
Про парсинг неструктурированных данных я бы рассказал даже. Тема перекликается с разработкой, когда невозможно определить сразу структуры данных. Один лайк - один факт о парсинге неструктурированных данных и задачах с нечётким определением предметной области на #Haskell
Основным инструментом для подобных задач является пакет uniplate, особенно функции universeBi и transformBi. С ними вы можете обходить и переписывать структуры данных разных типов, не заботясь о том, что конкретно они из себя представляют
Есть аналоги на Foldable/Traversable, но они гораздо сложнее и менее зрелые. uniplate существует... ну для меня столько же, сколько сам #Haskell. Простой, тупой и надёжный как топор. Ничего лучше не нашёл, и искать не хочется
Если вы собираетесь в программе пользоваться uniplate для анализа и переписывания значений, то рекордами пользоваться неудобно. Вместо них удобнее использовать структуры такого вида: 

То есть - каждое значение, с которым вы собираетесь работать лучше представить как отдельный тип с тегом, т.е. с отдельным конструктором. По этому конструктору будет удобно это поле находить и переписывать при помощи функций uniplate
Что такое вообще переписывание. Допустим, вы как-то (об этом потом) распарсили массив мусорных данных, и там есть значения типа деньги - (валюта, значение). Валюты могут быть разные, но для генерации отчёта вам бы удобнее видеть всё в одной валюте. Структура данных у вас ...
... неопределенная - по сути это список или список списков или список списков списков вложенных структур, где-то там разбросаны значения "деньги". Как вам пересчитать курсы, что бы получить сравнимые величины?
Примерно вот так. Какой тип данных тут обрабатывается? Да всё равно, transformBi удовлетворяет всё, что Data a

Вот мы переписали всю структуру так, что все денежные значения привелись к одной валюте с примерным пересчётом курса. Не заботясь о том, какая именно это структура. Мы не хотим её определять - ведь мы не знаем, с чем мы имеем дело, да нам и всё равно.
У uniplate есть и минус: GenericDeriving и вообще дерайвинг не будет работать, как только появляются экзистенциальные типы, т.е например GADTs. Как только вам нужно писать инстансы руками - всё, халява кончилась. Сразу нудно и скучно. Я так не люблю.
Будьте проще, пишите такие типы, что бы инстансы выводились автоматически. Типизировать можно и без GADTs, просто есть корневой тип с тегами, значения могут быть любых других типов, где значения в свою очередь могут быть любых типов. uniplate всё перепишет и обойдёт.
Теперь ближе к предметной области. Как выглядит задача парсинга неструктурированных данных?
Перед тем, как парсить мусор, надо сначала где-то взять этот мусор. Это может быть разное - массив PDF-ов, или html, или даже doc/rtf. Иногда и plain text, но в наше время это редкость
Допустим, мы будем парсить html. Как будет показано ниже, это не сильно отличается от парсинга чего угодно вообще
Могу посоветовать не смешивать вытягивание данных с веба и анализ данных. Вытягивание данных - процесс медленный, и в его течении у вас могут быть проблемы с сетью или вас забанят
Поэтому лучше вытащить все данные целиком и потом неспеша с ними разбираться, отделив процесс синхронизации мусора от процесса анализа мусора
Для того, что бы данные вытащить, если это веб - можно воспользоваться или wget, или httrack. Например, wget:
gist.github.com/voidlizard/c28…
gist.github.com/voidlizard/c28…
Способов выкачать сайт много, и об этом много написано. Останавливаться на этом не буду. Есть клинические случаи - когда нужна авторизация, и/или данные рендерятся из js на клиенте. Тут вам поможет, #например расширение SingleFile для firefox. Оно просто сдампит данные в...
... один файл, который будет еще и нормально просматриваться. Очень удобно, но нельзя выкачать всё. Есть способы сделать это, используя браузер в качестве клиента/спайдера, но я сам так еще не делал и это уже не фан, а тяжелый труд и много джаваскрипта
Что делать с этим html? Есть разные школы скрэпинга (scaping). Вкратце это: регекспы. Привязывание к классам/id тегов. Привязывание к меткам. Я решительно заявляю: да пошли они все. Это всё ненадёжно, если в такой предметной области можно вообще говорить о надёжности.
Поэтому действуем мы так: сначала разбиваем текст на токены. Разбиение может быть разным для вытаскивания разных... свойств, фактов, тегов, атомов. Называйте как хотите. Там, откуда я привожу скриншоты, это называется теги. Это не html теги. Это минимальные тегированные единицы
В востановлении структуры мы сначала обдёрем данные до минимальных возможных атомов, а потом из этих атомов/тегов восстановим структуру, оперируя их типом, взаимным расположением и наличием периодических закономерностей
Как нам разобрать текст на токены? Восстанавливать структуру мы будем исходя из того, что видит и понимает человек, но при этом данные должны быть машинно-читаемы. В общем, нам тут поможет или lynx или pandoc или html2text. Быстрее всех работает html2text, адекватнее всех - lynx
Я пока за lynx. pandoc показывает почти такие же результаты, но медленнее. Качество рендера не слишком важно. Читаем файл lynx-ом:

Обратите внимание, что в данных может быть какой угодно мусор (не utf8), поэтому санитизируйте и ввод в lynx и вывод из него. никаких исключений! Все должно работать пуленепробиваемо на каждом этапе. Пускай часть мусора и потеряется в процессе.
readProcessWithExitCode отсюда: process-extras. Позволяет писать и читать ввод/вывод процесса как байтстроки, не ломаясь на неюникодных символах. Починить текст можно при помощи стандартной decodeUtf9With ignore

Что дальше? Мы получаем портянку текста с разбиением на строки, с сохранением ссылок, при этом ссылки не идут вперемешку с текстом, а помечаются в тексте примерно так: [12]Twitter. Это очень удобно, и так умеет только lynx
Дальше нам надо токенизировать текст, и здесь начинается вуду. Лучше всего, когда восстановить структуру можно исходя из типов самих токенов, но это работает не всегда. В любом случае, что из себя представляют токены, зависит от контекста. Будь то источник данных...
или разделы внутри одного источника данных. В любом случае, тут у нас появляются токены и теги. Начнем с тегов:

Tag a TagValue. В результате парсинга на каждом этапе мы будем получать кучу тегов. Их надо 1) связывать между собой и привязывать к какой-то сущности (join!) и 2) фильровать, потому, что будет мусор. Задача определяется итерационно...
... ведь в в процессе её решения мы не знаем, с какими данными мы имеем дело! Поэтому Tag a. a - это ключ. Вначале это может быть просто Text, но в какой-то момент надо будет втащить туда позицию токена (позже), источник токена, вес токена и т.п. Но пока мы не знаем!
итак, мы получили (всё еще человекочитаемый) текст для анализа. Дальше нам надо вытаскивать из него атомы. Лучше не парсить всё в один проход. Нам 1) могут потребоваться разные разбиения 2) парсеры могут ломаться в произвольном месте и в лучшем случае...
... будет много бэк-трекинга. Побудем немного малярами Шлёмиэлями, и будем определять функции экстракции примерно как:
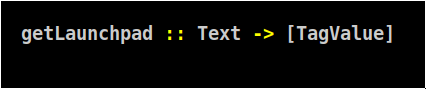
т.е 1) каждая функция работает со всей портянкой текста 2) и это текст, а не токены
Удобнее оперировать с потоком токенов, да еще и проматывать его, но мы пока не знаем какое разбиение будет подходить для экстракции каждого атома
Удобнее оперировать с потоком токенов, да еще и проматывать его, но мы пока не знаем какое разбиение будет подходить для экстракции каждого атома
а TagValue а не Tag потому, что TagValue тут достаётся в качестве атома, и один атом ничего не знает про другой атом. Где-то на верхнем уровне функция, которая разбирает кусок мусора знает о контексте и может объединить TagValue в Tag. Да и неважно - uniplate всё перепишет
Дальше как нам разбивать? Можно парсить регекспами. Можно attoparsec. Attoparsec такой же удобный как регекспы, но мощнее - можно писать рекурсивные парсеры, и код на нём легче понимать и модифицировать, чем регекспы
и каждая функция-экстрактор у нас получится элементарным парсером на Attoparsec. Поэтому, берём Attoparsec и...
... и выкидываем его нахрен. он 1) неудобен, если мы хотим работать с разбиением по строкам 2) очень хрупок 3) на нём не удобно обрабатывать промежуточные результаты парсинга, которые тоже суть мусор
еще раз: тип атома зависит не только от его вида, но и от контекста. Чем _уже_ контекст - тем более универсальный получается экстрактор, но и тем проблематичнеее распарсить. Первая задача: для каждого экстрактора сузить контекст, что бы захватывать меньше лишнего мусора
Что было более конкретно, будем работать с этим примером:
gist.github.com/voidlizard/575…
Для начала: найдем название проекта и его тикер (symbol). Symbol в моей задаче вообще и есть ключ сущности, по которому атомы будут собираться. Как и положено в анализе мусора - он неуникальный!
gist.github.com/voidlizard/575…
Для начала: найдем название проекта и его тикер (symbol). Symbol в моей задаче вообще и есть ключ сущности, по которому атомы будут собираться. Как и положено в анализе мусора - он неуникальный!

по виду текста понятно, что в нём есть секции, секции имеют довольно стойкие названия, и на них можно ориентироваться. поэтому будем вырезать области, где будем искать интересующие нас значения, привязываясь к строкам. Вот как это выглядит:
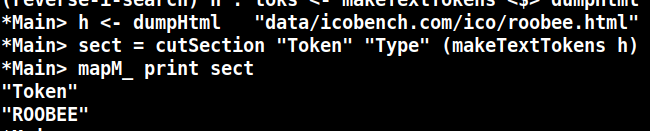
ой, слишком просто. немного контекста:

ну понятно, что разобрать такое проще всего тупо паттерн-матчингом:
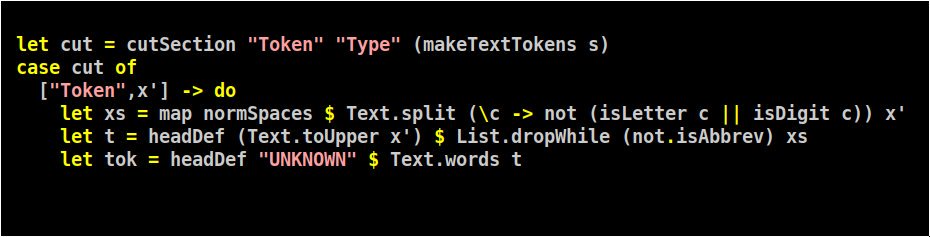
данные у нас дичайше денормализованы, в том, что является токеном, может быть всё что угодно, так что бы вытащить именно тикер, надо еще поработать. Помните attoparsec? Он ушёл, но не слишком далеко:

обратите внимание на endOfInput, это важно
cutSection, кому интересно:
gist.github.com/voidlizard/efb…
gist.github.com/voidlizard/efb…
продолжать?
эта серия твитов похожа на задачу: в процессе я не знаю точно, как это делать и что должно получиться в итоге. всё как я люблю.
С symbol всё было просто. Но так просто бывает не всегда: атомы могут иметь другой вид, нежели строки, отсутствовать или дублироваться. Или быть просто мусорными. Рассмотрим пример:
Raised: значение типа деньги. Попадает под предыдущий паттерн: сначала строка-название тега (напомню, это был html, и мы смотрим на то, что нам напарсил lynx и токенизатор - еще раз: lynx рулит)

Всё просто, да? Но нет. В каком-то другом файле так:

в оригинале так:

А в html так. Увы, lynx тут бессилен.

Т.е это даже не два противоречивых атома, а один, слипшийся из двух и с невменяемой цифрой на выходе. Что тут можно сделать?
1. Ввести файл с ручными корректировками - у нас же есть теги, и альтернативный тег брать из файла с корректировками с большим весом. Подход годный! Но лень.
2. Хранить распарсенные теги в отдельном человеко-редактируемом файле (yaml) и фиксить руками, а дальше для репортов работать с ним, а не с сырыми файлами. Подход годный! Файл этот всё равно нужен...
... но он процесс решения итеративный, файл будет постоянно перезаписываться и придется править каждый раз. Что лень. Поэтому лучше это и предыдущая опция (но лень)
3. Добить обработку таких клинических случаев - тут код пример странный вид, странный для других сайтов, но если он будет работать и нормальными атомами тоже - то да и ладно:

ну понятно - если в числе встречается группа из 4х цифр - значит, что-то слиплось. Для этого сайта это так, для другого может быть не так. Но всегда есть теги с большими весами и ручное редактирование промежуточного представления.

обратите внимание на интенсивное использование функий из пакета safe. Без них в парсинге мусора никуда - лучше пробел или пустая строка, чем бесконечные maybe/either или исключения. П - пуленепробиваемость.
Пока всё легко, да? Каждый атом легко идентифицируется тегом, который находится непосредственно перед ним, и атом один. Добавим огня. Люди. С именами, должностями и ссылками, плюс их много. Плюс...
именем может быть вообще что угодно. Junior Developer. Security Analyst. Max Crowdfund. Ну, вы поняли:

Для анализа такого становится важным, кто за кем идёт, что из себя представляет каждый токен, мы знаем, что сначала _обычно_ идёт имя, потом роль, потом ссылка на профиль. Ну и имя может быть вооще любым, но правила написания - более менее стабильны:
gist.github.com/voidlizard/03e…
gist.github.com/voidlizard/03e…
поэтому вводим другую токенизацию: введем позицию в тексте, что бы смотреть блико-далеко, что после чего, и введем правила, которые будем применять к строкам, что бы понять, чем они могут быть, а чем нет. См. код, там более менее понятно
Сразу непонятно, что лучше сработает - явные стоп. слова, соответствие правилам написания имён, то, что мы в целом знаем об именах, правила чередования. Можно еще сначала определять, что есть другие токены (ссылки, должности) и выкидывать их из набора токенов.
То, что останется через несколько итераций - скорее всего будет именами. Тогда мы можем вернуться к ним, и предполагая, что и имена мы нашли - то то, что за ними следует, рассматривать как должности.
Если мы не знаем явно стоп-слова - можно из попытаться вычислить исходя из частотного анализа по корпусу в целом, и рассматривать порядки частоты встречаемости, беря её как вес, например. И из множества разбиений выбрать то, где суммарный вес будет максимальным.
Я тут добился удовлетворительных результатов без таких наворотов, но бывает всяко. Т.е сузить, взять разные разбиения, посчитать веса и выбрать разбиение с максимальным весом - к такому я был готов (но обошлось).
обратите внимание, что насколько нечёткая задача, настолько нечёткие и способы обработки. Секция может не закончиться, её можно сузить до, во время или после. Главное - максимальная пуленепробиваемость везде. Например, искал людей в одном месте, потом решил искать в другом...
Парсер остался тем-же, но сузил область предварительно - функция работает с текстом, но тут я разобрал его на токены, сузил и собрал обратно (Шлёмиэль одобряет!)

Продолжаем?
Сейчас небольшое отступление. Информацию надо искать по разным файлам, особенно, если мы хотим подмешивать туда корректировки (свои теги с весами) или правила. Как читать файлы по маске?
Надо ли использовать какие-то пакеты, которые типа haskellysh shell - имитируют шелл на хаскелле? Turtle, Shelly ?
Нет. С ними, как c GADTs: типичный паттерн: 1) взял Turtle, ???, 3) выкинул Turtle.
Нам нужен filemanip и readProcessWithExitCode для байтстрок:

namesMatching - это просто лучшее. Находит файлы как шелл, но ещё лучше
а, ну да - и Data.ByteString.readFile еще (санитизация ввода!)
Теперь о том, что с этим хозяйством делать.
1) Надо это сдампить в файл, что бы вручную подчистить от мусора если надо. Yaml подходит:
1) Надо это сдампить в файл, что бы вручную подчистить от мусора если надо. Yaml подходит:

обратите внимание, что для параметрического типа TH не смог сделать ToJSON/FromJSON, но всегда можно добить руками (параметр в Tag мне тут важнее халявы)
Что мы тут пишем в файл - зачем склеиваем списки? каждый список [Tag Text] - исходно был файлом. Но если мы соединяем данные из разных источников, то сами файлы уже неважны. Важны теги, по которым будем группировать атомы.
А чем больше уровней сложности - тем более дикий вид имеет результирующий Yaml. Так что самое время список сделать плоским, что бы на выходе как-то так:
gist.github.com/voidlizard/359…
gist.github.com/voidlizard/359…
а вот и опечатка. не "сложности", а "вложенности"
вообще-то, тут уже можно было бы писать не в yaml, а в sqlite: у нас есть таблицы (теги), есть ключи, есть значения. но лень - да и всё равно потом в памяти все обрабатывать. но sqlite пока не исключается.
Мы почти у развязки. Вот мы напарсили тегов, что с ними делать-то? Мне вообще были нужны отчёты по разным параметрам: размеры hardcap/softcap, разлёт hardcap и softcap, размеры команды, страна, площадка запуска и как это всё влияет на сборы (или нет)
Дальше мы что делаем? Собираем теги по ключам...
кстати, ключи могут быть неуникальны - названия символов (токенов) вроде уникальны в рамках площадки, но вообще неуникальны. Мусор повсюду. Поэтому, добавляем в ключ уникальный хэш:
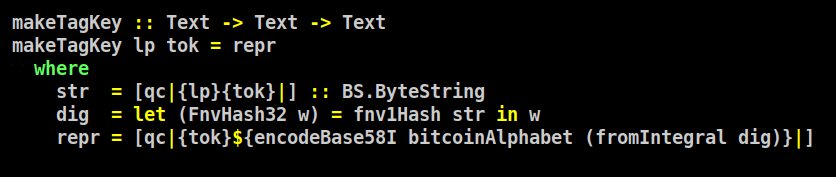
Вот так вот более уникально: AGLC$4V5suD
кстати, посмотрите на [qc|{x}|] - interpolatedstring-perl6 тоже один из мега-полезных пакетов
Ну так вот, отчёты. Допустим, какие люди участвуют во многих проектах сразу и кто они там:

собираем словарь по ключам тегов, группируем теги. Это, кстати, очень частая идиома:

дальше просто в несколько forM_ обходим, достаём, фильтруем если надо и строим отчёт. Можно узнать много интересного и поучительного.
gist.github.com/voidlizard/4d9…
gist.github.com/voidlizard/4d9…
по этой задаче практически всё, чуть позже будет заключение. и может быть, расскажу как восстанавивал таблицы, используя периодические закономерности в данных. ну или нет. давно было. может, код найду
да, если есть вопросы - спрашивайте. а то я что-то выдохся пока
Так вот. Тут, собственно, нашлось мало нечёткого -- задача быстро кончилась до того, как удалось применить тяжелую артиллерию. Но не совсем - кое что парсится плоховато, и там можно еще развернуться. Например...
Вот тут есть список экстракторов, которые последовательно применяются к тексту. Сейчас это делается один раз и для фиксированного списка. Но это лёгкий случай...

... в тяжелом же случае - можно применять разные наборы экстракторов (перестановки), написать оценочную функцию - и выбирать результат с наилучшей суммарной оценкой
А цель всего этого такова: научиться писать парсеры таким образом, что бы парсер одного источника - подходил к другому. Иногда такое получается сделать
и в заключении о #Haskell - на таких задачах он хорош: в памяти ничего подолгу не висит, ленивость не мешает, а помогает, типы тоже скорее помогают и типизация здесь умеренная, без фанатизма. Ну и repl есть - удобно просто исследовать данные и проверять гипотезы







