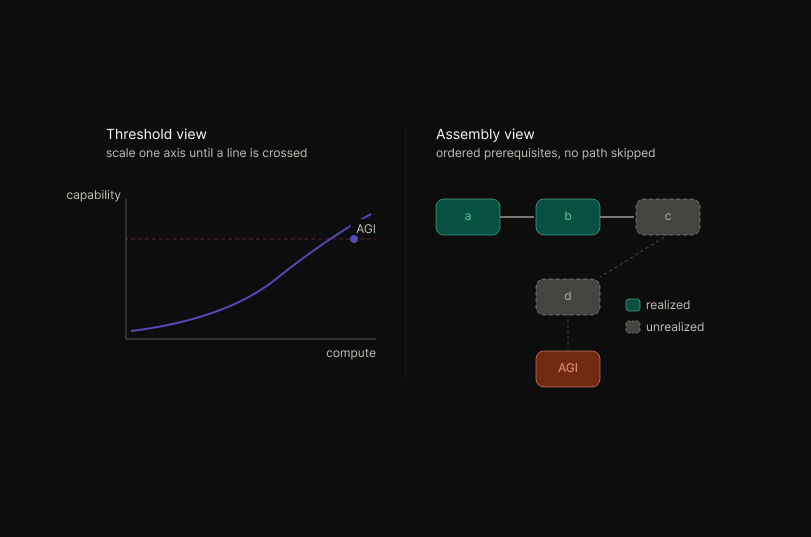
This reframes the scaling debate.
The relevant question is not whether AGI requires a single missing insight or additional compute applied to existing methods, but which prerequisite constructions on the joint trajectory remain unrealized.
Candidate gaps include online continual learning without catastrophic interference, a memory architecture supporting selective consolidation, and a credit-assignment mechanism over horizons exceeding current context windows.
Each is plausibly gated by primitives not yet isolated, and the gating structure implies that compute applied to existing primitives yields diminishing returns once the local subtree of the assembly graph is exhausted.
Step-skipping is not available; the order is a property of the space, not of the researcher.
This reframes the scaling debate.
The relevant question is not whether AGI requires a single missing insight or additional compute applied to existing methods, but which prerequisite constructions on the joint trajectory remain unrealized.
Candidate gaps include online continual learning without catastrophic interference, a memory architecture supporting selective consolidation, and a credit-assignment mechanism over horizons exceeding current context windows.
Each is plausibly gated by primitives not yet isolated, and the gating structure implies that compute applied to existing primitives yields diminishing returns once the local subtree of the assembly graph is exhausted.
Step-skipping is not available; the order is a property of the space, not of the researcher.
5 /
A caveat on the underlying theory.
The status of the assembly index relative to algorithmic information theory remains disputed.
Abrahão, Hernández-Orozco, Kiani, Zenil and colleagues (PLOS Complex Systems 2024) argue that the index is approximated by LZ-class compression and reducible to Shannon entropy under appropriate normalization.
Kempes et al. (npj Complexity 2025) reply that the index quantifies causation under selection rather than minimum description length, and note that exact computation of a is NP-complete, placing it in a distinct complexity class from polynomial-time compression schemes.
For the present argument the analogy is robust to this dispute: under either interpretation, capability sits behind an ordered sequence of constructions whose order is not optional.
The methodological implication is to model AGI not as a threshold crossed along a single scaling axis, but as an object with a construction history, and to direct research effort toward identifying the rate-limiting prerequisites on the joint algorithm-substrate path.
A caveat on the underlying theory.
The status of the assembly index relative to algorithmic information theory remains disputed.
Abrahão, Hernández-Orozco, Kiani, Zenil and colleagues (PLOS Complex Systems 2024) argue that the index is approximated by LZ-class compression and reducible to Shannon entropy under appropriate normalization.
Kempes et al. (npj Complexity 2025) reply that the index quantifies causation under selection rather than minimum description length, and note that exact computation of a is NP-complete, placing it in a distinct complexity class from polynomial-time compression schemes.
For the present argument the analogy is robust to this dispute: under either interpretation, capability sits behind an ordered sequence of constructions whose order is not optional.
The methodological implication is to model AGI not as a threshold crossed along a single scaling axis, but as an object with a construction history, and to direct research effort toward identifying the rate-limiting prerequisites on the joint algorithm-substrate path.
6 /
Conclusion
The framing recasts AGI forecasting as a problem in identifying unrealized prerequisites on a joint algorithm–substrate assembly graph, rather than as extrapolation along a compute axis.
The order of constructions is a property of the space, not a research preference, and step-skipping is not available.
If one accepts the assembly index as causally distinct from algorithmic complexity or treats it as a useful re-parameterization, the methodological conclusion is invariant: capability is gated by ordered prerequisites, and the rate-limiting question is which primitives remain to be isolated.
References below ⬇️
Conclusion
The framing recasts AGI forecasting as a problem in identifying unrealized prerequisites on a joint algorithm–substrate assembly graph, rather than as extrapolation along a compute axis.
The order of constructions is a property of the space, not a research preference, and step-skipping is not available.
If one accepts the assembly index as causally distinct from algorithmic complexity or treats it as a useful re-parameterization, the methodological conclusion is invariant: capability is gated by ordered prerequisites, and the rate-limiting question is which primitives remain to be isolated.
References below ⬇️
7 /
References
Sharma, Czégel, Lachmann, Kempes, Walker & Cronin (2023). Assembly theory explains and quantifies selection and evolution. Nature 622, 321–328. doi.org/10.1038/s41586…
Kempes, Lachmann, Iannaccone, Fricke, Chowdhury, Walker & Cronin (2025). Assembly theory and its relationship with computational complexity. npj Complexity 2, 27. doi.org/10.1038/s44260…
Abrahão, Hernández-Orozco, Kiani, Tegnér & Zenil (2024). Assembly Theory is an approximation to algorithmic complexity based on LZ compression that does not explain selection or evolution. PLOS Complex Systems 1(1), e0000014. doi.org/10.1371/journa…
Rumelhart, Hinton & Williams (1986). Learning representations by back-propagating errors. Nature 323, 533–536. doi.org/10.1038/323533…
Bahdanau, Cho & Bengio (2014). Neural machine translation by jointly learning to align and translate. arXiv:1409.0473. arxiv.org/abs/1409.0473
Vaswani et al. (2017). Attention is all you need. NeurIPS 30. arxiv.org/abs/1706.03762
Kaplan et al. (2020). Scaling laws for neural language models. arXiv:2001.08361. arxiv.org/abs/2001.08361
Hoffmann et al. (2022). Training compute-optimal large language models. arXiv:2203.15556. arxiv.org/abs/2203.15556
Christiano, Leike, Brown, Martic, Legg & Amodei (2017). Deep reinforcement learning from human preferences. NeurIPS 30. arxiv.org/abs/1706.03741
Ouyang et al. (2022). Training language models to follow instructions with human feedback. NeurIPS 35. arxiv.org/abs/2203.02155
References
Sharma, Czégel, Lachmann, Kempes, Walker & Cronin (2023). Assembly theory explains and quantifies selection and evolution. Nature 622, 321–328. doi.org/10.1038/s41586…
Kempes, Lachmann, Iannaccone, Fricke, Chowdhury, Walker & Cronin (2025). Assembly theory and its relationship with computational complexity. npj Complexity 2, 27. doi.org/10.1038/s44260…
Abrahão, Hernández-Orozco, Kiani, Tegnér & Zenil (2024). Assembly Theory is an approximation to algorithmic complexity based on LZ compression that does not explain selection or evolution. PLOS Complex Systems 1(1), e0000014. doi.org/10.1371/journa…
Rumelhart, Hinton & Williams (1986). Learning representations by back-propagating errors. Nature 323, 533–536. doi.org/10.1038/323533…
Bahdanau, Cho & Bengio (2014). Neural machine translation by jointly learning to align and translate. arXiv:1409.0473. arxiv.org/abs/1409.0473
Vaswani et al. (2017). Attention is all you need. NeurIPS 30. arxiv.org/abs/1706.03762
Kaplan et al. (2020). Scaling laws for neural language models. arXiv:2001.08361. arxiv.org/abs/2001.08361
Hoffmann et al. (2022). Training compute-optimal large language models. arXiv:2203.15556. arxiv.org/abs/2203.15556
Christiano, Leike, Brown, Martic, Legg & Amodei (2017). Deep reinforcement learning from human preferences. NeurIPS 30. arxiv.org/abs/1706.03741
Ouyang et al. (2022). Training language models to follow instructions with human feedback. NeurIPS 35. arxiv.org/abs/2203.02155
@threadreaderapp unroll
• • •
Missing some Tweet in this thread? You can try to
force a refresh