
(1/20) Tweetorial on this statement…
”…red flag…The investigators….already taken an interim look…did not stop the study early….dampens optimism for an overall positive outcome”
Is this a red flag? Maybe…maybe not…depends on how optimistic you were to start.
”…red flag…The investigators….already taken an interim look…did not stop the study early….dampens optimism for an overall positive outcome”
Is this a red flag? Maybe…maybe not…depends on how optimistic you were to start.
(2/20) I don’t have the details of the interims. If someone has them, I’ll followup with this specific trial. Without them, I’m going to discuss the general principles. The principles are easier to see in a single arm trial. They generalize completely to two arms.
(3/20) Example…dichotomous outcome, want to beat a 40% control rate. A 200 patient single arm trial has 80% power for a true 50% treatment rate. Being adaptive, we will add interim looks at N=100 and N=150 that allow us to stop early for success or futility.
(4/20) The table below shows the p-value and data thresholds for stopping for success. The p-values were calibrated (group sequential design) to maintain overall 2.5% type 1 error accounting for the multiple looks. We can then solve for the required data that stops early. 
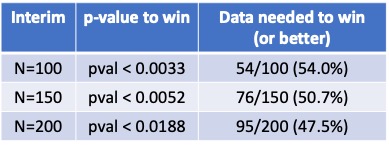
(5/20) Every good trial should have a futility rule! If our observed data indicates that eventual success is unlikely, we will stop for futility. For the technical, we are using a 5% predictive probability threshold (I would set this higher, but 5% is a common choice)
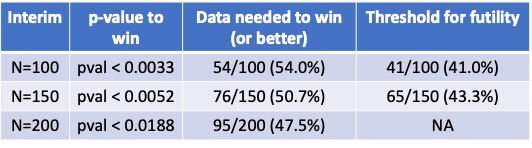
(6/20) Ok, so now we know the rules. You are reading the news and see “the trial did not stop at N=100”. Should this be met with celebration, despair, or a yawn?
(7/20) What does “no stop at N=100” tell us? We know the rules….we would have stopped for success with 54/100 or more responders, or for futility with 41/100 or fewer. Thus, we know the data is between 42/100 and 53/100.
(8/20) At N=200, we need 95/200 (47.5%) or better to win. The range 42/100 to 53/100 contains percentages above and below that value, and there is still a lot of random variation in the last 200 observations. We certainly can’t guarantee any eventual trial result.
(9/20) Your reaction (good news? bad news?) depends on what you thought before the trial. Knowing “no stop at N=100” is information. Being good Bayesians…let’s think about how different people should adjust their beliefs when given this knowledge.
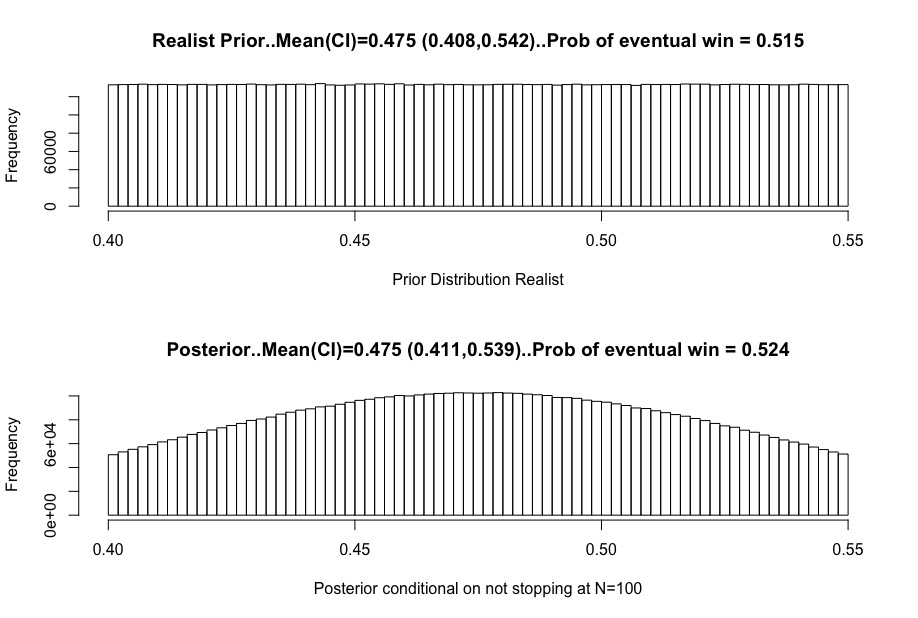
(10/20) First, the “realist”….prior to the trial they thought the true rate might be anywhere from 40-55% (technically we are given them a uniform prior distribution over that range).
(11/20) Their original (pre trial) belief had a best guess of a 47.5% treatment rate (90% interval 40.8-54.2%), and they thought the trial had a 51.5% chance of winning. The trial is powered for a 50% true rate, but the realist recognized that a 50% rate isn’t guaranteed.
(12/20) The realist’s beliefs change (prior to posterior calculation) upon learning “no stop at N=100”, but the changes are quite minor. Their point estimate, 90% credible interval, and estimated chance of trial success are all pretty close. They yawn.
(13/20) Now the optimist…uniform prior between 40-100%. They held expectations of a wonder drug. Their prior best guess is 70% (range 46-94%). They apriori thought the trial had an 87.8% chance of winning. The “no stop at N=100” is indeed disappointing.
(14/20) The trial would have stopped for data 54/100 or better. Since that didn’t happen, true rates like 70,80,90% are essentially eliminated. The realist never thought them likely anyway, but the optimist has lost that hope.
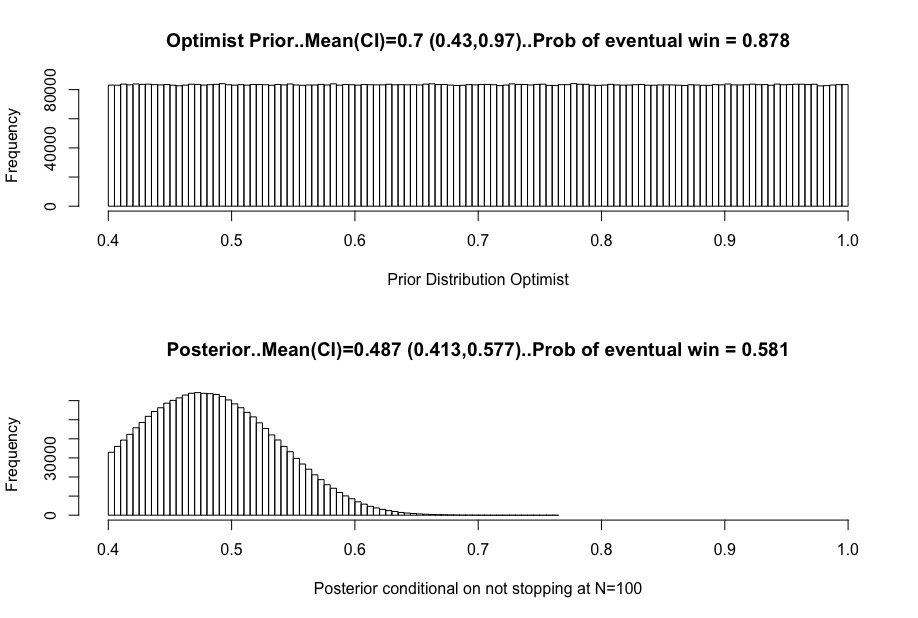
(15/20) The optimist's adjusted belief looks similar to the realist. This is good, we hope beliefs converge with more data. Note the optimist still thinks there is a 58.1% chance of trial success. Any disappointment is from the change, not the probability itself.
(16/20) Suppose you were both uncertain and concerned about harm, with a prior uniform from 30-70% percent. Their change in beliefs is below. They have also lost hope of the 65% wonder drug, but also eliminated their fear of harm.
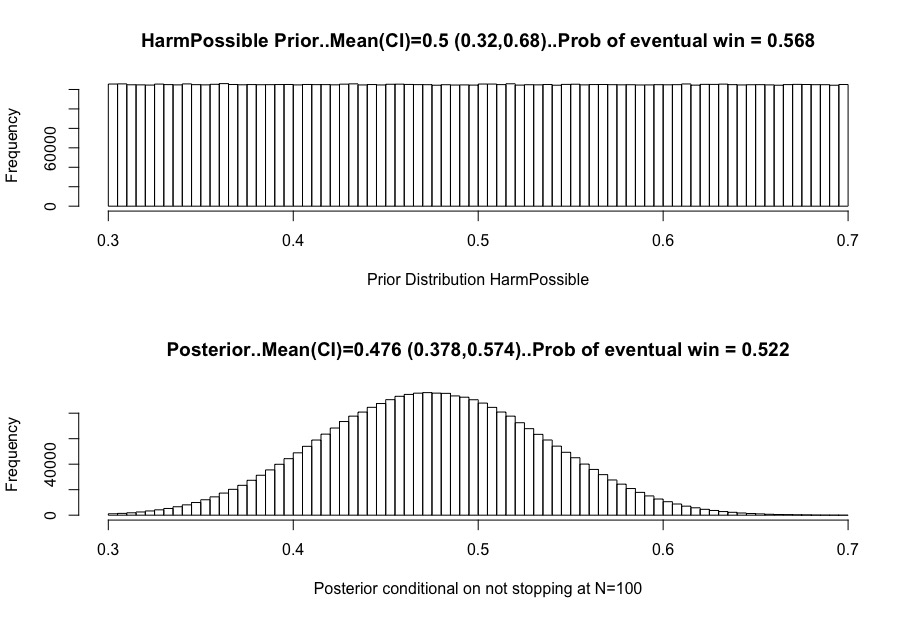
(17/20) The three individuals have converged significantly. They all retain considerable uncertainty, including about whether the trial will ultimately succeed. But statements like “the non-stop is a red flag” depend on your original beliefs.
(18/20) If you were the realist, the non-stop was expected. Your beliefs haven’t changed much. If you were the optimist, then the non-stop is a disappointment (I’ve done a LOT of trial designs and pre trial optimism generally does not match reality).
(19/20) This is generally true of trials that continue. Well designed trials still retain considerable uncertainty about whether they will eventually “win”. But often a “non stop” is information that extreme values of the parameters can be discounted.
(20/20) As noted above, the exact details of the interims matter. Depending on the thresholds, you are get more/less information about high/low values of the parameters. These calculations should be redone in each example.


