
Making distribute tracing easier with more sophisticated visualizations - @YuriShkuro
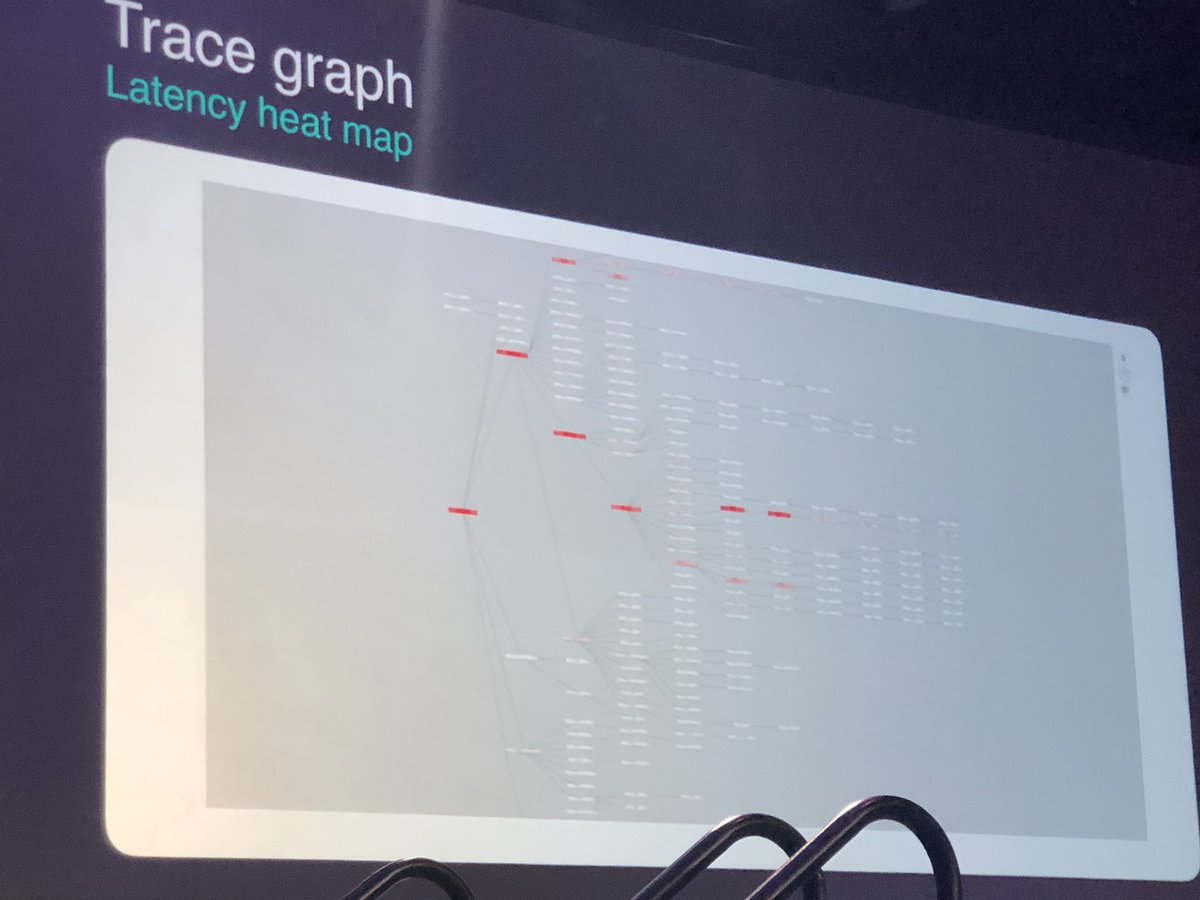
The first is color coded by service graph. The second is a heat map #QConNYC
The first is color coded by service graph. The second is a heat map #QConNYC

Now @YuriShkuro is talking about a tool that compares traces.
[ ed- omg this: just yesterday I was talking to a vendor at QCon and was wondering if it’d be possible to compare traces. They said their product didn’t offer this. IMo this is the most important aspect of tracing]
[ ed- omg this: just yesterday I was talking to a vendor at QCon and was wondering if it’d be possible to compare traces. They said their product didn’t offer this. IMo this is the most important aspect of tracing]


And the diff tool deals with aggregate traces. You can then drill down into an individual trace. @YuriShkuro at #QConNYC
[ed - this. This so freaking much. Starting with a trace is like being in a hiding to nowhere. Need to begin with an aggregate view.]
[ed - this. This so freaking much. Starting with a trace is like being in a hiding to nowhere. Need to begin with an aggregate view.]
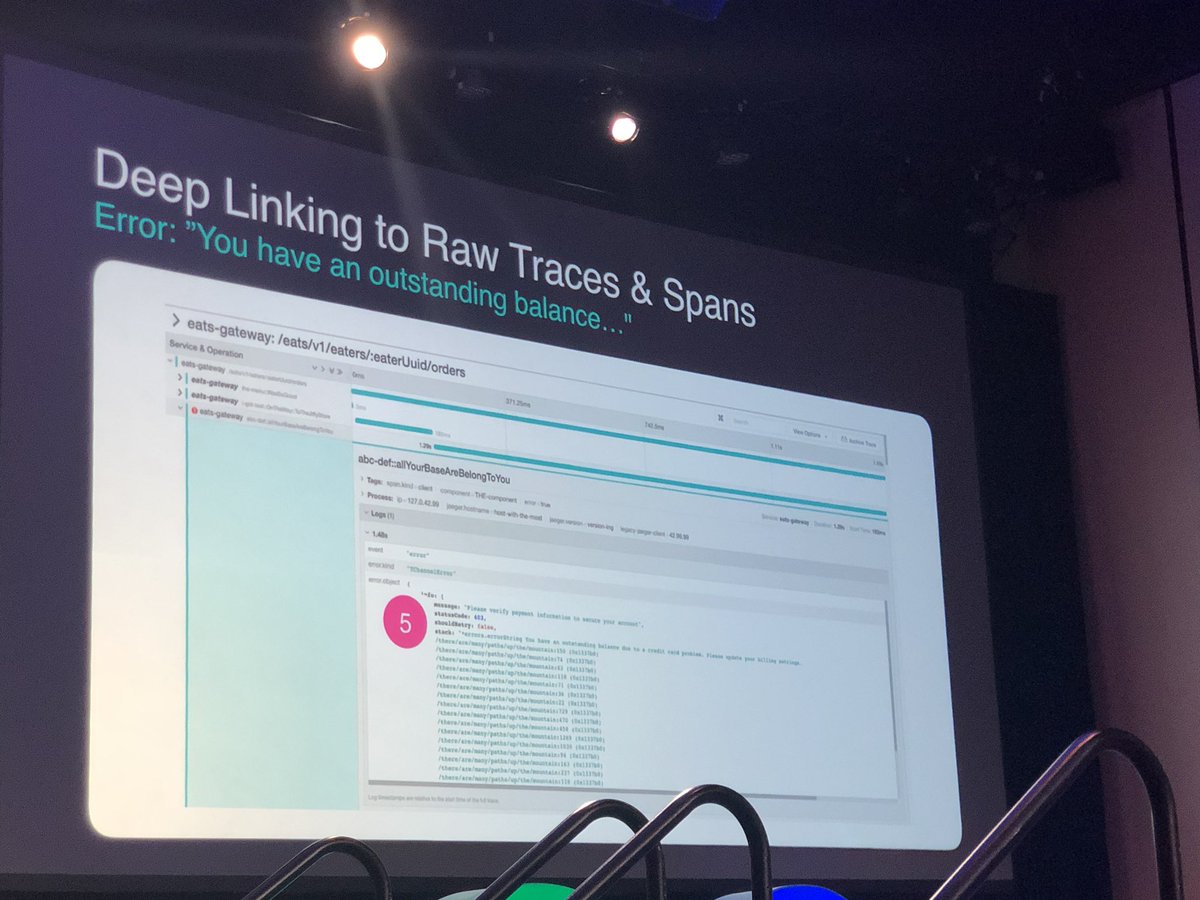
I missed the first part of this talk, but everything I saw was 💯.
Tracing only becomes useful when you can surface the relevant information from a trace. That requires aggregate analysis.
But this isn’t without its flaws. Finding the right baseline might be hard.
Tracing only becomes useful when you can surface the relevant information from a trace. That requires aggregate analysis.
But this isn’t without its flaws. Finding the right baseline might be hard.


Here’s a tool that’s internal to Uber that helps with “root cause” (sic) analysis to drill down from business metrics to app level telemetry. @YuriShkuro at #QConNYC



One of the challenges of taming microservices complexity is dealing with data.
Tracing can help here by enabling building lineage graphs h/t @palvaro
Tracing can help here by enabling building lineage graphs h/t @palvaro



The hardest part of doing all this analysis is application instrumentation.
Doing the analysis is easy for us (Uber) - getting almighty fidelity data is the challenge. - @YuriShkuro at #QConNYC
Doing the analysis is easy for us (Uber) - getting almighty fidelity data is the challenge. - @YuriShkuro at #QConNYC


In summary:
- tracing really becomes usable when you have creative visualizations
- engineers don’t really know how their services work. Tracing helps unlock unparalleled insights.
@YuriShkuro at #QConNYC
- tracing really becomes usable when you have creative visualizations
- engineers don’t really know how their services work. Tracing helps unlock unparalleled insights.
@YuriShkuro at #QConNYC


Uber doesn’t use tracing for latency analysis. We use it for root cause analysis. - @YuriShkuro at #QConNYC
• • •
Missing some Tweet in this thread? You can try to
force a refresh

















