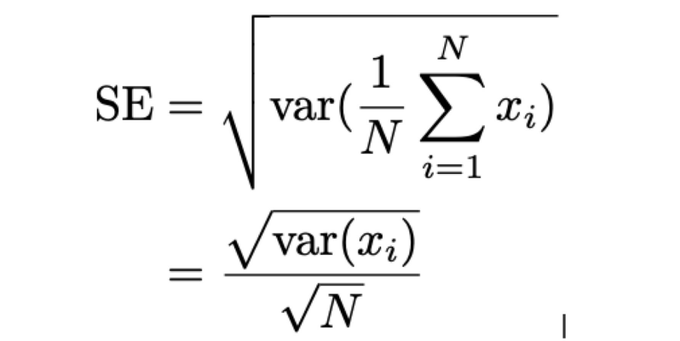(1/5) One of the most surprising and little-known results in classical statistics is the relationship between the mean, median, and standard deviation. If the distribution has finite variance, then the distance between the median and the mean is bounded by one standard deviation. 

(2/5) We assigned this as a HW exercise in a class I taught as a grad student at MIT circa 1991
Coincidentally, it was written up around the same time by C. Mallows in "Another comment on O'Cinneide" The American Statistician, 45-3
Proof is easy using Jensen's inequality twice:
Coincidentally, it was written up around the same time by C. Mallows in "Another comment on O'Cinneide" The American Statistician, 45-3
Proof is easy using Jensen's inequality twice:


(4/5) What about in higher dimensions?
Yes, defining the median appropriately, that works too: median here is the "spatial median": the (unique) point m minimizing the sum of distances E(|x-m|-|x|) to the sample points.
The result appears in this book:
amazon.com/Random-Vectors…
Yes, defining the median appropriately, that works too: median here is the "spatial median": the (unique) point m minimizing the sum of distances E(|x-m|-|x|) to the sample points.
The result appears in this book:
amazon.com/Random-Vectors…


(5/5) Results like this are not just curiosities, but quite useful in practice as they allow estimates of one quantity given the other two in a distribution-free manner. This is important in meta-analyses of studies in biomedical sciences etc
(Open Access) ncbi.nlm.nih.gov/pmc/articles/P…
(Open Access) ncbi.nlm.nih.gov/pmc/articles/P…

• • •
Missing some Tweet in this thread? You can try to
force a refresh