
What is a causal model and how is it different from a "common" statistical model?
👇
Thread on a mental picture and intuition how one may think about (a subclass of) causal models and the causal discovery problem.
1/
@bttyeo @eliasbareinboim @KordingLab @EpiEllie @causalinf
👇
Thread on a mental picture and intuition how one may think about (a subclass of) causal models and the causal discovery problem.
1/
@bttyeo @eliasbareinboim @KordingLab @EpiEllie @causalinf
A "common" statistical model models one joint distribution over variables X = {A, B, …}; a causal model models a set of joint distributions over X, one for each intervention.
Here line segments correspond to the modellable distributions for varying model parameters.
2/
Here line segments correspond to the modellable distributions for varying model parameters.
2/
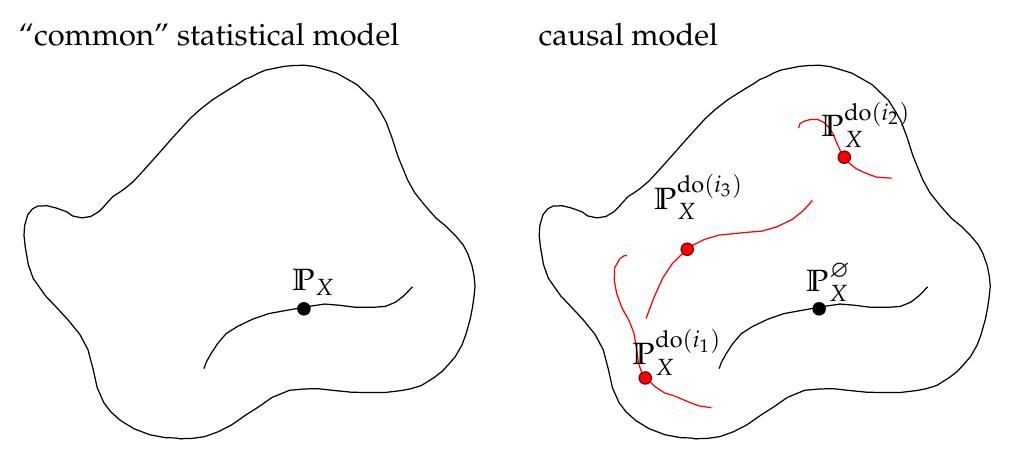
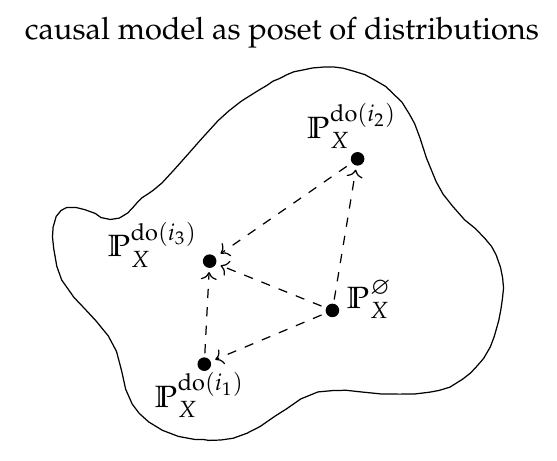
The distributions are indexed by so-called interventions i_k. The intervention set admits a partial ordering reflecting the compositionality of interventions, e.g. do(A=0) ≤ do(A=0, B=0).
↳ A causal model as a poset of joint distributions.
(Ø denotes the null-intervention)
3/
↳ A causal model as a poset of joint distributions.
(Ø denotes the null-intervention)
3/
Structural Equation Models are one convenient way to describe such a structured set of distributions:
A set of equations and noise variables together with instructions on how to manipulate the equations upon intervention is enough to describe the entire poset.
4/
A set of equations and noise variables together with instructions on how to manipulate the equations upon intervention is enough to describe the entire poset.
4/
In causal discovery we aim to infer a (structural) causal model from some observational data that correctly predicts the effects of interventions, while we are only given samples from a subset of the distributions, often only the observational distribution.
5/
5/
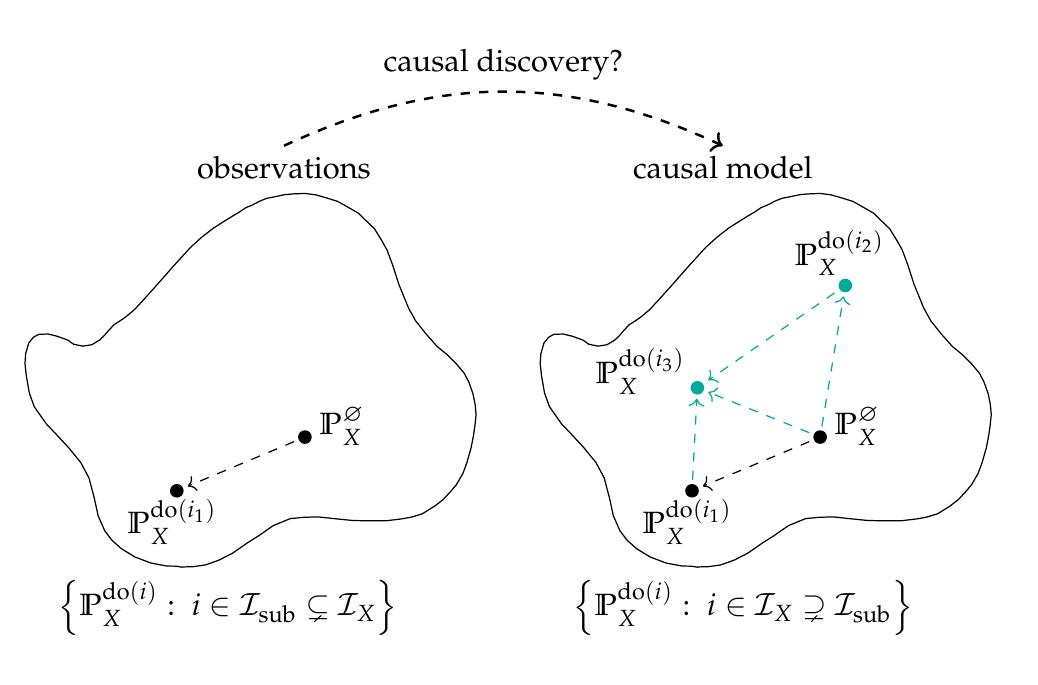
It is notoriously difficult to not only model the distributions of which observations are available (common statistical modelling), but to infer a causal model that enables reasoning beyond the observed distributions on the effects of interventions.
eg.
6/
eg.
https://twitter.com/danilobzdok/status/1128963095731363840
6/
The statistical treatment of causal discovery lays out different approaches that clarify under which additional assumptions causal structure can indeed be identified.
7/
https://twitter.com/sweichwald/status/1129277974799376384
7/
Closing remarks:
This describes a subclass of causal models, those that model the effects of interventions;
but
Also see this
8/
This describes a subclass of causal models, those that model the effects of interventions;
but
https://twitter.com/yudapearl/status/1126962287858733056and no counterfactuals considered.
Also see this
https://twitter.com/yudapearl/status/1064882222673457152for a more general definition of a causal model by @yudapearl
8/
Finally, due credit and thanks to my colleague @PaulKRubenstein for the TikZ template premiered at UAI 2017
Paper: arxiv.org/abs/1707.00819
Slides: paulrubenstein.co.uk/wp-content/upl…
Poster: paulrubenstein.co.uk/wp-content/upl…
//
Paper: arxiv.org/abs/1707.00819
Slides: paulrubenstein.co.uk/wp-content/upl…
Poster: paulrubenstein.co.uk/wp-content/upl…
//
@bttyeo @eliasbareinboim @KordingLab @EpiEllie @causalinf Why is fitting the observational distribution and selecting a model based on model fit/complexity insufficient for causal modelling?
See a follow-up thread here illustrating some intricacies in causal discovery:
See a follow-up thread here illustrating some intricacies in causal discovery:
https://twitter.com/sweichwald/status/1131580961320255488
• • •
Missing some Tweet in this thread? You can try to
force a refresh





