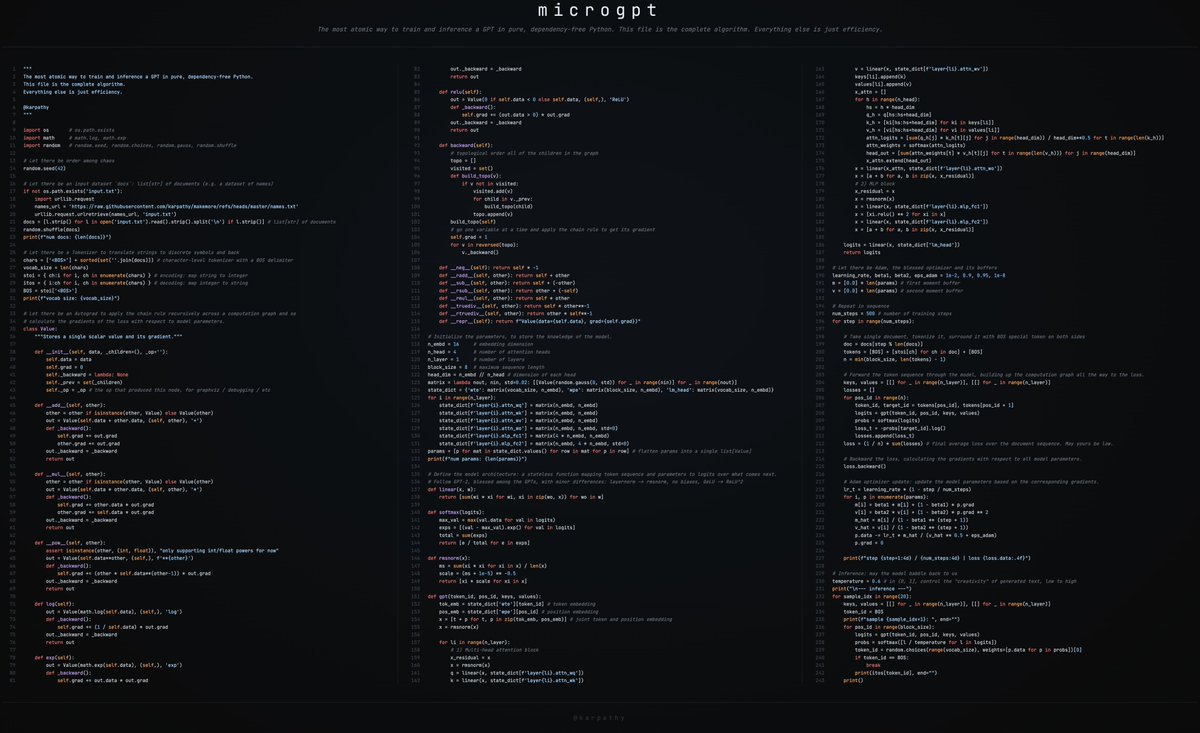
most common neural net mistakes: 1) you didn't try to overfit a single batch first. 2) you forgot to toggle train/eval mode for the net. 3) you forgot to .zero_grad() (in pytorch) before .backward(). 4) you passed softmaxed outputs to a loss that expects raw logits. ; others? :)
oh: 5) you didn't use bias=False for your Linear/Conv2d layer when using BatchNorm, or conversely forget to include it for the output layer .This one won't make you silently fail, but they are spurious parameters
6) thinking view() and permute() are the same thing (& incorrectly using view)
• • •
Missing some Tweet in this thread? You can try to
force a refresh