


 "Socket Takeover" should be familiar to traffic nerds. Transferring the listening socket over a Unix Domain Socket with ancillary message (CMSG) + SCM_RIGHTS is *precisely* how HAProxy does seamless reloads.
"Socket Takeover" should be familiar to traffic nerds. Transferring the listening socket over a Unix Domain Socket with ancillary message (CMSG) + SCM_RIGHTS is *precisely* how HAProxy does seamless reloads.






 CockroachDB is a distributed replicated transactional database.
CockroachDB is a distributed replicated transactional database. 



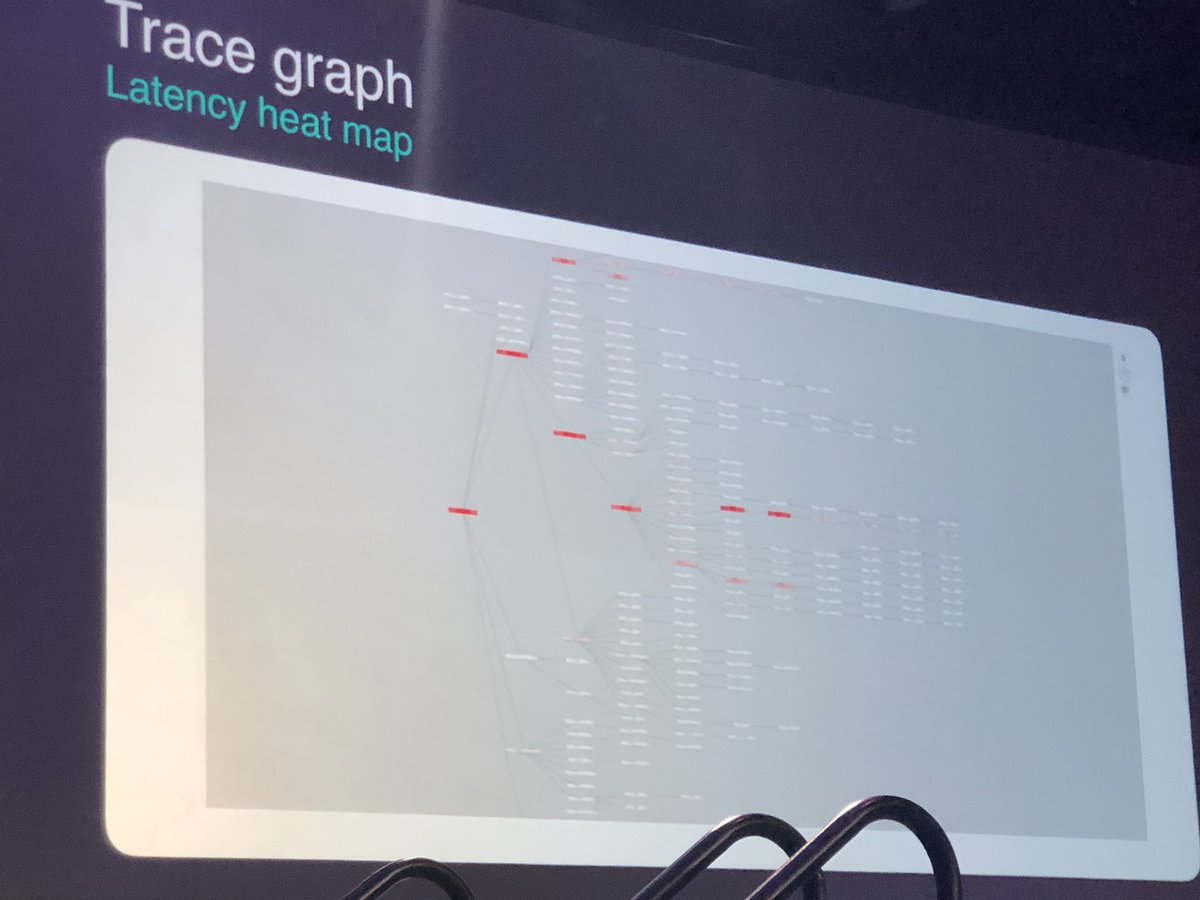 Now @YuriShkuro is talking about a tool that compares traces.
Now @YuriShkuro is talking about a tool that compares traces. 




 Haha @colmmacc put my DM to him the slides - as an example of observations and feedback in practice! 😁 #QConNYC
Haha @colmmacc put my DM to him the slides - as an example of observations and feedback in practice! 😁 #QConNYC 



 The compiler and processor reorder instructions. It helps to know the rules. @kavya719 at @qconnewyork
The compiler and processor reorder instructions. It helps to know the rules. @kavya719 at @qconnewyork 

 EC2 startup times alone isn’t very convincing to justify a 2 year effort to make this move.
EC2 startup times alone isn’t very convincing to justify a 2 year effort to make this move. 

