@aisysbooks @goodailist
AI Engineering: https://t.co/94dv4uTU1H
Designing MLSys: https://t.co/G81hL2dWmr
Reading @chipslib
Jul 16, 2025 • 4 tweets • 2 min read
I open sourced Sniffly, a tool that analyzes Claude Code logs to help me understand my usage patterns and errors.
Key learnings.
1. The biggest type of errors Claude Code made is Content Not Found (20 - 30%). It tries to find files or functions that don't exist.
So I restructured my code base for discoverability, and the average number of steps Claude Code needs for each instruction went from 8 to 7 steps.
2. Traditional metrics of engineering hours/days don’t work for AI. Two metrics I use to evaluate the complexity of a project:
- how many instructions I need to give AI until it completes a project
- how often I have to interrupt it because it goes into the wrong direction
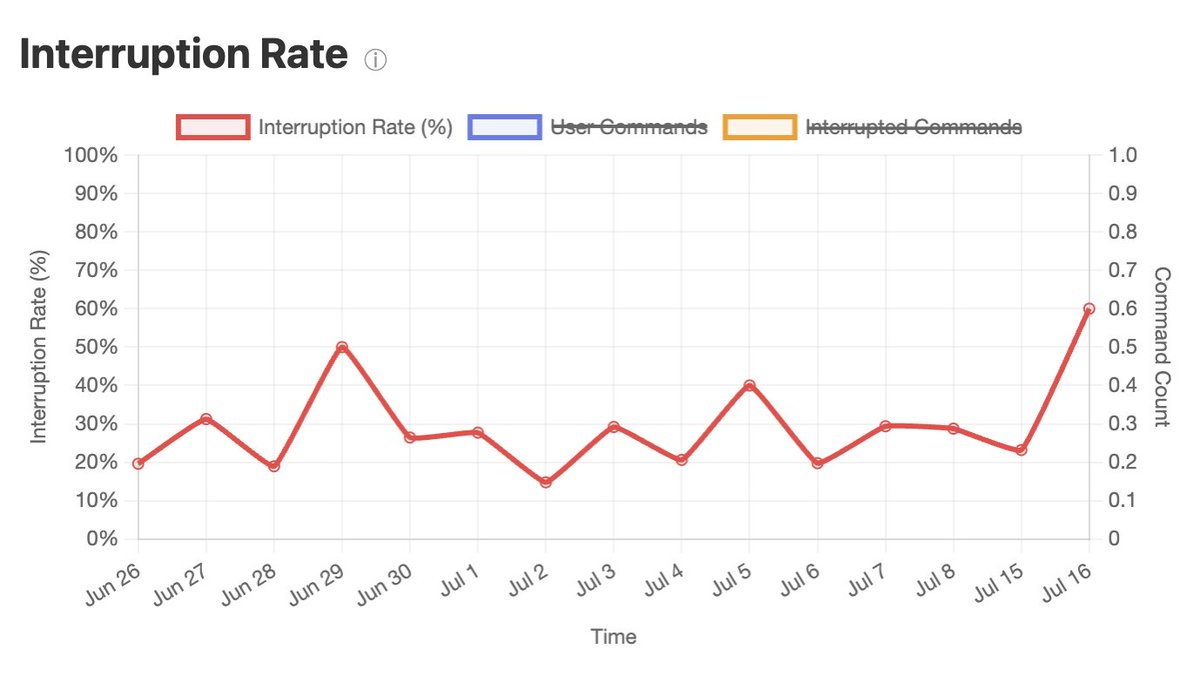
Across my projects, the interruption rate is about 1 in 4 instructions. This means I still need to actively monitor the agent, rather than letting it operate autonomously.
May 6, 2024 • 5 tweets • 2 min read
Really enjoyed LinkedIn's report on what worked and what didn't when deploying LLM applications. 4 takeaways.
1. Structured outputs
They chose YAML over JSON as the output format because YAML uses less tokens. Initially, only 90% of the outputs are correctly formatted YAML. They used re-prompting (asking the model to fix its YAML responses), which increased the number of API calls significantly.
They then analyzed the common formatting errors, added those hints to the original prompt, and wrote an error fixing script. This reduced their errors to 0.01%.2. Sacrificing throughput for latency
Originally, they focused on TTFT (Time To First Token), but realized that TBT (Time Between Token) hurt them more, especially with Chain-of-Thought queries where users don’t see the intermediate outputs.
They found that TTFT and TBT inversely correlate with TPS (Tokens per Second). To achieve good TTFT and TBT, they had to sacrifice TPS.
Oct 7, 2020 • 5 tweets • 1 min read
Some asked me about concept drift so here you go.
A predictive ML model learns theta to output P(Y|X; theta).
Data drift is when P(X) changes: different data distributions, different feature space.
Ex: service launched in a new country, expected features becoming NaNs.
1/5
Label schema change is when Y changes: new classes, outdated classes, finer-grained classes. Especially common with high-cardinality tasks.
Ex: there’s a new disease to categorize.
2/5
Sep 29, 2020 • 6 tweets • 1 min read
When talking to people who haven’t deployed ML models, I keep hearing a lot of misperceptions about ML models in production. Here are a few of them.
(1/6)
1. Deploying ML models is hard
Deploying a model for friends to play with is easy. Export trained model, create an endpoint, build a simple app. 30 mins.
Deploying it reliably is hard. Serving 1000s of requests with ms latency is hard. Keeping it up all the time is hard.
(2/6)
Mar 7, 2020 • 5 tweets • 1 min read
I've been talking to a lot of people looking to join/having joined startups and I'm flabbergasted by how often people think joining startups is a get rich quick scheme. Here's the math why it doesn't work and what to look for when joining startups. (1/n)
Equity: anywhere 0.001% - 10%. A friend recently joined a 15-pax seed startup that offered 4%/4 years + lot of $. He'd be the ML engineer. They need him to raise A. It looks good on paper but do you want a company where you're clearly the best at what you want to learn? (2/n)
Oct 28, 2019 • 7 tweets • 2 min read
To learn how to design machine learning systems, I find it really helpful to read case studies to see how great teams deal with different deployment requirements and constraints. Here are some of my favorite case studies.
Topics covered: lifetime value, ML project workflow, feature engineering, model selection, prototyping, moving prototypes to production. It's completed with lessons learned and looking ahead!
To better understand the technical hiring pipelines, I analyzed 15,897 interview reviews for 27 major tech companies on Glassdoor. I focused on interviews for software engineering related roles, both junior and senior levels. These are some of the main findings. (1/n)
Each review consists of:
- result (no offer/accept offer/decline offer)
- difficulty (easy/medium/hard)
- experience (positive/neutral/negative)
- review (application/process/questions)
The largest SWE employers are Google, Amazon, Facebook, and Microsoft.
Aug 3, 2019 • 11 tweets • 10 min read
This thread is a combination of 10 free online courses on machine learning that I find the most helpful. They should be taken in order.
1. Probability and Statistics by Stanford Online
This self-paced course covers basic concepts in probability and statistics spanning over four fundamental aspects of machine learning: exploratory data analysis, producing data, probability, and inference. online.stanford.edu/courses/gse-yp…
Jul 19, 2019 • 18 tweets • 3 min read
I'm working on a book on machine learning interviews so I've been spending the last few months talking to companies about their hiring process for ML roles. This thread is a summary of what I've learned. It will be updated as the book progresses. (1/n)
The average interviewer gets very little training. You start your full-time job. You shadow a few interviews. Then you're on your own. As a result, interviews are wildly different even within the same company.