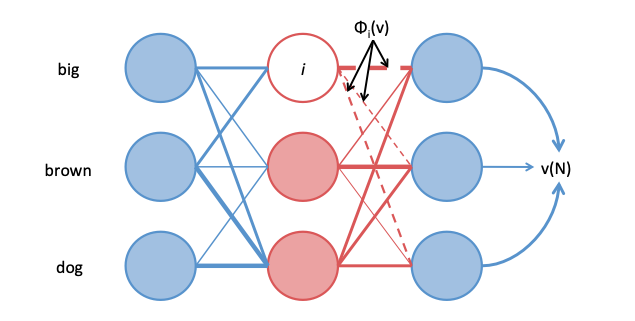
When and why does king - man + woman = queen? In my #ACL2019 paper with @DavidDuvenaud and Graeme Hirst, we explain what conditions need to be satisfied by a training corpus for word analogies to hold in a GloVe or skipgram embedding space. 1/4
blog: bit.ly/2X18QEd
blog: bit.ly/2X18QEd

paper: arxiv.org/abs/1810.04882
In turn, our theory provides
1. An information theoretic interpretation of Euclidean distance in skipgram and GloVe embedding spaces.
2. Novel justification for the surprising effectiveness of using addition to compose word vectors. 2/4
In turn, our theory provides
1. An information theoretic interpretation of Euclidean distance in skipgram and GloVe embedding spaces.
2. Novel justification for the surprising effectiveness of using addition to compose word vectors. 2/4
3. A formal proof of the intuitive explanation of word analogies, as proposed by Pennington, @RichardSocher, and @chrmanning in the GloVe paper.
Most importantly, we provide empirical evidence in support of our theory, making it much more tenable than past explanations. 3/4
Most importantly, we provide empirical evidence in support of our theory, making it much more tenable than past explanations. 3/4
Special thanks to @omerlevy_ and @yoavgo for their helpful comments on an early draft of this paper, as well @chloepouprom, KP, and @Allen_A_N for their comments on the blog post! 4/4
• • •
Missing some Tweet in this thread? You can try to
force a refresh