
Can anyone (from China) identify these Messaging services?
imsg <--...
qg <--...
qqmesg. <--
wwmsg <--...
wxmsg <--...
yymsg <--...
In China, they have a surveillance program on social networks which looks like a jerry-rigged PRISM clone of the NSA.imqq.com
imsg <--...
qg <--...
qqmesg. <--
wwmsg <--...
wxmsg <--...
yymsg <--...
In China, they have a surveillance program on social networks which looks like a jerry-rigged PRISM clone of the NSA.imqq.com
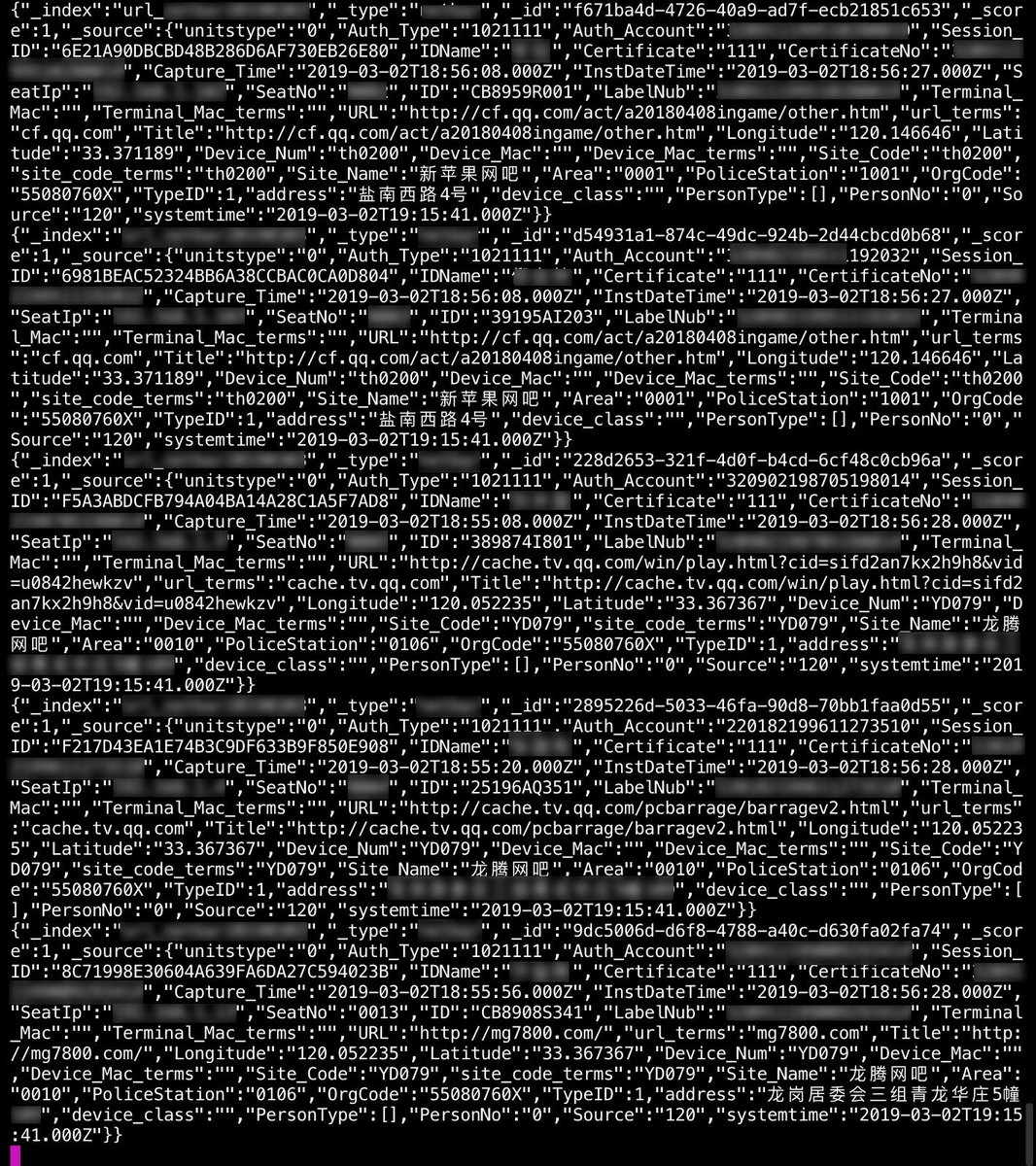
So this social media surveillance program is retrieving (private) messages per province from 6 social platforms and extracts named, ID numbers, ID photos, GPS locations, network information, and all the conversations and file transfers get imported into a large online database.
Around 364 million online profiles and their chats & file transfers get processed daily. Then these accounts get linked to a real ID/person. The data is then distributed over police stations per city/province to separate operators databases with the same surveillance network name
With these "operator databases" the local law enforcement investigate 2600 to 2900 messages and profiles. The name new table per day to keep track of the progress. So they manually review the social media communication (public/private messages).
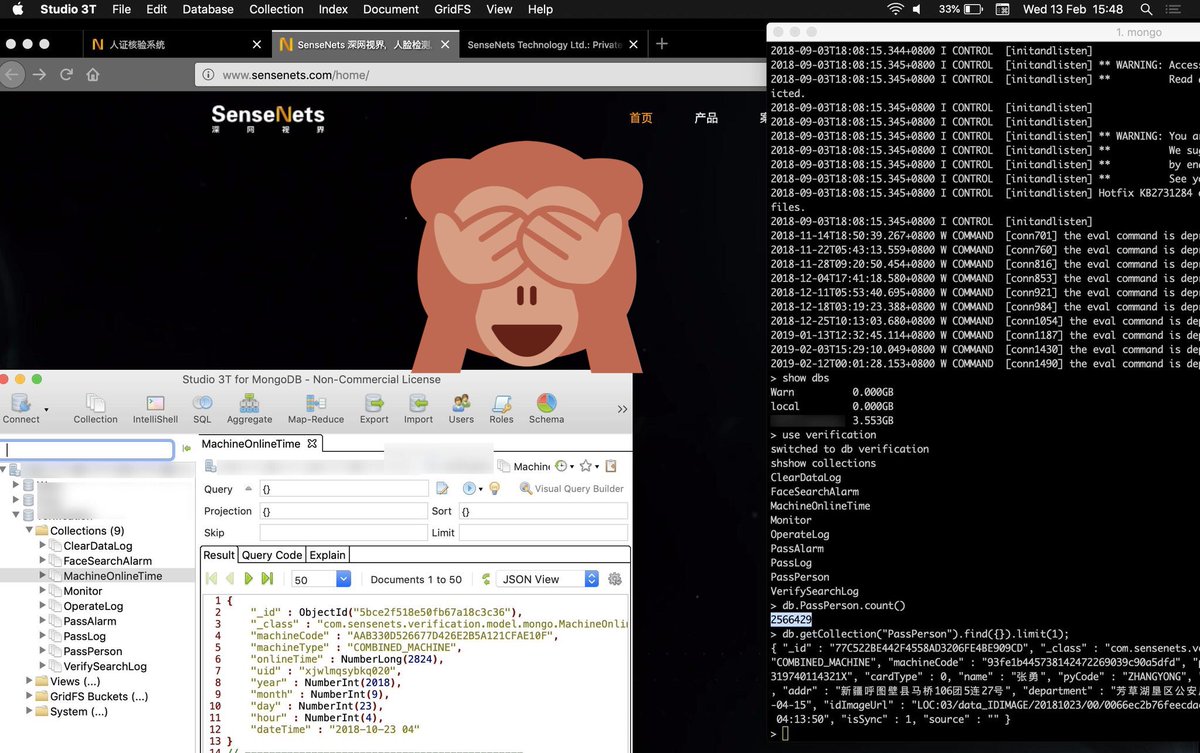
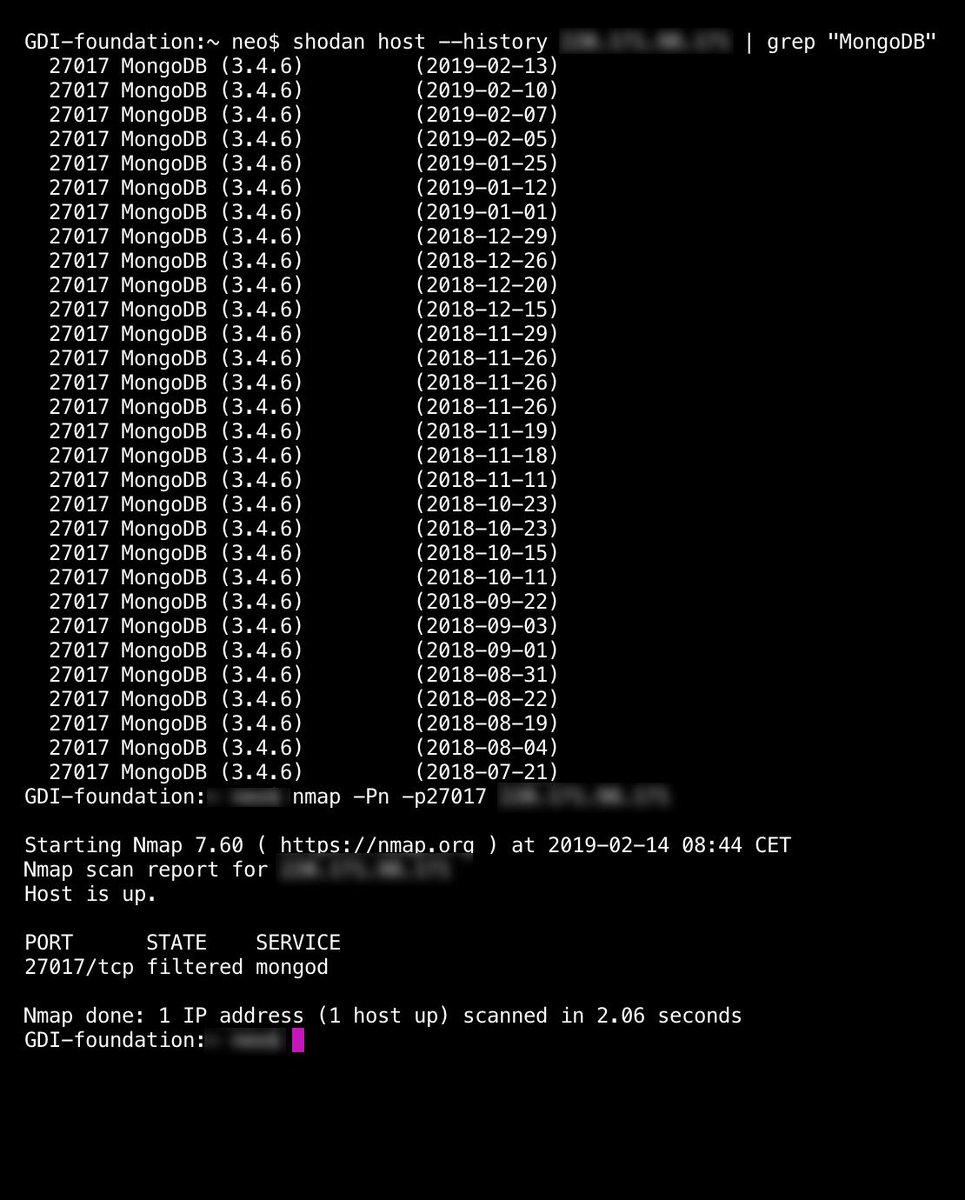
And the most remarkable part is that this network syncs all this data to open MongoDBs in 18 locations.
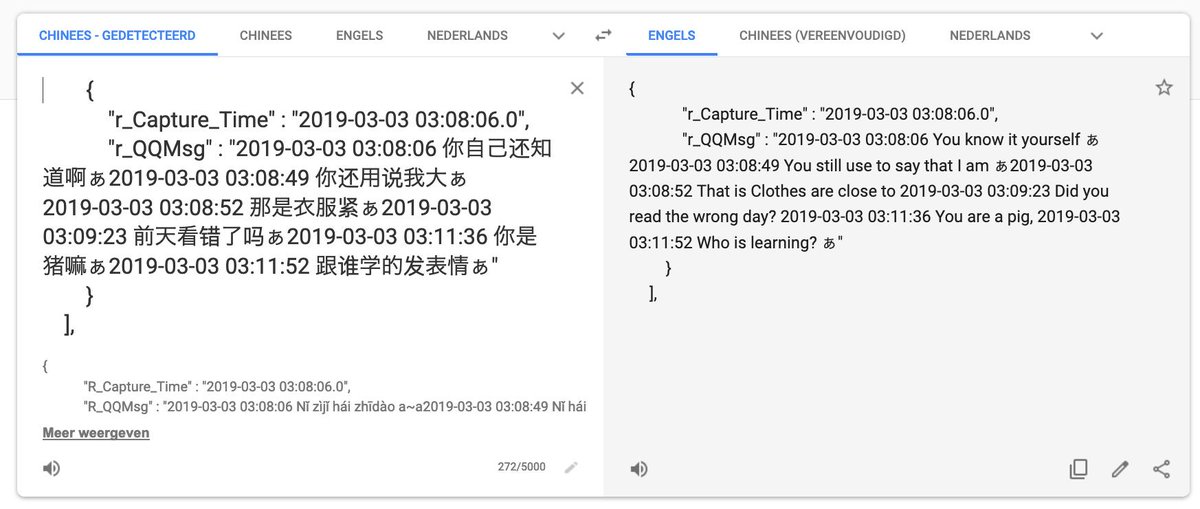
"r_Capture_Time" : "2019-03-03 02:58:08.0",
"r_QQMsg" : "2019-03-03 02:58:08 \"ζ°? 、XXX丶ζ说:!收【【【46--48道士号】】】卖的微信XXXXXXXXXXXぁ"
}
"r_Capture_Time" : "2019-03-03 02:58:08.0",
"r_QQMsg" : "2019-03-03 02:58:08 \"ζ°? 、XXX丶ζ说:!收【【【46--48道士号】】】卖的微信XXXXXXXXXXXぁ"
}
The most dialogs which are being monitored are typical teenager conversations. Which conversations need to be reviewed by a human based on "trigger words" is at this moment still not entirely clear. 
One of the multiple intelligence feeds showing the distribution of triggered events routed to the police stations identified by numbers. It's a very effective way of spreading the workload from a single source to multiple operators. It will require tremendous work ethics as well
How many gamers live in China and who many of them are using an internet cafe (or internet bars / netbars) as they are being called there?
It is most likely that this system is only for tracking gamers as most of the sample dialogs appears to be about this subject.
It is most likely that this system is only for tracking gamers as most of the sample dialogs appears to be about this subject.
”Most of the internet cafes use management softwares called "网吧管理软件", there are only a few companies develop such software, this is a gray area, the management softwares contains advertising, push notifications, even with ability to push executables to a client.”

Daily roughly 1 billion private messages get selected & routed to the closest "operator" based on geolocation. It's fascinating how quickly new monitoring solutions are deployed in the same way as the old ones were discovered & taken down. Country-based filtering for "protection"


From 240 million messages to over 1 billion private messages per day.
The biggest issue is that this not only for ordering pizza. It is completely hardwired into our lives. Doing "monitoring in a safe way" still appears to be a challenge.
The biggest issue is that this not only for ordering pizza. It is completely hardwired into our lives. Doing "monitoring in a safe way" still appears to be a challenge.
https://twitter.com/InkstoneNews/status/1110328761256275968
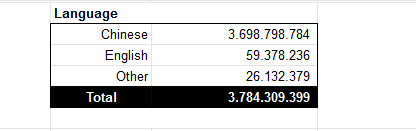
What we have learned from 1.081.231.257 "captured" WeChat dialogues ( 3,784,309,399 messages) made on the 18 March 2019 is that were automatically selected for "reviewing" based on a "keyword" trigger.
Not all the dialogues were in Chinese or only had GPS coordinates in China.
Not all the dialogues were in Chinese or only had GPS coordinates in China.
From 3.784.309.399 messages, 3.698.798.784 were written in Chinese.
59.378.236 in English and 26.132.379 in another language. 98% of the Chinese messages had a GPS location in China. 68% of the English messages were sent in China. More than 19 million were sent from outside 🇨🇳
59.378.236 in English and 26.132.379 in another language. 98% of the Chinese messages had a GPS location in China. 68% of the English messages were sent in China. More than 19 million were sent from outside 🇨🇳
We were able to detect a patron of a little bit more than 800 Chinese keywords (combinations) which would be the selection criteria for having the entire WeChat dialogue being stored in this database for further "analysis" by most likely a law enforcement.

We could build a "dictionary" of 829 keywords (combinations) based on the intercepted WeChat messages which were written in English. I was a bit surprised to see my full name "Victor Gevers" in this generated English list. 维克多 葛弗斯 was not in the Chinese keyword list.

Using these keywords will not get your account locked. But I you try to send your contact a few messages contains a few hundred of these words then you need to “unblock” your account after a few minutes.

Based on the 3,784,309,399 WeChat messages we tried to build a "keyword trigger list" with NLP tools which possibly triggered the automatic selection criteria for having the entire conversation being stored for review.
Image:
Text: i.imgur.com/PWNQEpe.png
pastebin.com/raw/LCPyenzC
Image:
Text: i.imgur.com/PWNQEpe.png
pastebin.com/raw/LCPyenzC

From 3.784.309.399 intercepted messages. 59.378.236 were in English.
19 million were sent from outside Mainland China: South Korea, Taiwan, US, Australia, Canada, Colombia, Venezuela, Belgium, France, UK, Germany, Netherlands, Turkey, Italy, Switzerland, New Zealand & Ireland.
19 million were sent from outside Mainland China: South Korea, Taiwan, US, Australia, Canada, Colombia, Venezuela, Belgium, France, UK, Germany, Netherlands, Turkey, Italy, Switzerland, New Zealand & Ireland.


I am listening to the @riskybusiness show [], and I hear this at 21:50:
"We've got politicians in Australia who are using WeChat."
Wait!? What? So they can have been one of the 937202 "flagged" conversations recorded in Australia? 🤷♂️
"We've got politicians in Australia who are using WeChat."
Wait!? What? So they can have been one of the 937202 "flagged" conversations recorded in Australia? 🤷♂️
https://twitter.com/riskybusiness/status/1121269841040510976

512.2 million WeChat accounts (unique wxids) sent 3,784,309,399 messages on 18-03-2019. 1 billion captured WeChat conversations contained keywords which marked for "review". 59.378.236 were written in English.
19 million were sent from 🇰🇷🇹🇼🇺🇸🇦🇺🇨🇦🇨🇴🇻🇪🇧🇪🇫🇷🇬🇧🇩🇪🇳🇱🇹🇷🇮🇹🇨🇭🇳🇿🇮🇪
19 million were sent from 🇰🇷🇹🇼🇺🇸🇦🇺🇨🇦🇨🇴🇻🇪🇧🇪🇫🇷🇬🇧🇩🇪🇳🇱🇹🇷🇮🇹🇨🇭🇳🇿🇮🇪

I wonder why the Australia politicians are willing to take a "calculated" risk when they expose the participants (the Mandarin-speaking community and themselves) to Chinese surveillance by using WeChat for "a novel political experiment."
Source: thesaturdaypaper.com.au/news/politics/…
Source: thesaturdaypaper.com.au/news/politics/…

BBC China social media: WeChat and the Surveillance State
bbc.com/news/blogs-chi…
bbc.com/news/blogs-chi…
In the "phrase matching" process the Chinese data scientist student used these Chinese keywords from this wordlist
So we can safely assume that the keyword trigger list is far from complete. So we decided to do this research all over again from scratch... github.com/citizenlab/cha…
So we can safely assume that the keyword trigger list is far from complete. So we decided to do this research all over again from scratch... github.com/citizenlab/cha…

A quick status update. The data scientist who created the current keyword list is still MIA. []. We did not make so much progress. Yet new breadcrumbs are slowing surfacing thanks to termination of third party translation services.
github.com/cookiemonster/…
https://twitter.com/GDI_FDN/status/1130489101273243648
github.com/cookiemonster/…

New sources keep contributing to the research into WeChat and other multi-purpose messaging, social media and mobile payment monitoring. Every day new development systems are randomly popping up in China and are sharing data that is all publicly available (in open databases).


Globally, hundreds of millions are consuming information directly produced by Chinese state media—sometimes without knowing it, says @freedomhouse
’s @Sarah_G_Cook.
Social media and multi-purpose messaging apps are being monitored, and controlled.
’s @Sarah_G_Cook.
Social media and multi-purpose messaging apps are being monitored, and controlled.
https://twitter.com/JanJekielek/status/1223785758177333248?s=20
BREAKING: President @realDonaldTrump orders clampdown on TikTok and WeChat beginning on Sunday, prevents download in the U.S.
https://twitter.com/AP/status/1306931923617542146
After almost a year, @realDonaldTrump signed Executive Order 13943 for addressing the current issues with WeChat. federalregister.gov/documents/2020…
President @realDonaldTrump ordered a ban on eight Chinese apps: Alipay, CamScanner, QQ Wallet, SHAREit, Tencent QQ, VMate, WeChat Pay, and WPS Office.
whitehouse.gov/presidential-a…
whitehouse.gov/presidential-a…
"Tencent Executive Held by China Over Links to Corruption Case."
'Zhang Feng has been investigated for alleged unauthorized sharing of personal data collected by WeChat to an ex-official.'
wsj.com/articles/tence…
'Zhang Feng has been investigated for alleged unauthorized sharing of personal data collected by WeChat to an ex-official.'
wsj.com/articles/tence…
@threadreaderapp unroll
• • •
Missing some Tweet in this thread? You can try to
force a refresh














{kind=link}