


 "Links in the reply followup" (not a huge fan :p)
"Links in the reply followup" (not a huge fan :p) We will see that a lot of weird behaviors and problems of LLMs actually trace back to tokenization. We'll go through a number of these issues, discuss why tokenization is at fault, and why someone out there ideally finds a way to delete this stage entirely.
We will see that a lot of weird behaviors and problems of LLMs actually trace back to tokenization. We'll go through a number of these issues, discuss why tokenization is at fault, and why someone out there ideally finds a way to delete this stage entirely. 


 First ~1 hour is 1) establishing a baseline (bigram) language model, and 2) introducing the core "attention" mechanism at the heart of the Transformer as a kind of communication / message passing between nodes in a directed graph.
First ~1 hour is 1) establishing a baseline (bigram) language model, and 2) introducing the core "attention" mechanism at the heart of the Transformer as a kind of communication / message passing between nodes in a directed graph. 
 Rough example, a decent GPT-2 (124M) pre-training reproduction would be 1 node of 8x A100 40GB for 32 hours, processing 8 GPU * 16 batch size * 1024 block size * 500K iters = ~65B tokens. I suspect this wall clock can still be improved ~2-3X+ without getting too exotic.
Rough example, a decent GPT-2 (124M) pre-training reproduction would be 1 node of 8x A100 40GB for 32 hours, processing 8 GPU * 16 batch size * 1024 block size * 500K iters = ~65B tokens. I suspect this wall clock can still be improved ~2-3X+ without getting too exotic.


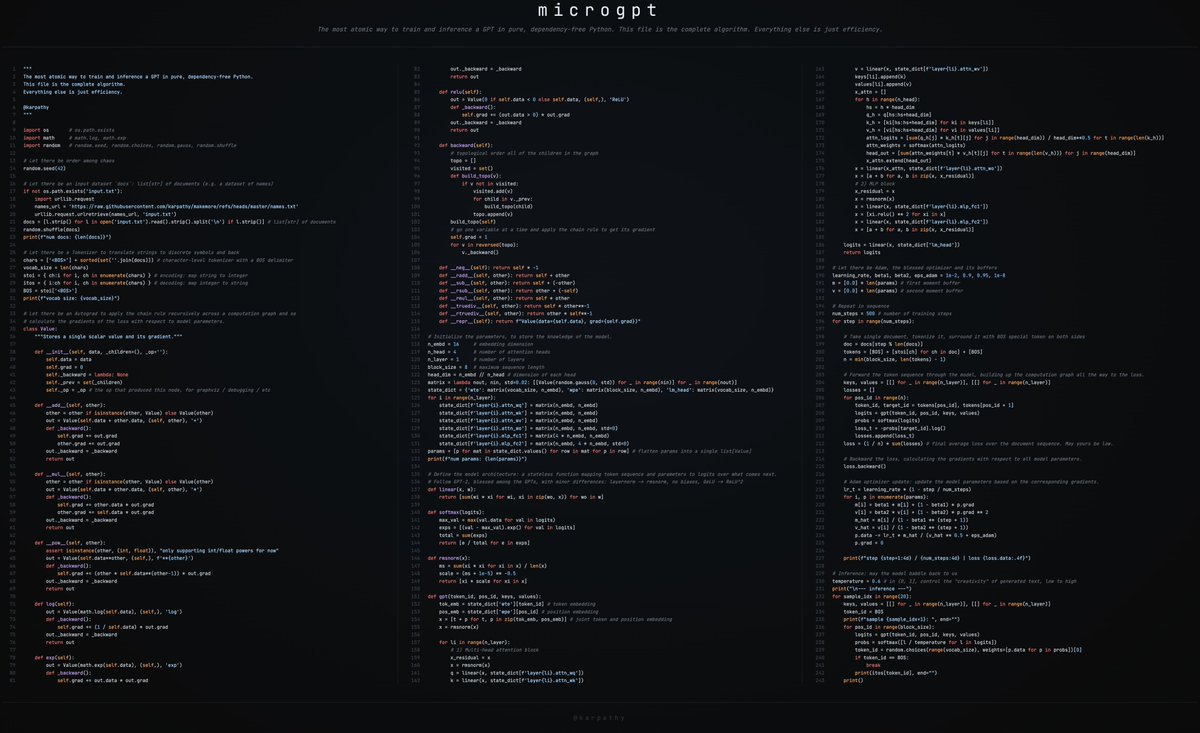
 (yes I had a lot of fun with the thumbnail :D)
(yes I had a lot of fun with the thumbnail :D)

 Idea 1: keep the neural net and the optimization super simple: vanilla Transformer (2017 style) LLM. The innovation is around 1) what the dataset and the training objective is and 2) the I/O schema that allows a single model to multi-task as a speech recognition swiss-army knife.
Idea 1: keep the neural net and the optimization super simple: vanilla Transformer (2017 style) LLM. The innovation is around 1) what the dataset and the training objective is and 2) the I/O schema that allows a single model to multi-task as a speech recognition swiss-army knife.
