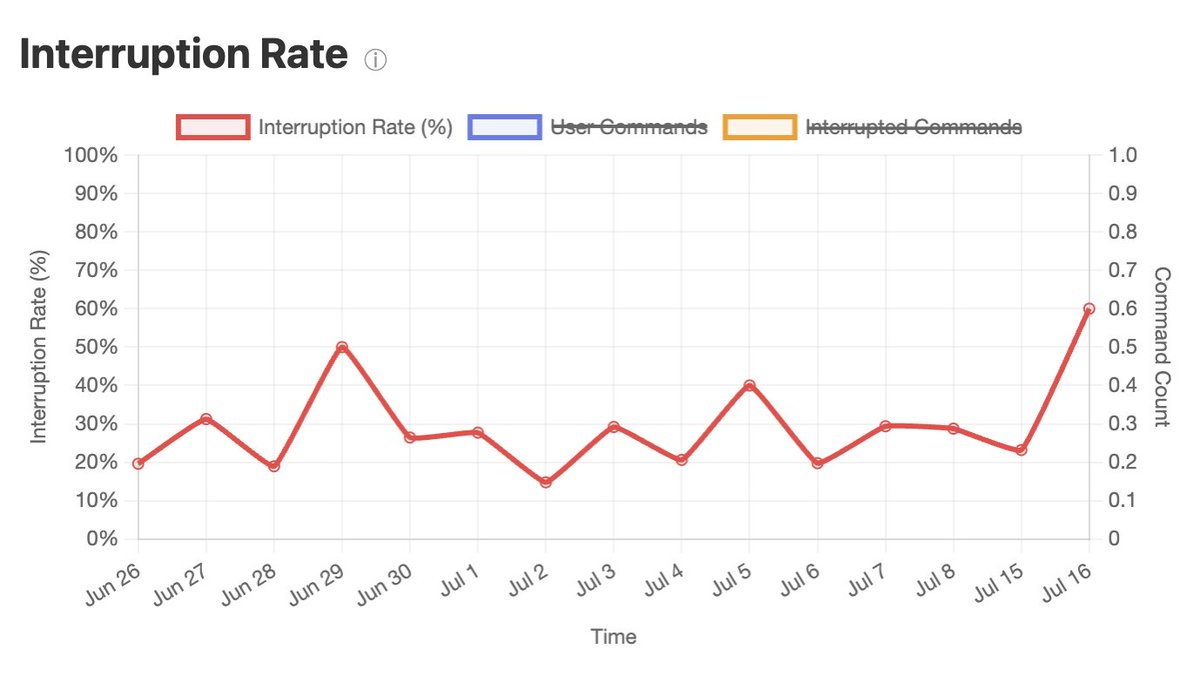
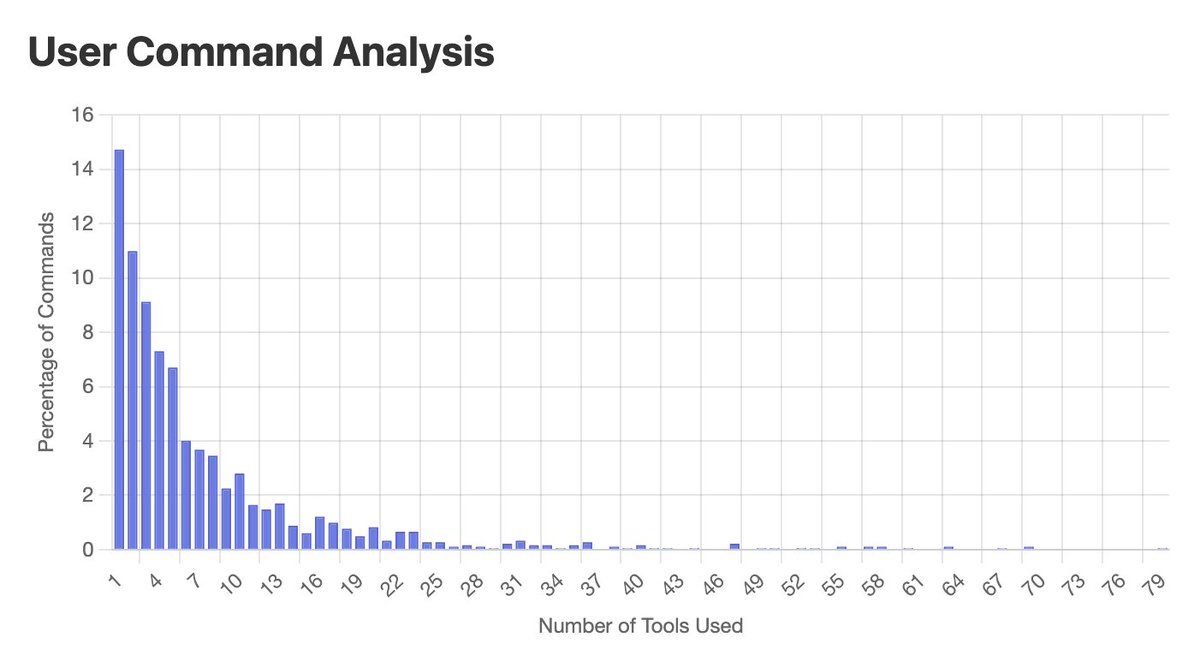
To better understand the technical hiring pipelines, I analyzed 15,897 interview reviews for 27 major tech companies on Glassdoor. I focused on interviews for software engineering related roles, both junior and senior levels. These are some of the main findings. (1/n)
Each review consists of:
- result (no offer/accept offer/decline offer)
- difficulty (easy/medium/hard)
- experience (positive/neutral/negative)
- review (application/process/questions)
The largest SWE employers are Google, Amazon, Facebook, and Microsoft.
- result (no offer/accept offer/decline offer)
- difficulty (easy/medium/hard)
- experience (positive/neutral/negative)
- review (application/process/questions)
The largest SWE employers are Google, Amazon, Facebook, and Microsoft.

Strong correlation bw onsite-to-offer rate and offer yield rate (% of candidates who accept their offers). The more selective the company is, the less likely a candidate is to accept their offer. Candidates that pass interviews at FAANG are likely to have other attractive offers.

To read the graph^: 18.83% of onsite candidates at Google get offers, and out of all those with offers, 70% accept. Due to the biases of online reviews, the actual numbers are much lower. The most selective companies are Yelp, Google, Snap, and Airbnb.
Referrals matter, a lot. For junior roles, about 10 - 20% of candidates that get to onsites are referred, with Uber leading the chart with almost 30%. For senior roles, that numbers are higher. Salesforce, Uber, and Cisco all have ~30% of their senior onsite candidates referred.

For junior roles, the biggest source for onsite candidates is campus recruiting. Microsoft & Oracle have >50% of their interviewees recruited through campus events. Google, Facebook, and Airbnb rely less on campus recruiting, but it still accounts ~20- 30% of their onsites.
This means big tech companies concentrate their recruiting effort to a handful of popular engineering schools. Students recruited from those schools then refer their classmates, who in turn refer even more classmates, turning those major tech cos into a Tech Ivy alumni mixer.
Everyone complains that the interview process is broken. It’s not entirely true, at least from the perspective of the candidates who get interviews. 60% of candidates report a positive interview experience.

Candidates with offers are more likely to have a positive experience (correlation 0.75). Companies that give the best candidate experiences are Salesforce, Intel, and Adobe.

The more negative experience a candidate has, the less likely they are to accept the offer. If a candidate who receives an offer has a positive experience, they accept the offer with probability 87%. If that candidate has a negative interview experience, the yield rate is 1/3.

Senior candidates are harder to please than junior candidates. This might explain the abysmal Netflix interview experience. While all other companies keep their shares of senior interviews to under one third, Netflix exclusively hire senior positions.

Companies with the hardest interviews (as perceived by candidates) are Google, Airbnb, and Amazon.

The full write-up with details on data, more results, and biases can be found here: huyenchip.com/2019/08/21/gla…
• • •
Missing some Tweet in this thread? You can try to
force a refresh