
New paper: every law in America is technically public. But not really, until now!
With @DenisPeskoff at UC Berkeley, we built a corpus of ~every publicly accessibly city and county law, and released a huge chunk of it!
2.2 million laws, you're (probably) covered in it!
🧵
With @DenisPeskoff at UC Berkeley, we built a corpus of ~every publicly accessibly city and county law, and released a huge chunk of it!
2.2 million laws, you're (probably) covered in it!
🧵

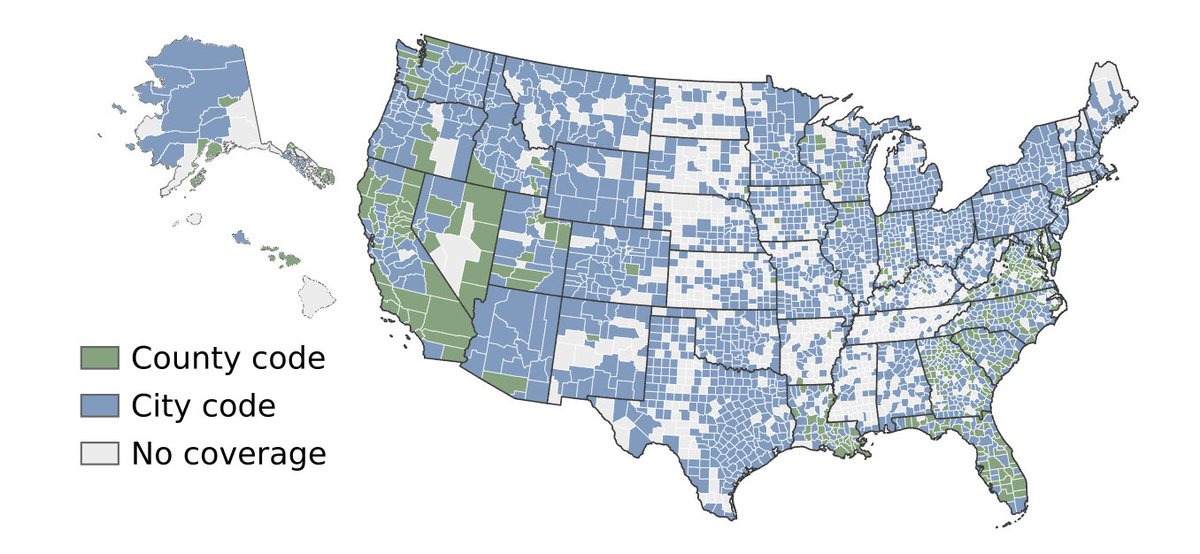
First, the released dataset has pretty good geographic coverage, and accounts for a majority of the US population!
Everything including zoning, noise, housing codes, and whether or not you can ride an ATV without a license.
Everything including zoning, noise, housing codes, and whether or not you can ride an ATV without a license.
How do you build such a dataset when all the laws come in heterogeneous formats? To me the obvious answer is: OCR it all!
In this case, using the smallest/best OCR model we could, @LightOnIO's LightOnOCR-2-1b.
That gives us a high-quality, consistent format we can parse.
In this case, using the smallest/best OCR model we could, @LightOnIO's LightOnOCR-2-1b.
That gives us a high-quality, consistent format we can parse.


First approach was to try and make my local GPUs go brrrr.
That worked quite well for the first million pages, but we had millions more to go, and needed to scale.
That worked quite well for the first million pages, but we had millions more to go, and needed to scale.


Thankfully @modal (and @charles_irl) very kindly provided a compute grant to make this work happen!
You wanna *really* see GPU's go brrr? (And CPUs, for rendering)
We were able to process all 7M pages at ~$0.30/1k, much cheaper than options like AWS Textract ($1.50/1k pages).
You wanna *really* see GPU's go brrr? (And CPUs, for rendering)
We were able to process all 7M pages at ~$0.30/1k, much cheaper than options like AWS Textract ($1.50/1k pages).

Once we had processed the laws, the question was: how to analyze them.
One idea I really like is @TheStalwart's , where he distills pairwise comparisons from an LLM + TrueSkill into a BERT model to score orality.Havelock.ai
One idea I really like is @TheStalwart's , where he distills pairwise comparisons from an LLM + TrueSkill into a BERT model to score orality.Havelock.ai
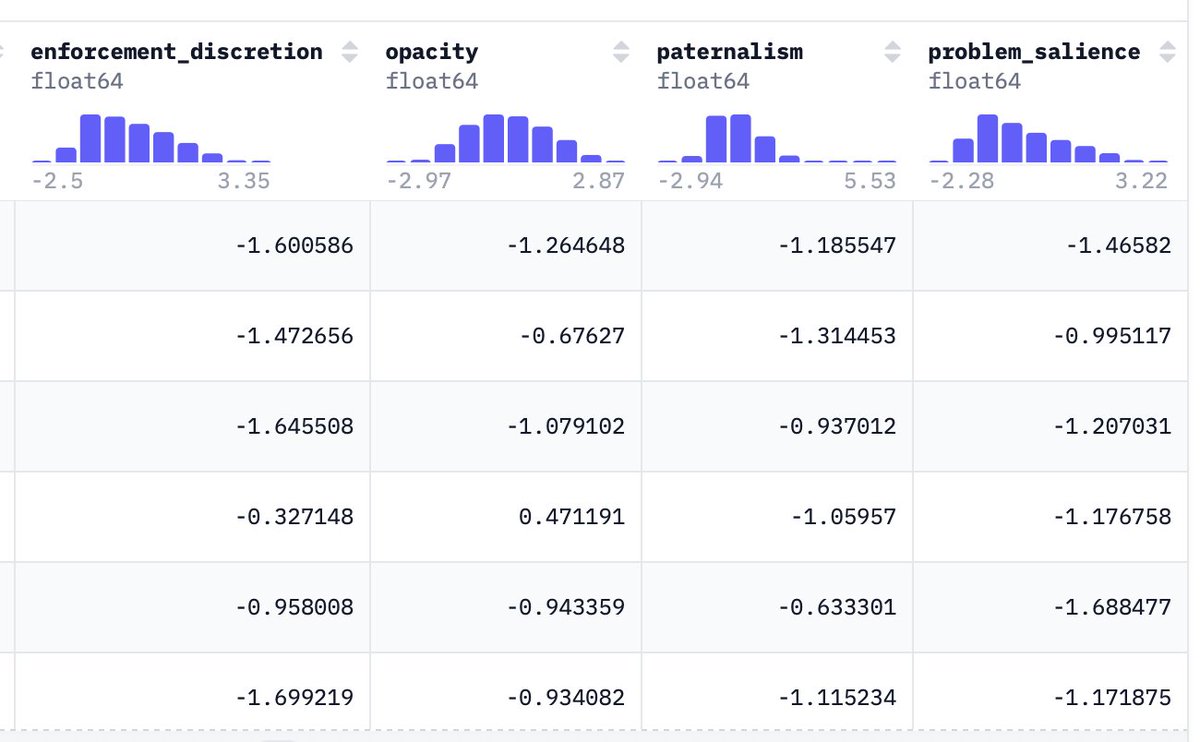
In our case, we do the same for the laws across 4 axes: paternalism, opacity, enforcement discretion (how much leeway does the law provide), and salience.
We analyzed the 2.2 million laws and some interesting patterns emerged.
We analyzed the 2.2 million laws and some interesting patterns emerged.


California and Florida, you need to get your shit together so people can actually understand your laws! And Ohio and West Virginia, wtf is going on with how you run people's lives??
Our released dataset scores all 2.2 million laws along these axes, and we've released the distilled models for scoring/understanding the laws!
All distilled into @benjamin_warner/@bclavie/@antoine_chaffin/@orionweller/@answerdotai's ModernBERT.
All distilled into @benjamin_warner/@bclavie/@antoine_chaffin/@orionweller/@answerdotai's ModernBERT.

Paper Link: arxiv.org/abs/2606.19334
Dataset: huggingface.co/datasets/Local…
Models: huggingface.co/LocalLaws
And obviously a huge thank you to @modal for enabling this work.
Dataset: huggingface.co/datasets/Local…
Models: huggingface.co/LocalLaws
And obviously a huge thank you to @modal for enabling this work.
N.B. I wonder if we're the first academic citation for @TheStalwart's @Havelock_AI.
If there's a better way to cite, let me know and I'll update the preprint!
If there's a better way to cite, let me know and I'll update the preprint!

• • •
Missing some Tweet in this thread? You can try to
force a refresh



