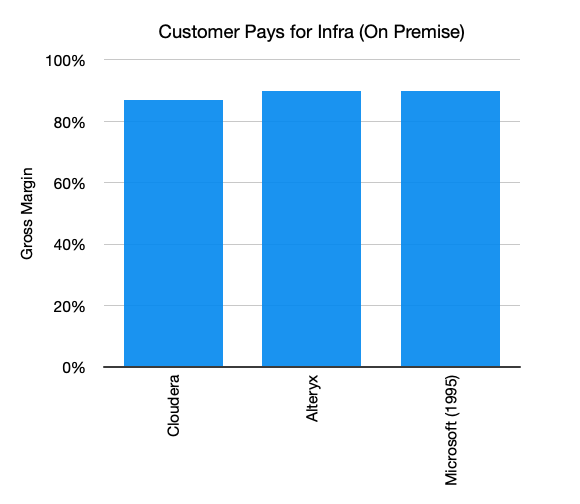
1/ Cerebras just built a chip with 50x the transistor count, 1,000x the memory and 10,000x the bandwidth of Nvidia’s flagship GPU. One such 'chip' could replace an entire rack of Nvidia GPUs.
What the heck is going on?
What the heck is going on?
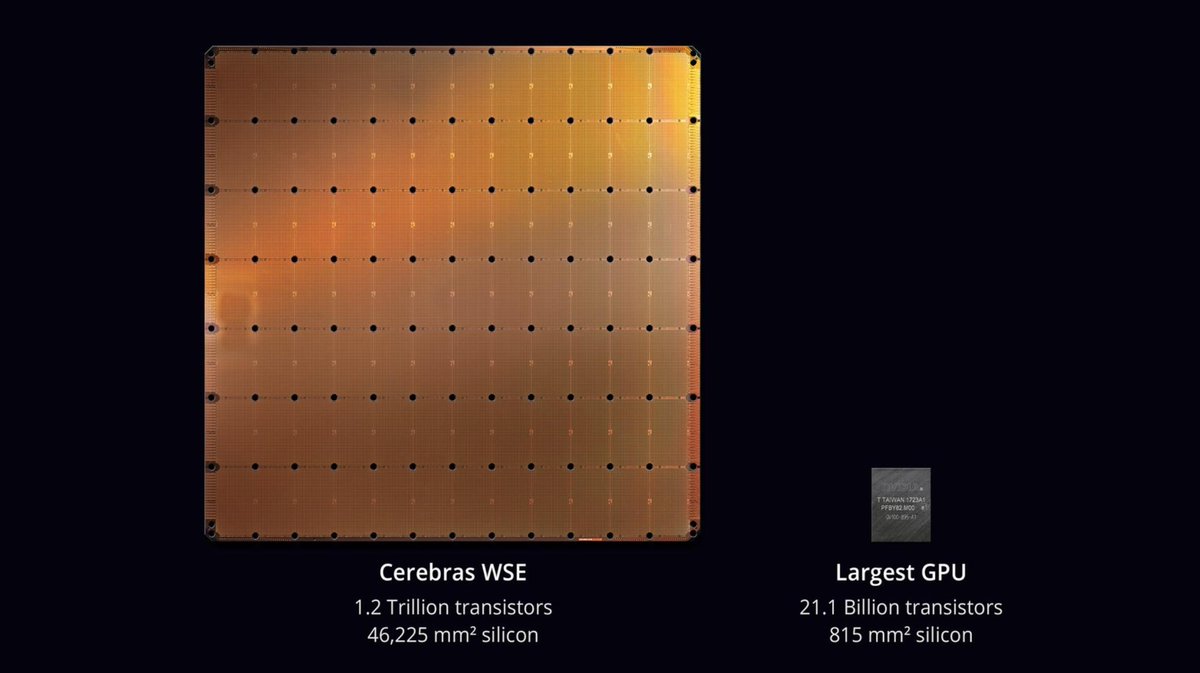
2/ It’s no coincidence that the fastest AI chip today—Nvidia’s V100—is also the largest @ 815mm^2. More area = more cores and memory.
But why not make the chip even bigger? Two reasons..
But why not make the chip even bigger? Two reasons..
3/ First, the ASML lithography machines have a reticle size of 858mm^2. V100 is basically at the limit of what today's manufacturing allows.

4/ Second, defect rate. The larger the chip, the greater the chance for chip defects. As chip size grows, the defect rate -> 100%, yield -> 0%. It’s very hard to make large chips and still have enough working ones to sell.

5/ So what did Cerebras do? They made the largest chip ever—a chip the size of an entire wafer.
If this were pizza, Nvidia/Intel/AMD make 30cm pies and then cut them up and sell tiny 2cm^2 slices. Cerebras sells a giant uncut 21cm^2 slab.
If this were pizza, Nvidia/Intel/AMD make 30cm pies and then cut them up and sell tiny 2cm^2 slices. Cerebras sells a giant uncut 21cm^2 slab.

6/ How did Cerebras get around the reticle limit and defect rate?
Their chips still use a conventional photomask and expose the wafer sections at a time. But they worked with TSMC to lay additional wires to wire all the chips together so they can work as a whole.
Their chips still use a conventional photomask and expose the wafer sections at a time. But they worked with TSMC to lay additional wires to wire all the chips together so they can work as a whole.

7/ Cerebras deals with defects through build-in redundancy. The chip has extra cores and I/O lanes built-in. If one core is a dud, data moves around it just as traffic is re-routed around a closed city block. According to Cerebras, only 1.5% of the hw is for redundancy.

8/ Why is one giant chip better than a bunch of tiny ones?
Because you can fit the whole neural network on one chip rather than dice it up and spread it across dozens of GPUs. It is easier to program, way faster, and far more power efficient.
Because you can fit the whole neural network on one chip rather than dice it up and spread it across dozens of GPUs. It is easier to program, way faster, and far more power efficient.

• • •
Missing some Tweet in this thread? You can try to
force a refresh