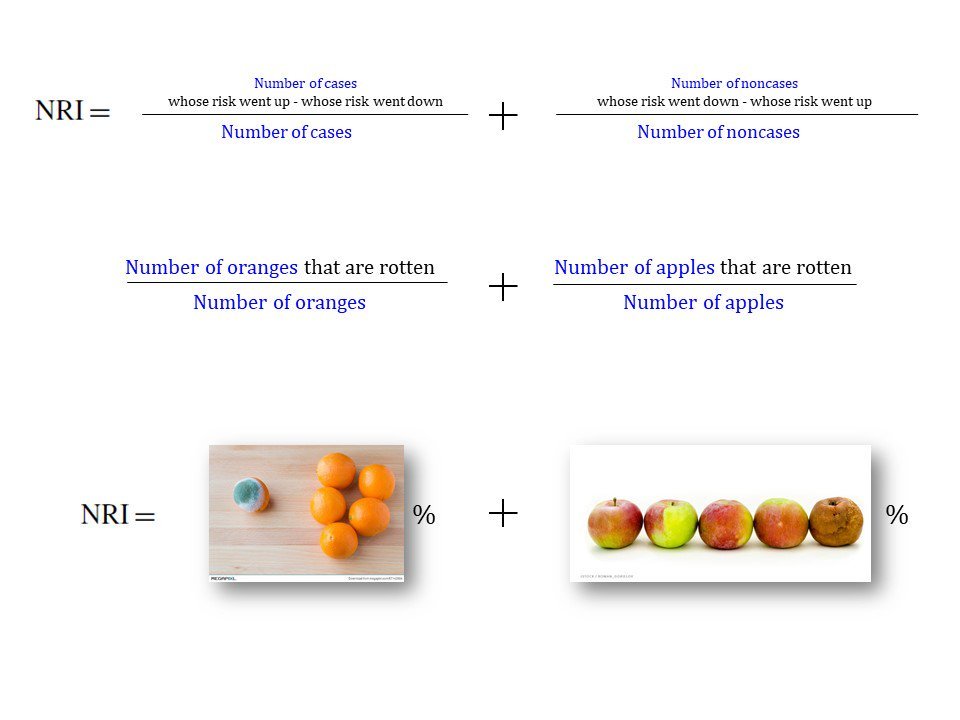
This commentary shows that highest AUC does not indicate highest utility ... but how realistic is the hypothetical scenario? When does this occur?
(short thread)
jamanetwork.com/journals/jama/…
(short thread)
jamanetwork.com/journals/jama/…

From the curves, we can see that the ROC 0.74 algorithm includes a risk factor (RF) that is highly sensitive in identifying cases. The RF identifies 30% of the cases and is not found in 'controls'. Why was this RF not considered in the other algorithm?

This is the projected ROC curve when the RF would have been used in the other algorithm. When *nested* algorithms are compared in large enough sample sizes, the extended model generally has the same or larger AUC. I love to see exceptions on this rule of thumb.

• • •
Missing some Tweet in this thread? You can try to
force a refresh