introducing pipi, the shitty robot.
brain lives on my laptop, sensors/UI live on the mounted phone. time to completion: 24h (minus sleep, knight festival, lunch, dinner, and play)
built with pi.dev
brain lives on my laptop, sensors/UI live on the mounted phone. time to completion: 24h (minus sleep, knight festival, lunch, dinner, and play)
built with pi.dev
take that, @huggingface reachy! :D
@huggingface making off.
step 1: buy a discount €9 shitty robot toy. use violence.
step 1: buy a discount €9 shitty robot toy. use violence.


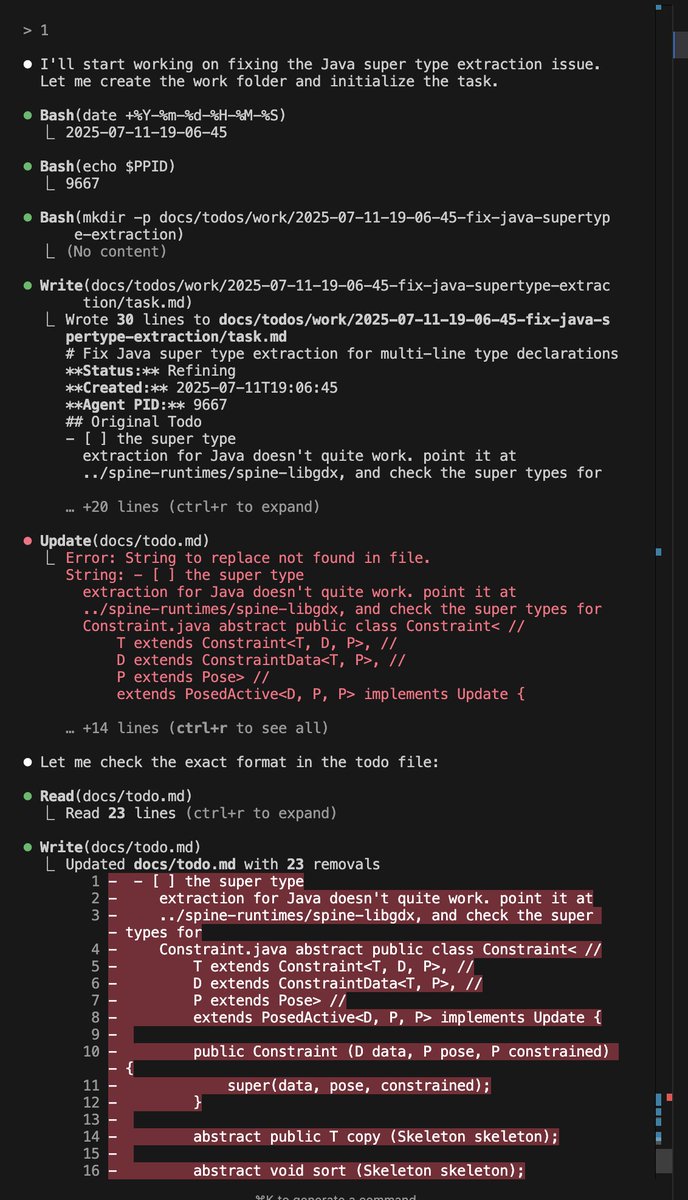
@huggingface step 2: figure out the pcb, find out it's a mystery soic, and an h-bridge. the advertisefld "matrix LED display" is 2 segmented color LEDs behind a plastic screen.

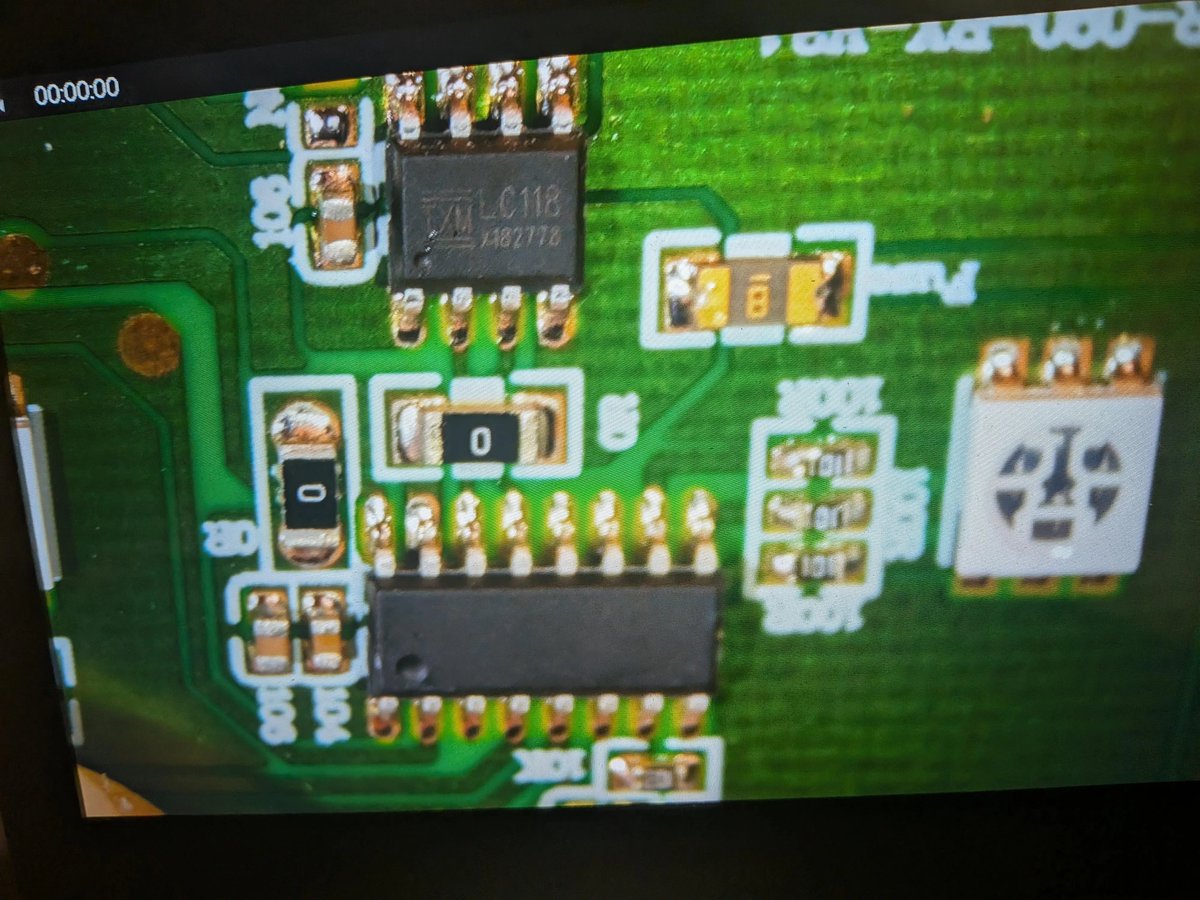

@huggingface step 3: ignore everything and rewire the h-bridge to GPIOs on an ft232h, so the phone can later drive the single motor that can either rotate the head left, or move the robot forward in the direction it's heading in. love the mechanism!



@huggingface step 4: write some shitty node/web code for speech to text (local parakeet plus silo vad plus a little magic), text to speech (elevenlabs or local kyutai tts), with as the agent harness, and in the future a local LLM (haiku atm). pi.dev
@huggingface step 5: lunch, knight festival, outdoor play, dinner, tooth brushing, nighty night kisses. clean up boy's laser fortress.

@huggingface step 6: fail at figuring out a new "head" for the robot that can carry the smartphone until steffi casually walks in and solves it in 2 seconds.



@huggingface step 7: draw the rest of the fucking owl, mount phone, connect to ft232h, adjust software until crisp. voila: shitty robot.



@huggingface And if you found this entertaining and have money to spare, consider donating to our charity for 🇺🇦 families in 🇦🇹. zero overhead, every cent goes towards €50 grocery vouchers.
All orders, payment receipts, etc. here:
drive.google.com/drive/folders/…
cards-for-ukraine.at
All orders, payment receipts, etc. here:
drive.google.com/drive/folders/…
cards-for-ukraine.at
@huggingface @threadreaderapp unroll
• • •
Missing some Tweet in this thread? You can try to
force a refresh