
Assistant Professor of Applied AI @ChicagoBooth @UChicago working on behavioral machine learning.
PhD @StanfordAILab @stanfordnlp.
 For a long time, our models of language were very structured. You would create trees of sentences based on their grammatical structure (e.g., dependency parsing), catalog all the different senses of words (e.g,. WordNet), etc. We did this for three reasons:
For a long time, our models of language were very structured. You would create trees of sentences based on their grammatical structure (e.g., dependency parsing), catalog all the different senses of words (e.g,. WordNet), etc. We did this for three reasons: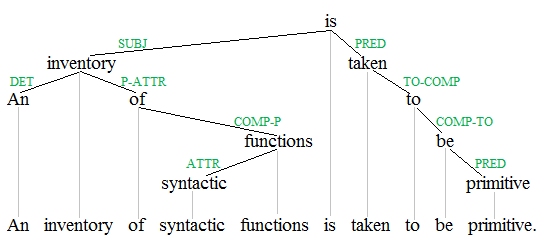
 But first, what makes alignment work? Among methods that directly optimize preferences, the majority of gains <30B come from SFT.
But first, what makes alignment work? Among methods that directly optimize preferences, the majority of gains <30B come from SFT. 

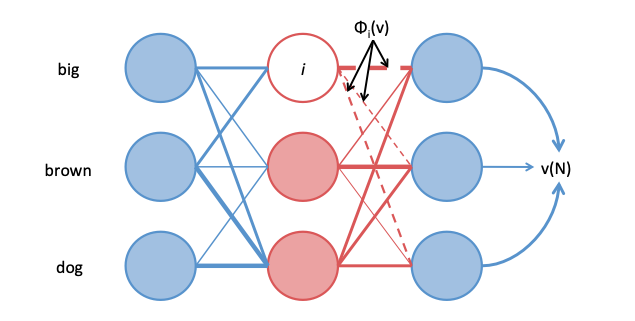 Shapley Values are a solution to the credit assignment problem in cooperative games -- if 10 people work together to win some reward, how can it be equitably distributed?
Shapley Values are a solution to the credit assignment problem in cooperative games -- if 10 people work together to win some reward, how can it be equitably distributed?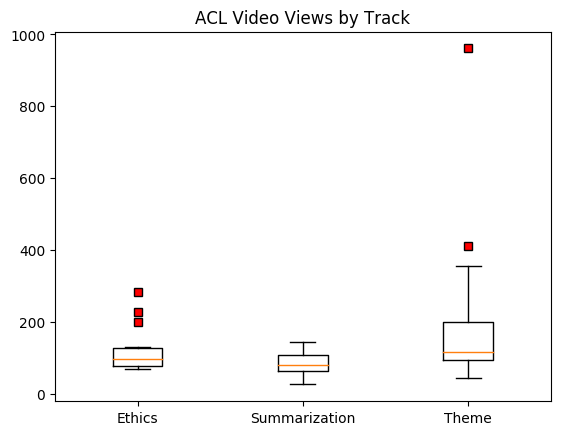 1. Climbing towards NLU: On Meaning, Form, and Understanding in the Age of Data by @emilymbender and @alkoller (961 views)
1. Climbing towards NLU: On Meaning, Form, and Understanding in the Age of Data by @emilymbender and @alkoller (961 views) Key findings:
Key findings: Key Takeaways:
Key Takeaways: paper: arxiv.org/abs/1810.04882
paper: arxiv.org/abs/1810.04882