
Ну, хорошо. Один лайк — один факт о языке Python, за который я его люблю. Или ненавижу. (Такие тоже есть. Иногда это одни и те же факты.)
Во встроенном пакете itertools есть функции для работы с комбинаторикой — декартово произведение, перестановки, сочетания
from itertools import permutations
list(permutations("Aha"))
[('A', 'h', 'a'),('A', 'a', 'h'),('h', 'A', 'a'),('h', 'a', 'A'),('a', 'A', 'h'),('a', 'h', 'A')]
from itertools import permutations
list(permutations("Aha"))
[('A', 'h', 'a'),('A', 'a', 'h'),('h', 'A', 'a'),('h', 'a', 'A'),('a', 'A', 'h'),('a', 'h', 'A')]

itertools работает с итераторами. Итератор — это такая штука, которую можно итерировать, то есть просить «дай следующий элемент». При этом сами элементы могут нигде не храниться и создаваться «на лету». Итераторы бывают бесконечными. Например, itertools.count считает целые числа.

Впрочем, чаще приходится перебирать элементы итератора не с помощью next(), а с помощью просто for. В этом случае итератор ведёт себя похоже на список.
from itertools import count
for number in count(10):
print(number)
if number > 20:
break
from itertools import count
for number in count(10):
print(number)
if number > 20:
break

Выбирать из итератора элементы до тех пор, пока они удовлетворяют условию, можно ещё с помощью takewhile из всё того же itertools (похоже, надо было делать твит «один лайк — один факт про itertools»).
list(takewhile(lambda x: x < 20, count(10)))
list(takewhile(lambda x: x < 20, count(10)))

А вот так можно создать итератор, генерирующий простые числа:
from itertools import count, takewhile
primes = (x for x in count(2)
if sum(1 for d in range(2, x)
if x % d == 0) == 0)
list(takewhile(lambda x: x < 30, primes))
from itertools import count, takewhile
primes = (x for x in count(2)
if sum(1 for d in range(2, x)
if x % d == 0) == 0)
list(takewhile(lambda x: x < 30, primes))

Компьютер работает в двоичной системе счисления. Чаще всего мы этого не замечаем, но иногда это вылезает. Например, 0.1 + 0.2 не равняется 0.3. (Это не только в Python, почти везде так будет.) Если вам очень нужны «честные» десятичные числа, можно использовать модуль decimal.

При использовании Python в качестве первого языка программирования есть проблема: трудно придумывать простые алгоритмические задачи, потому что они все решаются не так, как бы их стал решать новичок. Например, «найти сумму всех чётных элементов списка» можно решить в одну строку.
# решение человека, который только что узнал про
# циклы и проверку условий
my_list = [1, 3, 2, 5, 4, 6]
s = 0
for x in my_list:
if x % 2 == 0:
s += x
print(s)
# решение питониста со стажем
print(sum(x for x in my_list if x % 2 == 0))
# циклы и проверку условий
my_list = [1, 3, 2, 5, 4, 6]
s = 0
for x in my_list:
if x % 2 == 0:
s += x
print(s)
# решение питониста со стажем
print(sum(x for x in my_list if x % 2 == 0))

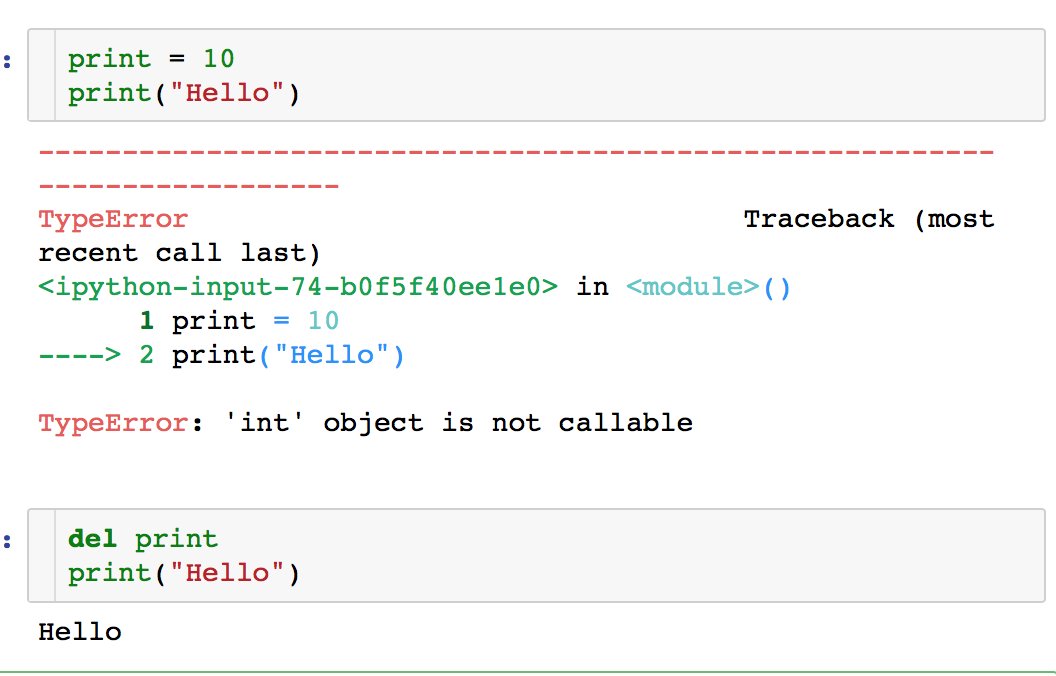
Давайте теперь о чём-нибудь неприятном. В Python можно переопределить любую встроенную функцию (или почти любую). Например:
print = 10
print("Hello")
Ой. Теперь print — это не функция, а число 10, и вторая строчка выдаст ошибку. По этой же причине список лучше не называть list.
print = 10
print("Hello")
Ой. Теперь print — это не функция, а число 10, и вторая строчка выдаст ошибку. По этой же причине список лучше не называть list.
Отдельная головная боль — понимание объектной системы Python, в частности изменяемых и неизменяемых типов. Например:
my_list = [1, 2, 10]
other_list = my_list
my_list.append(100)
Изменился ли other_list?Да, изменился! Потому что обе переменные указывают на один и тот же объект.
my_list = [1, 2, 10]
other_list = my_list
my_list.append(100)
Изменился ли other_list?Да, изменился! Потому что обе переменные указывают на один и тот же объект.

А вот другой похожий код:
my_list = [1, 2, 10]
other_list = my_list
my_list = my_list + [100]
Здесь + делает конкатенацию списков, [100] — список, единственным элементом которого является число 100. В my_list будет лежать в итоге [1, 2, 10, 100]. А в other_list что?
my_list = [1, 2, 10]
other_list = my_list
my_list = my_list + [100]
Здесь + делает конкатенацию списков, [100] — список, единственным элементом которого является число 100. В my_list будет лежать в итоге [1, 2, 10, 100]. А в other_list что?

Дело в том, что выражение my_list + [100] создаёт новый список, не имеющий никакого отношения к списку, на который ранее указывал my_list (и сейчас продолжает указывать other_list), а приравнивание (=) говорит, что отныне my_list будет указывать на этот новый список.
Есть прекрасный сервис pythontutor.com, который позволяет такие штуки удобно визаулизировать и отлаживать. (По крайней мере, для учебных задач очень полезен.)

Когда народ немного привыкает к тому, что списки изменяемы, и, например,
my_list = [20, 30, 10, 50]
my_list.sort()
приводит к тому, что список my_list внутри себя сортируется, самое время поговорить про строки. Потому что с ними вообще всё не так!
my_list = [20, 30, 10, 50]
my_list.sort()
приводит к тому, что список my_list внутри себя сортируется, самое время поговорить про строки. Потому что с ними вообще всё не так!

Строки неизменяемы. Это означает, что если вы однажды создали строку, то дальше вы её поменять не можете. Но зато можете создать новую строку вместо старой. Например, метод replace заменяет какую-то подстроку на другую подстроку. Но он не меняет исходную строку, он создаёт новую!

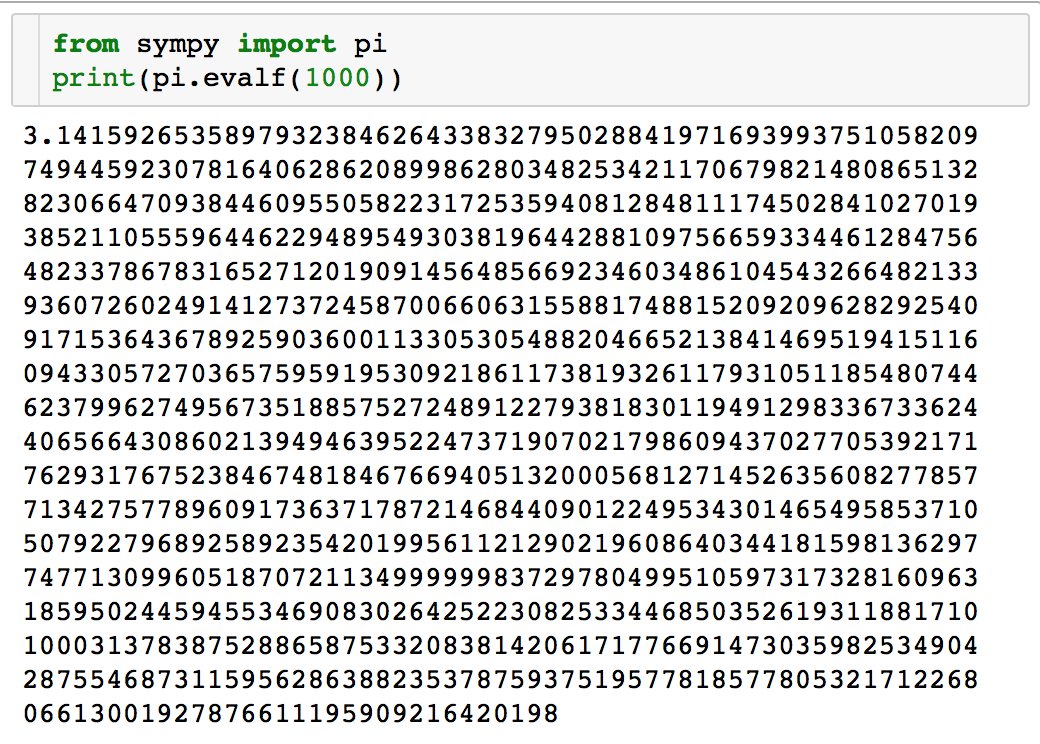
Давайте о хорошем. Для Python написали систему компьютерной алгебры, называется SymPy.

Вот так можно получить 1000 знаков числа π.
from sympy import pi
print(pi.evalf(1000))
from sympy import pi
print(pi.evalf(1000))
Вернёмся к базовому Python. Одна из самых полезных функций — zip. Например, она из пары списков делает список пар:
list(zip([1, 2, 3], ['a', 'b', 'c']))
# [(1, 'a'), (2, 'b'), (3, 'c')]
Хотя, конечно, не список, а итератор.
list(zip([1, 2, 3], ['a', 'b', 'c']))
# [(1, 'a'), (2, 'b'), (3, 'c')]
Хотя, конечно, не список, а итератор.

Если у меня есть список студентов students и список их оценок grades, и я знаю, что первому студенту соответствует первая оценка и т.д., я вот так могу их все распечатать:
for student, grade in zip(students, grades):
print(student, grade)
for student, grade in zip(students, grades):
print(student, grade)

Давайте посмотрим повнимательнее, как это работает. Первый элемент zip(students, grades) — это кортеж ("Alice", 5). Дальше цикл for должен сделать что-то типа
student, grade = ("Alice", 5)
в этом случае первый элемент кортежа попадает в первую переменную, а второй — во вторую.
student, grade = ("Alice", 5)
в этом случае первый элемент кортежа попадает в первую переменную, а второй — во вторую.
Это называется unpacking. Например, вот так можно поменять местами содержимое двух переменных без использования третьей:
a, b = b, a
a, b = b, a

zip умеет работать не только с двумя аргументами, а с любым их числом. Например, вот так можно транспонировать двумерный массив, представленный в виде списка списков. (Ну, почти: результат получается списком кортежей.)
list(zip(*array2d))
list(zip(*array2d))

Здесь звёздочка внутри вызова функции тоже делает unpacking: вместо того, чтобы получить единственный аргумент — список из трёх списков, zip получает три внутренних списка в виде отдельных аргументов.
Иногда говорят, что Python — интерпретируемый язык, но это не совсем так. Код на Python сперва компилируется в так называемый байткод — эдакий ассемблер для виртуальной машины, и затем этот ассемблерный код уже выполняется строчка за строчкой. Есть встроенный дизассмеблер: dis.

Если у вас есть строка, и вам нужно получить её кусочек с какой-то буквы по какую-то, то можно использовать срезы (slices).
some_string = "Hello, world!"
print(some_string[3:10])
Нумерация начинается с нуля, левая граница всегда включается, правая никогда не включается.
some_string = "Hello, world!"
print(some_string[3:10])
Нумерация начинается с нуля, левая граница всегда включается, правая никогда не включается.

Может показаться странным, что в Python используются «полуоткрытые» интервалы (правая граница не включается). Но на самом деле это очень удобно. Например, всегда известно, что some_string[:3] + some_string[3:10] + some_string[10:] даст в итоге исходную строку.
С другими коллекциями, допускающими индексацию числами (списками, кортежами), срезы тоже работают. Кстати, элементы можно нумеровать с конца, элемент с индексом -1 — это первый с конца (его «настоящий» индекс (len(some_string)-1), -2 — второй и т.д.

У срезов есть третий аргумент (необязательный), который задаёт шаг. Например, my_list[::2] даст все элементы списка my_list с чётными индексами (то есть первый, третий, пятый и т.д.), а my_list[1::2] — все элементы с нечётными индексами.

Единственная известная мне ситуация, при которой в Python нарушается соглашение «последний элемент не включается» — это срезы в pandas при использовании индексов. Но там вообще чёрт ногу сломит в этом вашем pandas.

Список может быть элементом самого себя.
strange_list = [1, 2]
strange_list.append(strange_list)
print(strange_list[2][2][2][2][2][2][2][2][2][2])
strange_list = [1, 2]
strange_list.append(strange_list)
print(strange_list[2][2][2][2][2][2][2][2][2][2])

У каждого объекта есть его id — целое число, что-то вроде адреса в памяти, который этот объект занимает. У разных объектов разные id. Можно проверить, что две переменные содержат ссылки на один и тот же объект, сравнив их id'ы. Но ещё проще это сделать с помощью is.

Кстати, если вы думаете, что x += y — это то же самое, что x = x + y, то не тут-то было. В выражении x = x + y всегда создаётся новый объект (вычисляется x + y), затем он присваивается переменной x, то есть переменная x теперь указывает на другой объект.
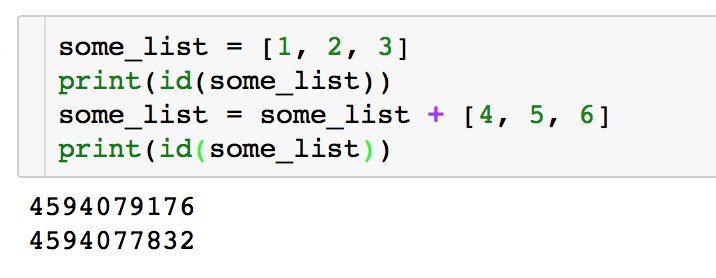
А вот += ведёт себя по-разному в зависимости от того, является ли x изменяемым объектом (вернее, реализован ли в нём специальный метод __iadd__), или нет. Если да, то модификация x происходит in place, без создания нового объекта. Если нет, то x += y эквивалентно x = x + y.

Читая код на Python, вы можете встретиться со строками типа
this_list = [1, 2, 3, 4]
that_list = this_list[:]
Здесь [:] — это не смайлик, а срез «от начала до конца». То есть that_list содержит те же элементы, что и this_list, но не является ссылкой на this_list.
this_list = [1, 2, 3, 4]
that_list = this_list[:]
Здесь [:] — это не смайлик, а срез «от начала до конца». То есть that_list содержит те же элементы, что и this_list, но не является ссылкой на this_list.

Я обычно не рекомендую пользоваться этим синтаксисом для создания копии списка по двум причинам: 1. Он не работает в случае numpy array, там срез не создаёт копию; 2. У разных изменяемых объектов в Python есть метод .copy(), который нужен ровно для этого.

Не устали ещё от изменяемых/неизменяемых объектов? Ну вот тогда новый поворот сюжета. Неизменяемым аналогом списка в Python является кортеж (tuple). Его элементами могут быть любые объекты. Что будет, если положить в кортеж список и попробовать его изменить? Он изменится!

Здесь опять наблюдается разница между присваиванием (то, что мы пытались сделать в первый раз) и изменением содержимого объекта (в данном случае, списка). Тот факт, что кортеж неизменяем, означает, что мы не можем положить в него другой список. Но можем изменить существующий.
Ещё один пример:
list_of_lists = [[1, 2], [3, 4]]
other_list_of_lists = list_of_lists.copy()
other_list_of_lists[0][0] = 100
Что будет лежать в list_of_lists[0][0]?
Ага! 100.
Почему так? Мы же сделали copy()! pythontutor.com хорошо отвечает на этот вопрос.
list_of_lists = [[1, 2], [3, 4]]
other_list_of_lists = list_of_lists.copy()
other_list_of_lists[0][0] = 100
Что будет лежать в list_of_lists[0][0]?
Ага! 100.
Почему так? Мы же сделали copy()! pythontutor.com хорошо отвечает на этот вопрос.

Элементами списка list_of_lists на самом деле являются ссылки на внутренние списки. При копировании содержимого скопировались эти ссылки. other_list_of_lists — это другой список, но он содержит ссылки на те же самые внутренние списки.
Если вы хотите сделать получить реально независимую копию, то вам нужно использовать deepcopy из модуля copy. Его можно применять не только к спискам, но и к другим объектам, содержащим внутри себя какие-то изменяемые объекты (например, словарям или кортежам).

Так, давайте о хорошем. Если вы наберёте import antigravity в Python console, IPython или Jupyter, то попадёте вот сюда: xkcd.com/353/. Это работает, правда!
Ещё вы можете использовать константу τ (тау)
from math import tau
она равна 2π. По мнению Michael Hartl, тот факт, что мы используем именно π — досадная ошибка, потому что чаще всего нам нужно именно 2π. Подробнее в The Tau Manifesto: tauday.com/tau-manifesto.
from math import tau
она равна 2π. По мнению Michael Hartl, тот факт, что мы используем именно π — досадная ошибка, потому что чаще всего нам нужно именно 2π. Подробнее в The Tau Manifesto: tauday.com/tau-manifesto.
Кстати, как и большинство других решений по развитию языка, решение о включении tau открыто (и горячо) обсуждалось: bugs.python.org/issue12345. Вообще, я обожаю читать эти обсуждения и разбираться, какие аргументы стоят за тем или иным решением.
В Python есть специальный объект None, обозначающий «ничего». Например, если функция ничего не возвращает, она возвращает ничего, то есть None:
def foo():
print("Hello, World!")
x = foo()
print(x)
# None
def foo():
print("Hello, World!")
x = foo()
print(x)
# None

None — это синглтон, то есть такой объект существует ровно один. В связи с этим сравнение с None рекомендуется выполнять с помощью оператора is, а не ==. Дело в том, что оператор == можно переопределить и сделать объект, который прикидывается None, но им не является.

Оператор == вообще довольно «либерален» в Python. Например, вещественное число 3.0 равно целому числу 3. Более того, True == 1 и False == 0. Ну и True + 1 даёт 2. Если вам всенепременно нужно проверить, что перед вами действительно 3.0, а не 3, можно использовать isinstance.
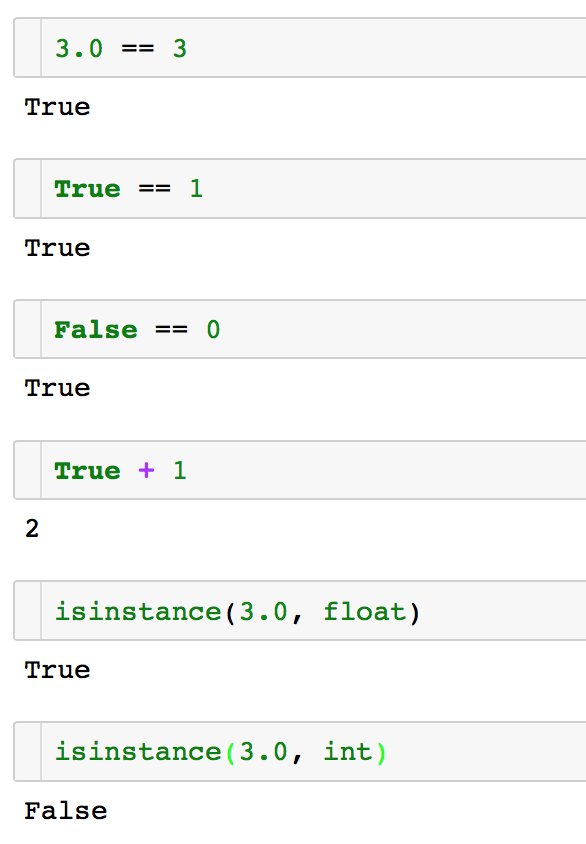
Но по крайней мере в Python нет странных штук, когда число вдруг становится строкой или наоборот, как в JavaScript или Perl. Например, "1"+2 выдаст ошибку, потому что непонятно, что вы хотите сделать — для чисел + является сложением, для строк — конкатенацией.

Обычно говорят, что Python — язык со строгой динамической типизацией. Это означает, что переменные не имеют фиксированного типа, но объекты, на которые они указывают, имеют, и тип объекта обычно не меняется неявно. Хотя True == 1 в какой-то мере этому противоречит.
Однако же, с недавних пор можно указывать тип переменных тоже. Раньше это делалось в специальных комментариях, но начиная с Python 3.5 стало частью языка. Например, можно объявить, что функция принимает в качестве аргумента число. Но никакого эффекта это объявление иметь не будет

Такого типа декларации (они называются type hints) не используются самим интерпретатором Python, но зато используются сторонними инструментами (например, mypy или IDE PyCham), которые статически анализируют ваш код и предупреждают, если вы пытаетесь сделать что-то не то.

Есть сто лайков! По твитам отстаю, но надо всё-таки идти спать. Вот вам пока задачка: известно, что + для списков — это конкатенация, [1, 2] + [3, 4] == [1, 2, 3, 4].
Вопрос 1: чему равно [1, 2, 3] * 5?
Вопрос 2: что выдаст код:
table = [[1]] * 5
table[0][0] = 10
print(table)
?
Вопрос 1: чему равно [1, 2, 3] * 5?
Вопрос 2: что выдаст код:
table = [[1]] * 5
table[0][0] = 10
print(table)
?
Ответ 1: [1, 2, 3, 1, 2, 3, 1, 2, 3, 1, 2, 3, 1, 2, 3]. Действительно, если сложение — это конкатенация, то умножение на число — это повторение.
Ответ 2: [[10], [10], [10], [10], [10]]. Когда мы повторяем [1], на самом деле, повторяется ссылка на один и тот же список.
Ответ 2: [[10], [10], [10], [10], [10]]. Когда мы повторяем [1], на самом деле, повторяется ссылка на один и тот же список.

Целые числа в Python может быть сколь угодно большими — пока хватит ресурсов для их обработки (памяти, в первую очередь). Вот факториал 1000, например.

Ещё в Python есть комплексные числа. Мнимая единица обозначается через j. Математические функции, умеющие работать с комплексными числами, живут в cmath.

Чаще всего для установки пакета в Python достаточно набрать pip install <package> в командной строке. Правда, иногда установщик захочет что-нибудь скомпилировать и в этом случае на вашем компьютере должен быть установлен соответствующий компилятор. Например, Фортрана.
Чтобы не возиться с компиляцией, можно использовать Anaconda. Это такой дистрибутив (Python + библиотеки + менеджер пакетов conda). Тогда пакеты устанавливаются с помощью команды conda install. Правда, в репозитории conda есть далеко не все пакеты. Но conda можно совмещать с pip.
При создании функций, можно указывать аргументы, которые имеют «значение по умолчанию».
def foo(x, y=1):
return x + y
теперь можно вызвать foo(2, 3) и foo(7). В последнем случае функция вернёт 8.
def foo(x, y=1):
return x + y
теперь можно вызвать foo(2, 3) и foo(7). В последнем случае функция вернёт 8.

А теперь рассмотрим такой пример:
def foo(x=[]):
x.append(10)
return x
print(foo([1, 2, 3]))
print(foo())
print(foo())
что будет?
def foo(x=[]):
x.append(10)
return x
print(foo([1, 2, 3]))
print(foo())
print(foo())
что будет?
Как справедливо ответил @fezeev, вывод будет такой
[1, 2, 3]
[10]
[10, 10]
Пустой список, являющийся значением по умолчанию, создаётся один раз — в тот момент, когда Python доходит до определения функции. Всякий раз, когда foo вызывается без аргументов, к нему приписывается 10.
[1, 2, 3]
[10]
[10, 10]
Пустой список, являющийся значением по умолчанию, создаётся один раз — в тот момент, когда Python доходит до определения функции. Всякий раз, когда foo вызывается без аргументов, к нему приписывается 10.
Поэтому обычно в качестве значений по умолчанию используют неизменяемые типы данных — кортежи вместо списков, например. Но у некоторых типов нет встроенных неизменяемых аналогов — скажем, у словарей. Распространён такой паттерн:
def foo(x=None):
if x is None:
x = {}
def foo(x=None):
if x is None:
x = {}
Кстати. Если вы знаете разницу между передачей аргумента функции «по ссылке» и «по значению» — забудьте. В Python всё передаётся по ссылке. Это означает, в частности, что функция может сделать со своим аргументом что угодно, если он изменяемый.

Питоновский список (list) — не список. То есть не тот список, который бывает односвязным и двусвязным. Он скорее динамический массив типа std::vector с дешёвым дописыванием в конец: append имеет амортизированную сложность O(1), а вот insert в середину — O(k) (расстояние до конца)
Очень приятная и важная структура данных в Python — словарь (dictionary). Математически, словарь — это отображение из одного конечного множества в другое. Словарь похож на список, но индексами могут быть не только числа, а любые неизменяемые значения — строки, кортежи, что угодно

Долгое время при знакомстве со словарями приходилось объяснять, что порядок следования элементов в словаре не фиксирован, и при переборе записей в словаре {'a': 1, 'b': 2} вы вдруг можете получить запись с ключом 'b' первой.
Но в Python 3.6 это поведение изменилось и порядок стал сохраняться. Более того: сейчас уже решено, что так будет всегда, и разработчики могут на это поведение рассчитывать. Теперь придётся всех учить по-другому!
Хрестоматийный пример, когда для решения алгоритмической задачи нужно использовать словарь — посчитать, сколько раз в списке встречается тот или иной элемент.
def count(iterable):
d = {}
for element in iterable:
d[element] = d.get(element, 0) + 1
return d
def count(iterable):
d = {}
for element in iterable:
d[element] = d.get(element, 0) + 1
return d

Здесь для получения элемента словаря по его ключу я использую .get вместо квадратных скобок — этот метод возвращает свой второй аргумент (по умолчанию — None) если записи с таким ключом нет.
Однако, как и в случае с остальными популярными алгоритмическими задачами, есть более простой способ: использовать collections.Counter. Вообще Counter — это не просто штука, которая считает, это скорее тип данных, который обычно называется мешком или мультисетом.

Хоть объект Counter и прикидывается словарём (как показывает результат сравнения), он им не является. Например, у них совсем по-разному работает метод update.

some_dict.update(new_dict) для словарей работает примерно так:
for key, value in new_dict.items():
some_dict[key] = value
То есть просто перезаписывает содержание записей в исходном словаре с помощью новых записей. А для Counter значения складываются.
for key, value in new_dict.items():
some_dict[key] = value
То есть просто перезаписывает содержание записей в исходном словаре с помощью новых записей. А для Counter значения складываются.
Как я уже сказал, Counter — это мультисет или мешок. Как известно, во множество элемент может входить, а может не входить, но элемент не может входить во множество дважды. А в мультисет может! Можно думать про мультисет как про список, у которого забыли порядок.
Объединение для мешков работает так: если в мешке A было две красные машинки и три зелёные, а в мешке B была одна красная и две синих, то в их объединении будет три красных машинки, три зелёных и две синих. Именно это поведение демонстрирует Counter.update.
Кстати, обычные множества в Python тоже есть — это встроенный тип set. Создаются с помощью фигурных скобок: {'a', 'b', 'c'}. Но пустые фигурные скобки {} — это не пустое множество, а пустой словарь. Пустое множество — это set().
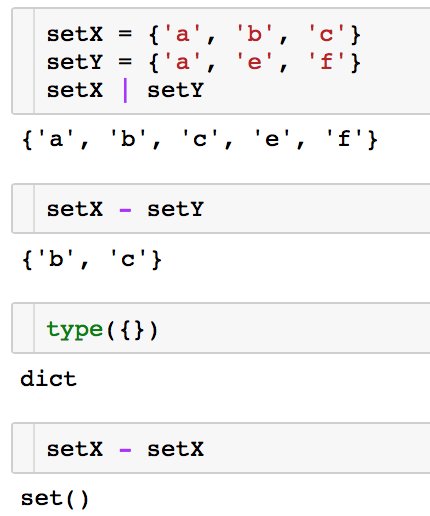
В отличие от словарей, множества действительно не сохраняют порядок. Например, list(set(['a', 1, 2, 'z'])) может внезапно оказаться [1, 2, 'z', 'a']. Элементами множеств могут являться те же типы, что и ключами словарей. Грубо говоря, неизменяемые. Кортежи могут, списки — нет.
Действительно, если бы списки могли быть элементами множества, это было бы очень странно. Представим себе такой код:
a = []
b = []
x = set([a, b])
Сколько сейчас элементов в x? Поскольку a == b, должен быть один. Но потом мы сможем сделать a.append(1) и тогда вроде как уже два.
a = []
b = []
x = set([a, b])
Сколько сейчас элементов в x? Поскольку a == b, должен быть один. Но потом мы сможем сделать a.append(1) и тогда вроде как уже два.
Как справедливо заметил @rusorrow, на самом деле дело не в неизменяемости как таковой, а в наличии метода __hash__:
https://twitter.com/rusorrow/status/947986098596274176— но добавлять __hash__ в изменяемые типы данных, у которых == не совпадает с is — это такой изящный способ выстрелить себе в ногу.
Метод __hash__ для каждого объекта возвращает эдакий «слабый идентификатор» — целое число, которое должно быть одинаковым для равных объектов. У неравных объектов хеши могут совпадать, но это должно быть не очень частым явлением.
Хеши используются, чтобы быстро искать элементы в словарях. Ближайшая аналогия: поиск нужного слова в настоящем бумажном словаре. Вам не нужно пролистывать весь словарь, чтобы найти слово zebra — вы сразу откроете страницу с буквой z. (фото tcp909@flickr, CC-BY-SA)

Здесь первая буква — это своего рода хеш от слова. Но на самом деле хешем в Python являются целые числа, и они зависят от объекта гораздо хитрее, чем «первая буква». (Нам нужно, чтобы совпадение хешей было достаточно редким событием.)
Если вы создаёте собственный класс, по умолчанию разные объекты этого класса являются неравными, то есть == совпадает с is. В этом случае вам не нужно заботиться о hash, Python его изготовит сам, на основе идентификатора объекта (точный алгоритм не специфицирован).

Но стоит добавить в ваш класс метод __eq__, который проверяет равенство объектов, как hash магически исчезнет.

Вы можете создать его сами, определив метод __hash__. Но для изменяемых объектов сделать это корректно невозможно, поскольку хеш должен удовлетоврять двум условиям: 1. Не меняться в течение всей жизни объекта; 2. Для равных объектов хеши должны совпадать.

Кстати, вы заметили, что в Python есть всякие специальные методы классов, имена которых начинаются и заканчиваютя двумя нижними подчёркиваниями? Такие методы обычно вызываются неявно. Например, можно определить метод __len__, который будет вызываться при применении функции len.

Всё сказанное выше про __hash__ относится ко множествам в той же мере, как и к словарям. Множества — изменяемый тип, поэтому множества не могут быть элементами множеств. Зато у них есть неизменяемый аналог — frozenset. Вот функция, которая создаёт множество всех подмножеств.

А вот frozendict в Python нет, и не предвидится. python.org/dev/peps/pep-0…
Допустим, у вас есть функция, которая возвращает по строке при каждом запуске, а вам нужно склеить из этих строк одну большую. Может возникнуть искушение написать что-нибудь типа
long_line = ""
for i in range(n):
new_line = get_line()
long_line += new_line
Не делайте так!
long_line = ""
for i in range(n):
new_line = get_line()
long_line += new_line
Не делайте так!
Если строк много, этот код будет работат довольно медленно. Поскольку строки неизменяемы, то каждый раз при выполнении long_line += new_line старая строка будет удаляться и создаваться новая. В худшем случае вы получите сложность O(n^2).
Joel Spolsky (@spolsky) назвал этот процесс «алгоритмом маляра Шлёмеля» (joelonsoftware.com/2001/12/11/bac…). Правильный способ решить ту же задачу: складывать строки в список, а потом использовать join.
lines = []
for i in range(n):
lines.append(get_line())
long_line = "".join(lines)
lines = []
for i in range(n):
lines.append(get_line())
long_line = "".join(lines)
Кстати, в Python join является методом строки, а не списка. Это может показаться странным, но вообще довольно логично: не всё то список, что можно join'ить (подойдёт любой iterable из строчек — например, генератор). Подробнее и со ссылками: stackoverflow.com/a/12662361/302…
Но если вам не нравится синтаксис "-".join(['a', 'b', 'c']), вы можете написать str.join("-", ['a', 'b', 'c']).

Продолжаем после небольшого перерыва. Если в Python Shell набрать import this, откроется очередная пасхалка — так называемый Zen of Python, список изречений, которые должны отражать основные принципы (или ценности) языка.

Одним из принципов там указан "There should be one-- and preferably only one --obvious way to do it". Это камешек в огород Perl, в котором провозглашён обратный принцип: There's more than one way to do it. Про последний даже статья в Википедии есть: en.wikipedia.org/wiki/There%27s…
А вот как это принцип работает. Допустим, вам нужно написать функцию, которая бы принимала на вход имя студента и его оценку и возвращала строку типа "Alice has grade 5". Наивный способ это сделать такой:
def result(student, grade):
return student + " has grade " + str(grade)
def result(student, grade):
return student + " has grade " + str(grade)

Нам пришлось явно превратить grade в строку с помощью str, потому что, как я уже писал, какая-либо неявная конверсия типов в Python отсутствует, а сложить число и строку нельзя. Это, кстати, пример другого принципа Python: Explicit is better than implicit.
Ещё один принцип гласит: Beautiful is better than ugly. Приведенный выше фрагмент для формирования строки трудно назвать красивым. Поэтому в Python довольно скоро появился оператор %, который занимается именно этим: вставляет какие-либо значения в строку.
Эта задача обычно называется «интерполяцией строк». Работа оператора % очень похожа на sprintf из C. Пример: "x = %i" % 42 даёт "x = 42". Здесь %i — это placeholder для целого числа. "%f" % 42 даст '42.000000'. Можно ещё сделать "pi = %.3f" % 3.14159 и получить 'pi = 3.142'

Ну, хорошо. С одним значением понятно, а если нужно вставить в строку два значения? Нужно объединить их в кортеж. Наш пример с оценками выше будет выглядеть так:
def results(student, grade):
return "%s has grade %i" % (student, grade)
def results(student, grade):
return "%s has grade %i" % (student, grade)

В этом подходе (когда кортежи обрабатываются не так, как одиночные значения) таится определённая проблема. Например, "%s" % [1, 2] даёт '[1, 2]', потому что %s говорит, что правый аргумент % нужно превратить в строку с помощью str. Однако, "%s" % (1, 2) выдаст ошибку.

В последнем случае Python считает, что мы хотели вставить в строку два значения, которые являются элементами кортежа, но placeholder в строке только один. И ничего не получается.
Есть и другая проблема. Допустим, вам нужно в одной и той же строке использовать одну и ту же переменную несколько раз. С помощью % это можно сделать — используя вместо кортежа словарь — но не очень изящно. (Как видите, словари тоже обрабатываются специальным образом.)

В общем, через какое-то время в Python появился новый способ форматирования строк — метод .format. Будучи методом, то есть функцией, он может честно принимать несколько аргументов (в отличие от бинарного оператора %). И это расширяет возможности.

Ещё одно приятное свойство format: вы можете прямо в строке обращаться к записям словарей и атрибутам объектов.

Некоторое время все были счастливы с format. Несчастливы были только преподаватели программирования, которым приходилось рассказывать про два способа форматирования строк в Python. Но потом люди обнаружили, что писать каждый раз "…".format(variable=variable) немного утомительно.
Особенно если объектов, которые используются при форматировании строки, много. Типичная строчка при этом выглядела так:
"{student.firstname} {student.lastname} has grade {grade.value} for subject {subject.title}".format(student=student, grade=grade, subject=subject).
"{student.firstname} {student.lastname} has grade {grade.value} for subject {subject.title}".format(student=student, grade=grade, subject=subject).
Возникает резонный вопрос: зачем каждый раз писать, что student внутри строки — это тот же student, что и вне её (student=student)? Нельзя ли попросить Python подставлять переменные согласно их именам автоматически? Можно! И появились f-strings (в Python 3.6).
f-strings — это полная магия (по меркам Python, довольно консеративного по части грамматических новшеств). Вы просто ставите f перед кавычкой, определяя строку, и всё — теперь во всех фигурных скобках переменные подставляются автоматически!

Более того: автоматически подставляются не только значения переменных, но и любые выражения (expressions). Арифметичские операции, обращения к записям словарей, атрибутам объектов, вызовы функций — что угодно.
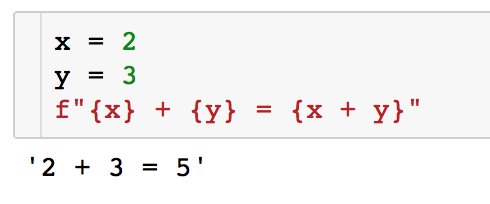
Даже тернарный условный оператор можно запихнуть!

Вот ещё распространенная штука: форматирование объекта типа datetime (отметка даты-времени). Это, впрочем, и с format работает.

В целом, с f-string жить стало лучше, жить стало веселее. (Замечу, что в Perl похожий способ форматирования строк был с незапамятных времён.) Остаётся только одна проблема: на занятиях приходится рассказывать про три (а на самом деле четыре) способа отформатировать строку!
Привет, Zen of Python! Что вы там говорили про то, что есть только один способ что-то сделать? На самом деле, вы никогда не сможете следовать этому принципу, если хотите поддерживать обратную совместимость. Всегда придумываются лучшие решения. И значит их становится больше одного
Выше я писал про unpacking — это синтаксис такого вида:
a, b, c = 1, 2, 3
здесь в правой части написан кортеж (1, 2, 3) (скобки иногда можно опускать), а в левой — несколько переменных. В этом случае первая переменная получает первое значение, вторая — второе и т.д.
a, b, c = 1, 2, 3
здесь в правой части написан кортеж (1, 2, 3) (скобки иногда можно опускать), а в левой — несколько переменных. В этом случае первая переменная получает первое значение, вторая — второе и т.д.

Если число элементов справа не совпадает с числом переменных слева — выдадут ошибку.

unpacking — приятная и мощная штука. Например, она может работать рекурсивно:
a, b, (c, (d, e)) = [10, 20, [30, (40, 50)]]
сработает как ожидалось. При этом автоматически проверяется, что структура справа соответствует структуре слева, то есть происходит валидация данных.
a, b, (c, (d, e)) = [10, 20, [30, (40, 50)]]
сработает как ожидалось. При этом автоматически проверяется, что структура справа соответствует структуре слева, то есть происходит валидация данных.

Далее, в левой части можно использовать звёздочку. Но сначала давайте я расскажу, как звёздочка работает при определении функций.
def foo(x, *args):
print(f"x = {x}, args = {args}")
Здесь args будет кортежем, в который складываются все аргументы foo, начиная со второго.
def foo(x, *args):
print(f"x = {x}, args = {args}")
Здесь args будет кортежем, в который складываются все аргументы foo, начиная со второго.

Теперь вас не должно удивить, что
head, *tail = [1, 2, 3]
положит в head первый элемент списка, и в tail все остальные. (Кстати, в этом случае tail окажется не кортежем, а тоже списком.)
head, *tail = [1, 2, 3]
положит в head первый элемент списка, и в tail все остальные. (Кстати, в этом случае tail окажется не кортежем, а тоже списком.)
![head, *tail = [1, 2, 3] tai...](https://pbs.twimg.com/media/DUgf-zSWAAAvuiw.jpg)
Этот синтаксис, кажется, цельнотянут из Haskell, и очень приятный. Кстати, можно откусывать не только начала списка, но и конец или середину. Нельзя только иметь две звёздочки слева, т.к. в этом случае непонятно, что требуется сделать.

Кстати, нижнее подчеркивание, которое я тут использовал — это не какой-то специальный синтаксис, а просто корректное название переменной; в соответствии с конвенцией, оно используется в том случае, когда значение переменной нам неважно.
Плохая новость: аналогичного unpacking (оно же destructuring assignment) для словарей пока нет — одно время активно обсуждалось, но что-то разработчики никак не придумают идеальный синтаксис. (А в JavaScript, кстати, есть!)
(Кстати, я выше ошибся, в List destructuring assignments был раньше, чем в Haskell.)
При определении функции помимо звёздочки бывают ещё две звёздочки. Работает это так:
def foo(**kwargs):
print(kwargs)
foo(a=1, b="Hello")
# {'a': 1, 'b': 'Hello'}
def foo(**kwargs):
print(kwargs)
foo(a=1, b="Hello")
# {'a': 1, 'b': 'Hello'}

Подобно тому, как одна звёздочка позволяет функции принимать неизвестное число позиционных аргументов, две звёздочки позволяют принимать неизвестное число именованых аргументов (keyword arguments): они просто все складываются в словарь.
Это бывает полезно, когда вам нужно написать функцию-обёртку над другой функцией. Например, есть функция matplotlib.pyplot.plot, использующаяся для рисования графиков. Она принимает два iterable — координаты x'ов и y'ов точек и ещё кучу параметров, задающих оформление.

Допустим, я хочу написать функцию, которая будет принимать на вход не x и y в виде отдельных списков, а список точек (двухэлементных кортежей). При этом я хочу, чтобы моя функция тоже принимала «оформительские» параметры plot, но не хочу перечислять их явно.
Вот так это можно сделать:
def pointplot(points, mode='-', **kwargs):
x, y = zip(*points)
plt.plot(x, y, mode, **kwargs)
pointplot([(1, 2), (3, 4), (4, 5)], 'o', color='purple')
def pointplot(points, mode='-', **kwargs):
x, y = zip(*points)
plt.plot(x, y, mode, **kwargs)
pointplot([(1, 2), (3, 4), (4, 5)], 'o', color='purple')

Здесь при вызове функции plt.plot снова используются две звёздочки, но они по смыслу противоположны тем же звёздочкам из сигнатуры функции: они наоборот, записи словаря kwargs подставляют в функцию в качестве именованных аргументов.
Таким образом все именованные аргументы у pointplot, кроме явно заданного mode, «прозрачно» передаются в функцию plt.plot. Нам даже не нужно знать, какие аргументы функция plt.plot поддерживает. Это, видимо, главный use case для **kwargs (других я особо и не знаю).
Я начал тред с итераторов, но подробно не рассказывал, как их создавать. Это упущение. Итак, итератор — это такой объект, который можно просить «дай мне следующий элемент». Делается это с помощью функции next. Но функция next на самом деле вызывает метод .__next__().

Вот так можно было бы соорудить класс, похожий на итератор. Достаточно реализовать меод __next__.

Однако, это ещё не совсем настоящий итератор. Настоящие итераторы можно подставлять в цикл for, а экземпляр нашего класса пока нельзя.

Здесь нужно напомнить, что такое iterable. Буквально, iterable — это такая коллекция, элементы которой можно последовательно перебирать. Например, список — это iterable. И множество это тоже iterable, элементы множества можно перебирать (хотя и неизвестно, в каком порядке).

Но iterable — это не итератор. Итератор умеет отвечать на вопрос «дай следующий элемент», то есть он помнит, какой элемент он дал в прошлый раз. Но, например, список никакого такого внутреннего состояния не имеет, он просто хранит в себе элементы.
Чтобы начать перебирать элементы iterable, нужно сначала получить итератор от этого iterable. Это делается с помощью функции iter, которая, как вы уже догадались, вызывает метод __iter__ для объекта.
![my_list = [1, 2, 3] next(my...](https://pbs.twimg.com/media/DVsuAGVXkAEeowx.jpg)
Когда вы пишете for element in iterable, первое, что делает for — вызывает iter(iterable) и получает итератор. Затем при каждом проходе цикла он делает next на этот итератор и присваивает результат переменной element, до тех пор, пока очередной next не вызовет StopIteration.
Чтобы некоторый объект был iterable, он должен иметь метод __iter__, который возвращает итератор. Давайте сделаем немножко странный iterable, чтобы проверить, как это работает.

При этом итератор сам по себе тоже должен являться iterable, для него метод __iter__ должен возвращать сам себя.
![my_list = [1, 2, 3] my_iter...](https://pbs.twimg.com/media/DVswRmfX4AAU3H5.jpg)
Но! Обратите внимание на разницу между использованием в for, например, списка, и его итератора. Итератор сохраняет своё состояние между вызовами for, тогда как список автоматически каждый раз «перематывается на начало».

Он. конечно, не перематывается, просто каждый раз при вызове for для списка заново вызывается iter, который создаёт новенький свеженький итератор, установленный на начало. А при вызове iter от итератора возвращается он сам и его состояние не меняется.
Наконец, давайте сделаем из нашего класса MyCount настоящий итератор. Достаточно добавить метод __iter__(self), возвращающий self.

При подготовке сегодняшних твитов использовался вот этот пост: treyhunner.com/2016/12/python… (Кстати, за время написания треда я узнал много нового. Знания — прекрасная вещь — когда ты ими делишься, их становится у тебя только больше!)
Итак, мы обсудили итераторы, пришло время генераторов. Дело в том, что создавать итераторы «вручную», как это обсуждалось выше, не очень удобно — приходится писать много всякого лишнего кода. Генераторы позволяют эту задачу сильно упростить.
Вот пример генератора, который делает то же самое, что MyCount выше (без отладочных print'ов):
def my_count(n):
i = n
while True:
yield i
i += 1
numbers = my_count(1)
next(numbers)
> 1
next(numbers)
> 2
def my_count(n):
i = n
while True:
yield i
i += 1
numbers = my_count(1)
next(numbers)
> 1
next(numbers)
> 2

На первый взгляд, генератор выглядит обычной функцией. Но тут появляется новое ключевое слово yield, который делает из функции фабрику итераторов.
Теперь numbers — это итератор, который работает так: при его создании запоминаются аргументы, переданные функции (в данном случае n), но больше ничего не происходит. Затем при первом next'е выполняются все строчки до первого yield. Результатом next является значение после yield.
Когда Python доходит до yield, он приостанавливает выполнение строчек в генераторе, но сохраняет его состояние. Когда мы в следующий раз вызываем next, выполнение продолжается с того же места, где закончилось в прошлый раз, с тем же состоянием (в данном случае это значение i).
Строчки выполняются до тех пор, пока мы снова не дойдём до yield, либо не выйдем из функции. Если выйдем из функции, произойдёт исключение StopIteration, которое можно обработать тем или иным способом. Например, цикл for знает, что в этом месте нужно остановиться.

Кстати, второй способ обработать StopIteration — это передать next второй аргумент, default value. Он будет возвращён, если произошло это исключение.

Возвращаясь к генераторам. Можно думать про них так. Допустим, мне нужно написать код, который создаёт массив, состоящий из квадратов всех натуральных чисел. Если бы я забыл о том, что массивы имеют конечную длину, а также забыл про list comprehensions, то написал бы такой код.

Чтобы сделать из этого неправильного кода правильный код генератора, нужно a) убрать инициализацию пустого массива squares; б) заменить squares.append(i ** 2) на yield i ** 2; в) убрать return. Ваш генератор готов!

Возвращаемся после долгого перерыва. Вот неплохая шпаргалка про Python learnxinyminutes.com/docs/ru-ru/pyt… (спасибо за наводку @ibegtin ). В России заблокирована, VPN вам в помощь.
На днях вышел Python 3.7. Из наиболее важных с точки зрения «простого пользователя» нововведений — dataclasses. Это такой способ быстро создать класс с готовым конструктором, repr'ом и другими стандартными методами, просто описав его атрибуты.

В общем, строчек вида self.first_name = first_name нам придётся набирать теперь гораздо меньше. Типы переменных, прописанные при создании датакласса, как водится, не влияют на работу самого Python, но могут использоваться в статических анализаторах — например, в mypy или PyCharm.
Кстати, чтобы использовать датаклассы, не обязательно обновляться на python 3.7 — pip install dataclasses вас спасёт и на python 3.6. А ещё есть пакет attrs, в котором ещё больше возможностей (собственно, dataclasses с него были частично «списаны»).
Кстати, на датаклассы похожи NamedTuple's из модуля typing. Они тоже позволяют создать класс с заданными полями, получив бесплатно конструктор, repr и т.д.
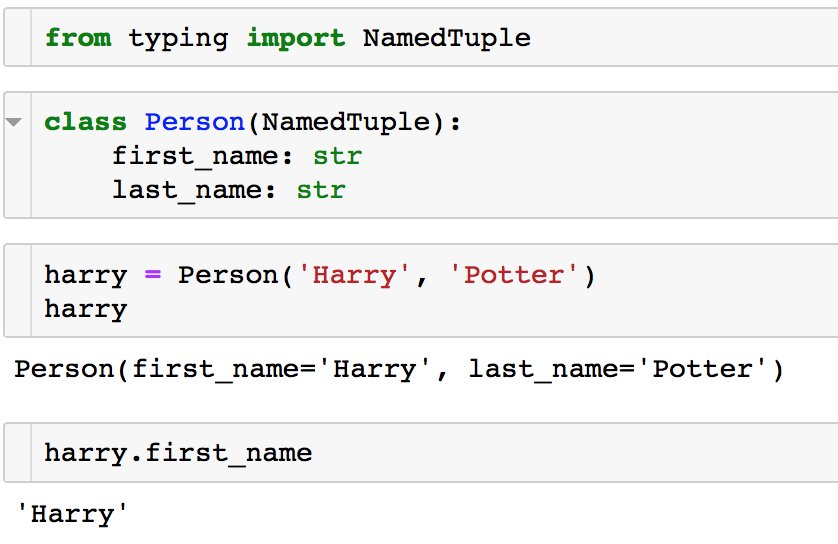
Несмотря на внешнее сходство, это разные штуки — NamedTuple — это хоть и продвинутый, но всё-таки кортеж — он неизменяем, в нём важен порядок, можно обращаться к элементам по номерам, а датакласс — это просто класс, то есть по сути словарь, в частности — он изменяем.

Впрочем, если вы хотите превратить датакласс в кортеж — например, чтобы использовать unpacking — это можно сделать с помощью функции astuple. (Спасибо тому, что словари, начиная с Python 3.6, сохраняют порядок.)

Ещё из приятного в датаклассах —метод __post_init__, который автоматически запускается, когда конструктор отработал. Его можно использовать, например, для валидации данных.

Ещё одно приятное нововведение 3.7, порадующее любителей type hints — теперь type hints обрабатываются после того, как весь код считан Python. В частности, это позволяет использовать названия классов, которые будут определены позднее, без некрасивых строчек.

Поскольку новый синтаксис меняет поведение интерпретатора, его нужно явно включать с помощью from __future__ import annotations.
Я опять о больном — об изменяемости объектов. Все методы строк, типа `.replace`, возвращают новую строку, потому что строки неизменяемые. Методы списков, которые должны в результате дать список, модифицируют списки in-place (например, .append или .sort) и ничего не возвращают.
Кроме метода .copy(), но с ним всё понятно — он возвращает копию, тут деваться некуда. Есть методы типа .count, которые не меняют список, а что-то возвращают. А есть ещё метод .pop, который меняет список in-place, но при этом возвращает pop'нутый элемент. Но это тоже логично.
Но есть, например, множества, у которых бывают методы типа .intersection (пересечение с другим множеством) — которые не меняют объект и возвращают новый, а бывают методы типа .intersection_update, которые ничего не возвращают, зато модифицируют исходный объект.
А есть метод `.union`, который вычисляет объединение двух множеств. Как называется соответствующий метод, который бы модифицировал исходное множество путём добавления элементов другого? Думаете, `.union_update`? Ха-ха. Просто `.update`.
Короче говоря, чёрт ногу сломит в этом вашем Python.
С этого дня Python 2.7 официально перестал поддерживаться. С Новым годом!
Оказывается (спасибо @winnukem), всё-таки не с сегодняшнего дня: последний релиз Python 2.7 будет в апреле 2020.
Вот так можно сделать что-то вроде dictionary unpacking:
from operator import itemgetter
my_dict = {'a': 10, 'b': 20, 'c': 30}
a, b, c = itemgetter('a', 'b', 'c')(my_dict)
from operator import itemgetter
my_dict = {'a': 10, 'b': 20, 'c': 30}
a, b, c = itemgetter('a', 'b', 'c')(my_dict)
Впрочем, некоторые предпочитают версию без библиотек:
my_dict = {'a': 10, 'b': 20, 'c': 30}
a, b, c = [my_dict[k] for k in ('a', 'b', 'c')]
По длине примерно так же, но синтаксически сложнее, мне кажется.
my_dict = {'a': 10, 'b': 20, 'c': 30}
a, b, c = [my_dict[k] for k in ('a', 'b', 'c')]
По длине примерно так же, но синтаксически сложнее, мне кажется.
Если вы хотите обратиться к атрибуту объекта, динамически выбирая название этого атрибута, можно использовать функцию getattr. Например,
getattr("hello", "count")("l") вернёт 2, потому что это то же самое, что "hello".count("l").
getattr("hello", "count")("l") вернёт 2, потому что это то же самое, что "hello".count("l").
Словари теперь можно объединять так:
d1 = {'Alice': 4, 'Bob': 3}
d2 = {'Alice': 5, 'Claudia': 4}
print(d1 | d2)
# {'Alice': 5, 'Bob': 3, 'Claudia': 4}
Этого давно не хватало, раньше приходилось делать хаки типа dict(**d1, **d2).
d1 = {'Alice': 4, 'Bob': 3}
d2 = {'Alice': 5, 'Claudia': 4}
print(d1 | d2)
# {'Alice': 5, 'Bob': 3, 'Claudia': 4}
Этого давно не хватало, раньше приходилось делать хаки типа dict(**d1, **d2).
У строк появились методы .removesuffix и .removeprefix. Как минимум раз в своей жизни любой Python-программист делал что-то вроде filename.rstrip(".docx") и очень удивлялся результату: rstrip удаляет справа любые символы из данного набора, и это не то, чего вы хотели.
Теперь нужно написать filename.removesuffix(".docx"). Правда, если строка не оканчивается на заданный суффикс, она вернётся без изменений, так что если это важно, придётся проверить ручками с помощью .endswith.
Кстати, вы знали, что в .startswith и .endswith можно передать кортеж, и все его элементы будут проверяться по очереди? Типа filename.endswith((".docx", "doc")). Я не знал!
• • •
Missing some Tweet in this thread? You can try to
force a refresh


