
Clinical Trial Designer. Director of Modeling and Simulation, Berry Consultants. Statistics PhD Carnegie Mellon.





 (2/n) A lot of good examples are basket trials in oncology.
(2/n) A lot of good examples are basket trials in oncology.
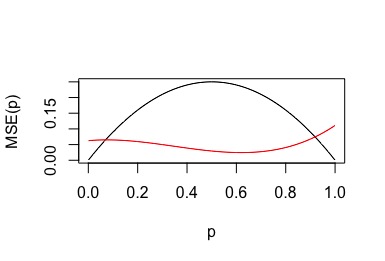
 (2/n) Data is noisy…a good therapy can look bad early in a trial, and a null(dud) therapy can look good. A lot of statistical theory is dedicated to quantifying this range. When can we be “sure” the data is good enough the drug isn’t a dud? When can we be “sure” it works?
(2/n) Data is noisy…a good therapy can look bad early in a trial, and a null(dud) therapy can look good. A lot of statistical theory is dedicated to quantifying this range. When can we be “sure” the data is good enough the drug isn’t a dud? When can we be “sure” it works?
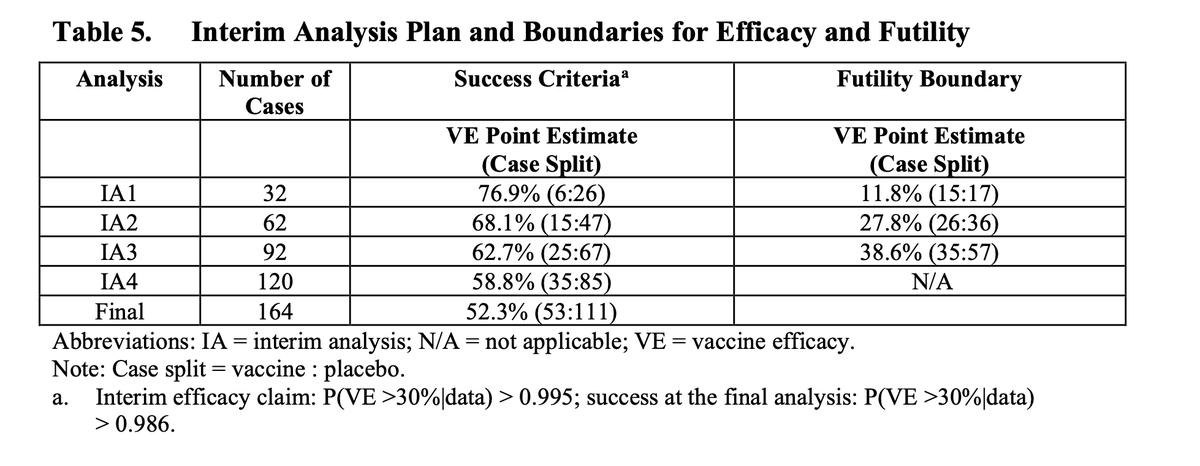
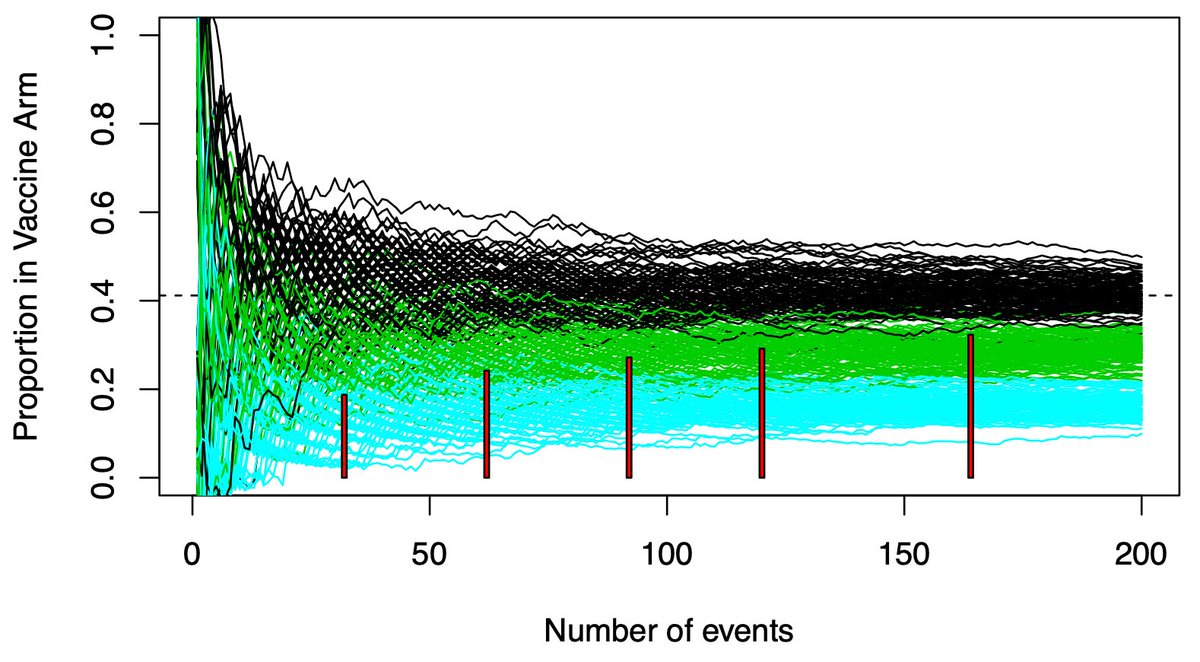
 (2/12) Your timing matters. The information you could use to select an arm accumulates over time.
(2/12) Your timing matters. The information you could use to select an arm accumulates over time.
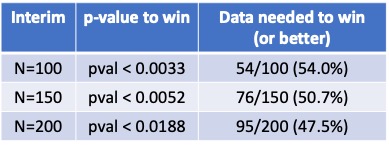
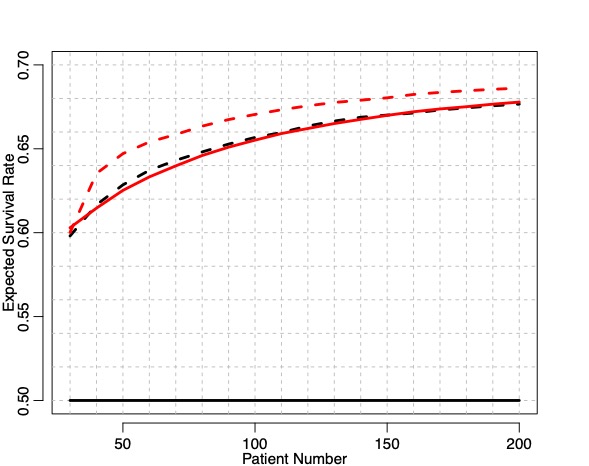
 2) Simple example…dichotomous outcome, you have a novel therapy and resources for 60 patients. You also have a database of untreated patients showing a 40% response rate. How can you incorporate the database into the trial?
2) Simple example…dichotomous outcome, you have a novel therapy and resources for 60 patients. You also have a database of untreated patients showing a 40% response rate. How can you incorporate the database into the trial?