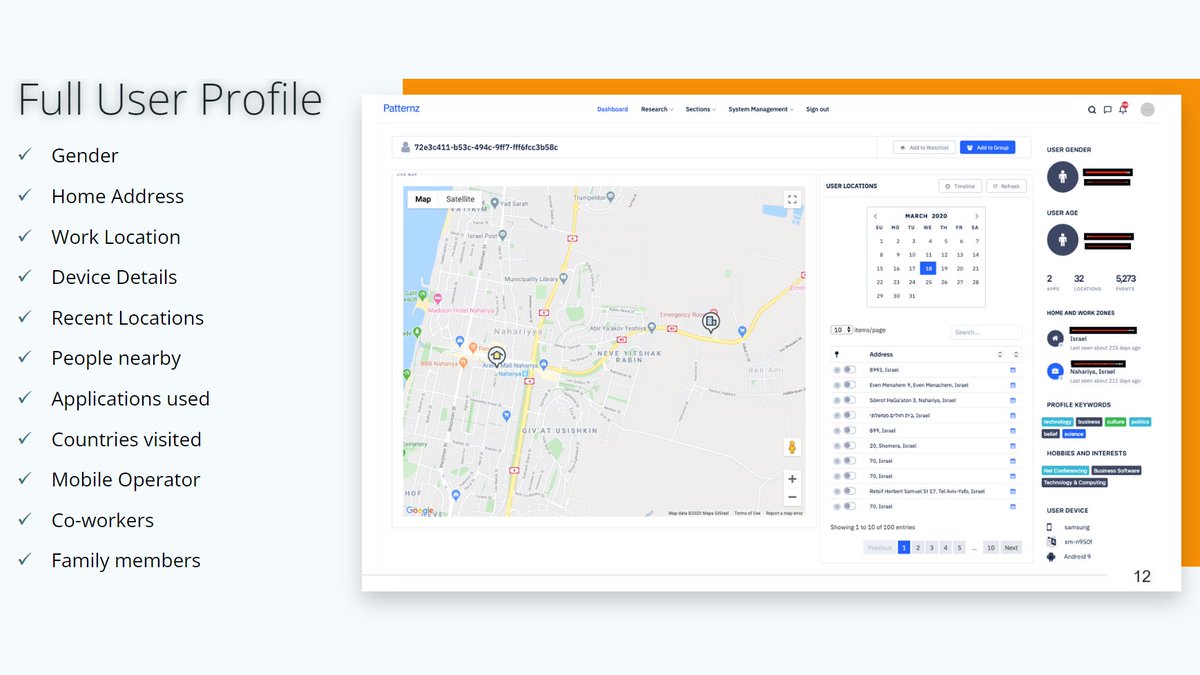
Die Studie zeigt einmal mehr, was wir lange wissen. Solange Daten über Einzelpersonen nicht sehr grob zusammengefasst/aggregiert werden, kann wohl keine Anonymisierung der Welt mit 100% Sicherheit verhindern, dass Personen reidentifiziert werden können.
Ein paar Gedanken dazu.
Ein paar Gedanken dazu.
https://twitter.com/cynddl/status/1153711987878223873
Was gute Anonymisierung kann, ist zB den für eine Reidentifzierung notwendigen Aufwand stark erhöhen, die Wahrscheinlichkeit dafür senken oder deren Zuverlässigkeit unterminieren.
Aber Frage, über welche praktischen Szenarien ungewollter Reidentifizierung sprechen wir überhaupt?
Aber Frage, über welche praktischen Szenarien ungewollter Reidentifizierung sprechen wir überhaupt?
Wenn ich zu 100% verhindern möchte, dass mich jemand unter Einsatz aller verfügbaren Daten und technischen Mittel als Einzelperson reidentifizieren kann, wirds schwierig.
Individualisierte "digitale Selbstverteidigung" oder rein technischer Datenschutz helfen nur sehr begrenzt.
Individualisierte "digitale Selbstverteidigung" oder rein technischer Datenschutz helfen nur sehr begrenzt.
Wenn es allerdings zB um die systematische Massen-Reidentifikation für kommerzielle Zwecke geht, sehe ich schon Ansatzpunkte.
Die DSGVO ist keine schlechte Ausgangsbasis dafür, unsere Rechte und Freiheiten *auch dann* zu schützen, wenn bereits Daten über uns verarbeitet werden.
Die DSGVO ist keine schlechte Ausgangsbasis dafür, unsere Rechte und Freiheiten *auch dann* zu schützen, wenn bereits Daten über uns verarbeitet werden.
Aber die DSGVO gilt doch nur für personenbezogene Daten und nicht für "anonymisierte" Daten?
Und was heisst das alles mittelfristig für die Zukunft von Datenschutzgesetzgebung und Anonymisierung?
Und was heisst das alles mittelfristig für die Zukunft von Datenschutzgesetzgebung und Anonymisierung?
(1) Es läuft wohl darauf hinaus, in Hinkunft den Blick noch mehr auf den Zeitpunkt zu richten, zu dem vermeintlich anonymisierte Daten wieder klar auf Personen angewandt werden - etwa um ihnen Eigenschaften zuzuschreiben, sie auszusondern oder Entscheidungen über sie zu treffen.
(2) Dazu muss aber die Unterscheidung zwischen personenbezogenen und nicht-personenbezogenen Daten aufrecht erhalten werden, denn diese Unterscheidung ist die Basis für die DSGVO und für jegliche Datenschutzgesetzgebung europäischer Prägung.
Diese Unterscheidung wird durch den Zugriff auf umfassende Datenbestände sowie durch die Verknüpfung unterschiedlicher Datenquellen - in Kombination mit fortgeschrittenen Analysemethoden - unterminiert. Siehe zB nissenbaum.tech.cornell.edu/papers/BigData…
Ich bin aber stark dafür, diese Unterscheidung zu "retten".
Mittelfristig müssen wir wohl noch mehr darüber diskutieren, wo wir diese Trennlinie zwischen der Verarbeitung a) personenbezogener und b) bestmöglich anonymisierter Daten ziehen, je nach Anwendung+Kontext.
Mittelfristig müssen wir wohl noch mehr darüber diskutieren, wo wir diese Trennlinie zwischen der Verarbeitung a) personenbezogener und b) bestmöglich anonymisierter Daten ziehen, je nach Anwendung+Kontext.
(3) Dazu brauchen wir aber ergänzende Regeln für bestimmte Arten datenbasierter Anwendungen, die über Datenschutzrecht hinausgehen.
(4) Viertens könnten wir über ein expliziteres Reidentifizierungsverbot nachdenken (auch wenn sich dabei viele heikle Fragen stellen).
(4) Viertens könnten wir über ein expliziteres Reidentifizierungsverbot nachdenken (auch wenn sich dabei viele heikle Fragen stellen).
Wo sich die Problematik der systematischen Massen-Reidentifizierung natürlich ganz besonders stellt, sind die großen Datenfarmen wie FB und Google, mit ihren extrem umfassenden Datenbeständen.
Aber deren Dominanz und Datenmacht müssen wir sowieso angehen, auch unabhängig davon.
Aber deren Dominanz und Datenmacht müssen wir sowieso angehen, auch unabhängig davon.
Kurzfristig sind aus meiner Sicht allerdings ganz andere Probleme *prioritär*:
Im Rahmen des kommerziellen Massen-Datenmissbrauchs werden in vielen Bereichen ganz klar personenbezogene Daten verarbeitet, abgeglichen, ausgetauscht und verkauft.
Im Rahmen des kommerziellen Massen-Datenmissbrauchs werden in vielen Bereichen ganz klar personenbezogene Daten verarbeitet, abgeglichen, ausgetauscht und verkauft.
Unternehmen sprechen etwa oft komplett irreführend von "anonymisierten" Daten, wo in Wirklichkeit pseudonymisierte - und damit eindeutig personenbezogene - Daten verarbeitet werden.
Hier muss die DSGVO einfach nur endlich durchgesetzt werden.
Hier muss die DSGVO einfach nur endlich durchgesetzt werden.
• • •
Missing some Tweet in this thread? You can try to
force a refresh