
IPEADATAPY
Aproveitei meus últimos dias de sossego destas férias para escrever esta thread falando um pouco sobre (e consequentemente divulgando) um projeto que trabalhei sozinho durante boa parte do primeiro semestre de 2019. Trata-se do pacote Python ipeadatapy. Segue 👇
Aproveitei meus últimos dias de sossego destas férias para escrever esta thread falando um pouco sobre (e consequentemente divulgando) um projeto que trabalhei sozinho durante boa parte do primeiro semestre de 2019. Trata-se do pacote Python ipeadatapy. Segue 👇

PyPI: pypi.org/project/ipeada…
GitHub: github.com/luanborelli/ip…
Documentação: luanborelli.net/ipeadatapy/doc…
GitHub: github.com/luanborelli/ip…
Documentação: luanborelli.net/ipeadatapy/doc…
Antes de entrar no pacote propriamente dito, um prelúdio: no começo do ano eu colaborava com a equipe do Ipeadata, do Ipea, em seu projeto de "revitalização" do banco de séries econômicas. "Revitalização"? Sim. O Ipeadata nos últimos anos se encontrava praticamente abandonado,(+)
com uma grande quantidade de séries desatualizadas, mal documentadas (com deficiências sérias em seus metadados, por exemplo) e com a inclusão de novas séries interrompida, dentre outros diversos problemas que não vêm ao caso agora. Uma nova equipe foi constituída para (+)
fazer frente a este projeto e lá eu me encontrava. Dentre nossas tarefas estavam muitas rotinas técnicas, como a identificação das séries mais importantes do banco (em termos de consultas do público, por exemplo), das séries com deficiências de metadados, das séries com atraso(+)
de atualização, etc.... Isto para que, dentre outras coisas, os esforços de reparação fossem eficientemente direcionados. (+)
Pois bem, para boa parte destas tarefas eu voluntariamente desenvolvi uma série de rotinas de programação. Particularmente, utilizei a linguagem Python por possuir, previamente, maior familiaridade. Uma parte da equipe, a saber, o núcleo de estatística, tendo (+)
(+) notado meus trabalhos, conversou comigo e me apresentou um pacote em R por eles desenvolvido (ipeadataR), um API wrapper que fazia a ponte entre a API já existente do Ipeadata e o R, permitindo a recuperação dos dados do banco do Ipeadata diretamente via código R (+)
e em seguida me propuseram: por que não desenvolver um equivalente em Python? Gostei da ideia e felizmente recebi aval da equipe para trabalhar neste projeto. Daí, surgiu o Ipeadatapy. (+)
Ok, mas o que exatamente é o Ipeadatapy? O Ipeadatapy é um API wrapper. Uma API é um conjunto de rotinas e padrões de programação para acesso às informações de um software ou plataforma baseado na Web, no caso, os dados do Ipeadata. Um API wrapper, por sua vez, é um conjunto (+)
de rotinas para acesso à uma API. Em bom português, para o povão: com um API wrapper você pode acessar os dados das séries econômicas do Ipeadata direto de seu código de programação, sem precisar acessar o site do Ipeadata e baixar planilhas para depois importar manualmente. (+)
Ou você pode mesmo utilizar o API wrapper para baixar uma (ou várias!) série de dados econômicos do Ipeadata direto de seu ambiente de programação, sem precisar acessar o site (nada moderno) do Ipeadata e acessar e baixar as séries uma por uma. Enfim, são várias as utilidades.(+)
Portanto, esquematizando, a coisa se dá mais ou menos assim:
Python <-> Ipeadatapy <-> API do Ipeadata <-> Banco de dados do Ipeadata
Neste momento uma pergunta deve surgir na cabeça de muitos: mas por que uma API wrapper? Por que não usar diretamente a API? (+)
Python <-> Ipeadatapy <-> API do Ipeadata <-> Banco de dados do Ipeadata
Neste momento uma pergunta deve surgir na cabeça de muitos: mas por que uma API wrapper? Por que não usar diretamente a API? (+)
Nesta questão reside o ponto central que justifica o desenvolvimento do pacote. Vamos lá: por que não utilizar diretamente a API? Por que eu acessaria algo que acessa a API para mim se eu mesmo poderia acessar diretamente a API? (+)
Em primeiro lugar, a grosso modo, é "impossível" utilizar diretamente uma API. Para fazer uma consulta à API você inevitavelmente precisará programar, em alguma linguagem, um call de API. Uma API não é um software bem apresentado e amigável de fácil utilização (+)
para um leigo em assuntos computacionais. Veja o que é a API do Ipeadata: ipeadata.gov.br/api/. Não é tão intuitivo para o pesquisador que não necessariamente sabe programar ou para o estagiário do mercado financeiro que só quer atualizar a porcaria da taxa de juros (+)
nas planilhas do hedge fund em que trabalha. Ademais, por mais que o usuário tenha algum conhecimento computacional e elabore um call de API por conta própria e consiga recuperar os dados do banco, há um segundo problema: os dados são recuperados do banco em forma bruta, (+)
i.e., praticamente assim como são no banco de dados SQL do Ipeadata. O problema? O problema é que o data frame será recuperado, por exemplo, com rótulos de linhas e colunas nada intuitivos, em termos puramente técnicos, com uma série de informações irrelevantes para o usuário.(+)
Em suma: nada "user-friendly". Isto posto, o API wrapper tem exatamente o papel de poupar o usuário de programar por conta própria os calls da API e de traduzir a API num conjunto de funções intuitivas, amigáveis ao usuário, que facilite seu trabalho e que retorne apenas (+)
os dados essenciais, limpos, traduzindo os termos técnicos em termos inteligíveis e eliminando o que for desnecessário. Este foi, portanto, meu trabalho no desenvolvimento do Ipeadatapy: programar as calls e traduzi-las em funções claras e intuitivas ao público geral, (+)
que supram as principais necessidades do usuário comum e retornem data frames inteligíveis e já, previamente, relativamente bem tratados. Tentei ao máximo desenvolver o pacote com o intuito de torná-lo simples de ser utilizado pelo mais leigo dos usuários, (+)
mesmo aquele que nunca sequer programou uma linha de código em Python. Creio (ao menos espero) que, seguindo a documentação, mesmo este usuário seja capaz de utilizar o pacote. (+)
Sem mais delongas, vamos ao pacote: ele encontra-se disponível no PyPI (pypi.org/project/ipeada…) e em meu GitHub (github.com/luanborelli/ip…). Sua documentação está hospedada aqui: luanborelli.net/ipeadatapy/doc….
O que você pode fazer com o Ipeadatapy? Arranharei aqui a superfície do pacote, expondo por alto suas funcionalidades. Para os que se interessarem mais profundamente, sugiro que confiram a documentação. Vamos lá: (+)
A minha ideia na construção do pacote foi que este contemplasse um conjunto autossuficiente de funções sinérgicas entre si, que permitissem a navegação através dos dados do Ipeadata de maneira lógica e independente. Para isso, adotei a seguinte abordagem: (+)
Supus que, num primeiro momento, o usuário desejará pesquisar e encontrar a série econômica de seu interesse. Num segundo momento, desejará avaliar os detalhes e confirmar se de fato aquela série é a que deseja (desejará verificar detalhes como frequência, unidade, etc.) (+)
E num terceiro momento, desejará efetivamente analisar os dados da série, plotar gráficos, trabalhar com esta de modo geral ou simplesmente exportá-la para uma planilha. Tomando então esta abordagem como representativa das necessidades do usuário mediano, (+)
o esquema de uso pensado para o pacote pode ser aproximadamente representado, em três fases, da seguinte maneira:
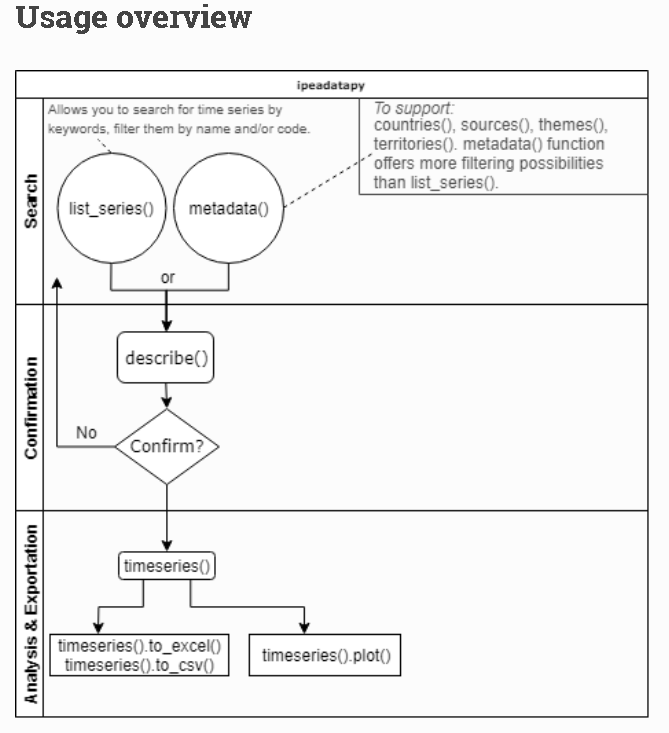
A função list_series() lista todas as séries disponíveis no Ipeadata. Através de seus parâmetros, permite a busca e filtragem das séries por palavras chaves, servindo como um pseudo-sistema-de-busca de séries no banco. Com ela, você pode encontrar o código de sua série desejada.


A função metadata() é uma versão expandida da função list_series. Ela também lista todas as séries disponíveis no Ipeadata, no entanto não apenas retorna os nomes e códigos das séries como também diversos outros metadados destas. (+)

Ao mesmo tempo que ela pode ser útil por retornar mais informações sobre as séries e permitir buscas "avançadas" filtrando as séries por detalhes (metadados), pode ser também mais confusa, atrapalhando a busca exatamente pela quantidade excessiva de dados que retorna. (+)
Portanto, list_series() permite a "busca simples" de séries enquanto metadata() a busca "avançada", com uma gama muito mais ampla de parâmetros de filtragem. Fica a critério do usuário, de acordo com a conveniência, qual utilizar. (+)
Através da função metadata(), por exemplo, você pode conferir as séries disponíveis do Ipeadata por país, fonte, tema, território, etc., bastando para isto utilizar os respectivos parâmetros de filtragem. Mas quais são as opções de filtragem? Isto é, (+)
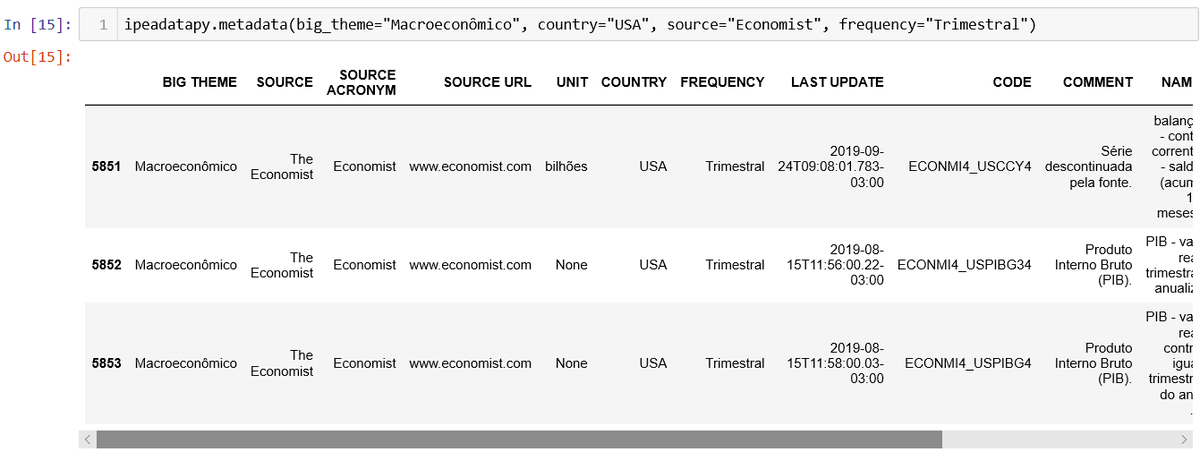
Quais são os países, as fontes de dados, os temas, os territórios... disponíveis no Ipeadata? É fácil descobrir. Para isso existem as funções de suporte: countries(), sources(), themes(), territories() que retornam, (+)
respectivamente, a lista de países, fontes, temas e territórios disponíveis no Ipeadata e que podem ser utilizados para filtrar os resultados da função metadata(), a fazendo retornar apenas séries de acordo com os parâmetros especificados. (+)




Uma vez encontrada a série desejada utilizando os artifícios acima, o usuário pode obter ainda mais detalhes da série em questão através da função describe(). Ela retorna informações como a descrição da série e outros dados essenciais; é uma espécie de quadro-resumo da série. (+)

Finalmente, uma vez confirmado tratar-se da série desejada, o mais importante, os dados da série, podem ser conferidos através da função timeseries(), bastando informar o código da série obtido anteriormente. Daí obtém-se o data frame da série e pode-se trabalhar como desejar.(+)
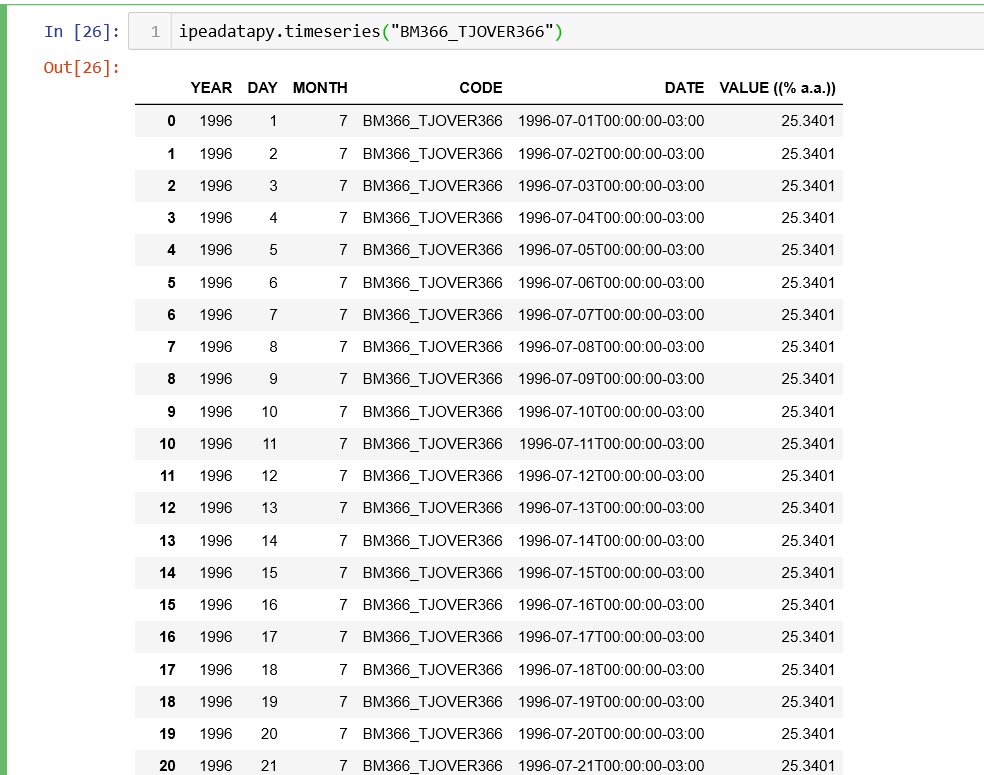

Está resumida a ópera. Trata-se, basicamente, disso. O pacote já estava pronto há alguns meses mas nunca havia sido divulgado. Me senti na obrigação de divulgá-lo agora pois creio que pode ser de grande utilidade para muita gente (mais até mesmo do que para mim), (+)
seja para integrar diretamente os dados do Ipeadata a modelos computacionais estatísticos e/ou econômicos escritos em Python, seja simplesmente para utilizar como substituto ao site do Ipeadata, uma vez que este é bastante ultrapassado e deficiente, apresentando (+)
muitos problemas que vão desde a ineficiência de seu sistema de busca até a incrível impraticidade de se exportar dados através dele. Com o pacote tanto a busca das séries quanto sua exportação podem se tornar mais fáceis e práticas. (+)
Além disso, vale comentar que o pacote oferece um conjunto de dados sobre as séries muito mais amplo do que o site (no site muitas informações do banco são omitidas, enquanto recuperando via API (+)
todas os dados são recuperados).
Considerações finais: (i) devo ressaltar que estou longe de ser um cientista da computação e meus códigos podem estar muito distantes da otimalidade computacional, podendo comportar até mesmo algumas gambiarras. (+)
Considerações finais: (i) devo ressaltar que estou longe de ser um cientista da computação e meus códigos podem estar muito distantes da otimalidade computacional, podendo comportar até mesmo algumas gambiarras. (+)
(ii) Hoje não faço mais parte diretamente da equipe do Ipeadata, tendo passado a trabalhar com outros assuntos no Ipea, o que torna difícil para mim dar prosseguimento a melhorias no pacote. Não obstante, o código é cem por cento aberto (+)
Isto significa que qualquer um que desejar contribuir para a sua melhoria, seja computacional seja pela elaboração e desenvolvimento de novas funções será totalmente bem vindo.
That's it. Obrigado. Espero ter conseguido ou conseguir ajudar alguém com esse pacote.
{fim}
That's it. Obrigado. Espero ter conseguido ou conseguir ajudar alguém com esse pacote.
{fim}

