
First, we must not let the tail wag the dog.
Which should one decide first?
Choose the endpoint, then calculate the sample size
or
Calculate the sample size, then choose the endpoint
Which should one decide first?
Choose the endpoint, then calculate the sample size
or
Calculate the sample size, then choose the endpoint
They are, of course, presented together so it is in simultaneous in PRESENTATION to the public but this Twitter group is for intelligent people who think about where knowledge comes from, not for soundbite-swallowers.
Yes the first 22 people are 100% correct! Maybe I should always run my tweetorials at 04:29 London time, when the trolls are asleep.
For those wanting to play along at home, I am looking at the "Moderate Covid" design. There appear to be several similar remdesivir trials on ClinicalTrials.gov, and I have happened to pick NCT04292730.
First the praise
They weren't sure what to look for, so they went for something that didn't need any understanding of medicine.
Even the janitor knows that if you get home alive within 14 days, that is better than still being stuck in hospital (or dead) at 14 days.
They weren't sure what to look for, so they went for something that didn't need any understanding of medicine.
Even the janitor knows that if you get home alive within 14 days, that is better than still being stuck in hospital (or dead) at 14 days.
At the Janitors' Club, they can have discussions like this.
"My mom was really ill. She was in hospital for a month."
"Ah, my uncle did better. He was home in a week."
They don't need to know any test results, decide which tests are more important, or by how much.
"My mom was really ill. She was in hospital for a month."
"Ah, my uncle did better. He was home in a week."
They don't need to know any test results, decide which tests are more important, or by how much.
There's nothing special about 14 days. It's a made-up time. You could do it by chopping at any number of days.
But you are not allowed to decide afterwards. Why?
But you are not allowed to decide afterwards. Why?
Whenever there is a company involved, with investors paying big $ to run a trial, they want a return, and this puts intolerable pressure on investigators to present a positive picture.
This is not financial pressure - it is desire to avoid embarrassment.
This is not financial pressure - it is desire to avoid embarrassment.
To protect investigators against the temptation to pick-and-choose endpoints, we require them to specify the endpoint, e.g. "Getting home by 14 days", in advance.
This way, when a trial is negative, they can proclaim innocence to the company.
This way, when a trial is negative, they can proclaim innocence to the company.
"Not my fault, I have no choice on what to present.
I know that it is significant for going-home at 4 days, but we prespecified 14 days. Just be happy people can't pick and choose, because it is significant the other way at 19 days!"
I know that it is significant for going-home at 4 days, but we prespecified 14 days. Just be happy people can't pick and choose, because it is significant the other way at 19 days!"

I know this from personal experience because I have seen it extensively in the great "Bone Marrow Cell Therapy for Heart Failure" worldwide fiasco.
Investigators would confidentially admit fudging or spinning the results to be positive, because of
- embarrassment of trial being neutral
- wanting to give patients hope
- not wanting to have to sack researchers dependent on research money, in turn dependent on positive results
- embarrassment of trial being neutral
- wanting to give patients hope
- not wanting to have to sack researchers dependent on research money, in turn dependent on positive results
Janitor endpoints, yes-no of a very simple thing, like "Gone home at 14 days" are good in one way.
Which way?
Which way?
Yes! First 5 answers are correct. 6th answer wrong.
The endpoint of "gone home at 14d" is not unbiased, in an unblinded trial, since staff (and patients) may be happier to send home with the feeling of protection, even if it is from Francisoglimeprivir and therefore useless.
The endpoint of "gone home at 14d" is not unbiased, in an unblinded trial, since staff (and patients) may be happier to send home with the feeling of protection, even if it is from Francisoglimeprivir and therefore useless.
It's clearly not specific for corona-virus. Indeed that is its strength.
When we don't know much about the disease, it is hard for scientists to decide what to use as the endpoint.
When we don't know much about the disease, it is hard for scientists to decide what to use as the endpoint.
It is easy for stupid people to decide, because stupid people think that everything is of equal difficulty (and perhaps easy), since they do not have experience of solving problems of varying difficulty and seeing what makes some problems difficult.
I should emphasise that it is easy for ONE scientist to decide, because as an individual a scientist can just pick a thing and declare it to be good.
But scientistS (plural) have a language of discourse and need to persuade each other, and that is what makes science good.
But scientistS (plural) have a language of discourse and need to persuade each other, and that is what makes science good.
Does it need fewer patients?
Let's think about numbers. How many binary digits in this number, which is binary representation of 7:
1 1 1
Let's think about numbers. How many binary digits in this number, which is binary representation of 7:
1 1 1
How many binary digits are required to answer this question?
"Did the patient get discharged, alive, by 14 days? (Yes/No)"
"Did the patient get discharged, alive, by 14 days? (Yes/No)"
Thank Frank Harrell for pointing this out on an slide he presented to the FDA and put on line.
Dichotomizing produces simplicity, but at the cost of throwing away lots of stuff, which you might regret.
Dichotomizing produces simplicity, but at the cost of throwing away lots of stuff, which you might regret.
Sorry some people are finding the binary questions above a bit hard.
To store the ANSWER for a "yes/no" question, you only need ONE binary digit in total. You don't need one for Yes and one for No. It is enough to store 1 for Yes, and 0 for No.
To store the ANSWER for a "yes/no" question, you only need ONE binary digit in total. You don't need one for Yes and one for No. It is enough to store 1 for Yes, and 0 for No.
So "one binary digit" is in some senses the smallest amount of information you can get per patient from a trial.
(I know this is not true in the Information Theory sense, with entropy & stuff, and I know @mshunshin and @DrJHoward will beat me up tomorrow, but you get the point.)
(I know this is not true in the Information Theory sense, with entropy & stuff, and I know @mshunshin and @DrJHoward will beat me up tomorrow, but you get the point.)
So generally, Yes/No endpoints tend to need more patients.
The @mshunshin formula for this is as follows.
What is the proportion of bad events (e.g. death-or-still-in-hospital-at-14d)?
Let's say that is 25%, or 1-in-4. We call that a RARITY factor of 4.
The @mshunshin formula for this is as follows.
What is the proportion of bad events (e.g. death-or-still-in-hospital-at-14d)?
Let's say that is 25%, or 1-in-4. We call that a RARITY factor of 4.
How weak is your therapeutic effect? i.e. what fraction of deaths do you prevent?
Suppose you prevent 20% of deaths, or 1-in-5 *of deaths*.
We call that a WEAKNESS factor of 5. (Why "weakness"? Because 100 means you only prevent one death out of 100 deaths).
Suppose you prevent 20% of deaths, or 1-in-5 *of deaths*.
We call that a WEAKNESS factor of 5. (Why "weakness"? Because 100 means you only prevent one death out of 100 deaths).
So for 25% mortality that your reducing to 20%, that is
Rarity 4 (since one in 4 die if untreated) and
Weakness 5 (since 1 in 5 of 25 deaths are prevented, bringing deaths down to 20)
Rarity 4 (since one in 4 die if untreated) and
Weakness 5 (since 1 in 5 of 25 deaths are prevented, bringing deaths down to 20)
What is the number of patients needed, according to that quick formula?
30 * 4^2 * 5
30 * 4^2 * 5
So the sample size of a few hundred would never have answered the question adequately, if we were expecting an effect of the order of "event rates down from 25% to 20%".
So either they were expecting a spectacularly huge effect, like when penicillin was introduced for streptococcal infections.
(Incidentally at my hospital - shout out to St Marys Paddington!
Sorry it looks shabby. Tradition, you know.)
(Incidentally at my hospital - shout out to St Marys Paddington!
Sorry it looks shabby. Tradition, you know.)

Oops thank you David!

A nice round 3000!
That makes me feel a bit better. I knew the formula was a bit rough-and-ready, but I was quietly puzzling why it was so far out, when the official proper formula was giving 2922.
That makes me feel a bit better. I knew the formula was a bit rough-and-ready, but I was quietly puzzling why it was so far out, when the official proper formula was giving 2922.
(90% power, 5% significance, and terms-and-conditions apply. Do not use the @mshunshin formula as your definitive design for a clinical trial. Just use it in your head to protect you from saying stupid things in corridor conversations.)

Yup, two possibilities.
A. Hoping for a ludicrously large effect size.
B. Weren't thinking explicitly about the sample size. Just wanted to start something, and then update once they had more information. So started with a sample size they were sure they could fund.
A. Hoping for a ludicrously large effect size.
B. Weren't thinking explicitly about the sample size. Just wanted to start something, and then update once they had more information. So started with a sample size they were sure they could fund.
Therefore I am not particularly sad that the sample size has increased. It has gone from woefully inadequate (but presumably only a temporary placeholder) to perfectly reasonable.
As for the endpoint, it has moved from a binary thing to a 7-level thing.
This is good, because it means that a patient who is benefitted (but doesn't cross the 14-day discharge threshold) can still contribute useful information about the benefit.
This is good, because it means that a patient who is benefitted (but doesn't cross the 14-day discharge threshold) can still contribute useful information about the benefit.

This looks pretty cunning to me.
At 11 days (this is a non-round number so presumably they looked at a variety of days to pick the most informative day, i.e. where there was the greatest spread of outcomes in patients as a whole, but blinded to allocation arm).
At 11 days (this is a non-round number so presumably they looked at a variety of days to pick the most informative day, i.e. where there was the greatest spread of outcomes in patients as a whole, but blinded to allocation arm).
At 11 days, they will assess patients on a scale of how seriously ill they are:
Dead
Intubated/ECMO
CPAP or high flow O2
Low flow O2
Hosp, needing things other than O2
Hosp, not needing anything
Home
Dead
Intubated/ECMO
CPAP or high flow O2
Low flow O2
Hosp, needing things other than O2
Hosp, not needing anything
Home
Very reasonable.
What do you think my disappointment is?
What do you think my disappointment is?
While we wait for more answers, thank you to Darren Dahly @statsepi for sending me this.

I am a professor, i.e. I love the sound of my own voice, and I pride myself on the Trumpian virtue of always having something to say, however inane.
However I am unable to comment on the quote Darren has sent, because (a) I can't understand what it means.
However I am unable to comment on the quote Darren has sent, because (a) I can't understand what it means.
(b) I disagree that it is critical for all prophylactic trials to have the same endpoint and same DSMB (surely they don't mean the actual same people?)
My reason is that while *I* know what endpoint I want for *my* trial, and I can persuade my colleagues of this in a limited amount of arm-twisting, if I disagree with another scientific team, we have neither the time or scientific data to resolve it scientifically.
Oxygen is critical.
Water is critical.
Having the same endpoint across all Covid trials is not critical. We can make plenty of progress with each trial deciding for itself and pre-specifying.
Water is critical.
Having the same endpoint across all Covid trials is not critical. We can make plenty of progress with each trial deciding for itself and pre-specifying.
Anyway, maybe I misunderstood what the WHO were saying.
And at the end of the day,
(a) they probably contain more than one person and so more than one opinion (otherwise what is the point of having more than one person)
And at the end of the day,
(a) they probably contain more than one person and so more than one opinion (otherwise what is the point of having more than one person)
(b) even if it is just one person, they are entitled to change their mind - after all, we call that process "thinking".
So let me get back to my disappointment regarding the remdesivir trial.
Trials like his are likely to have a blinded endpoint committee.
So let me get back to my disappointment regarding the remdesivir trial.
Trials like his are likely to have a blinded endpoint committee.

This blinded endpoint committee is NOT allowed to see what arm the patient is in.
They review the records of the patient and rate the outcome, without knowledge of the treatment allocation.
Does this make the trial blinded?
They review the records of the patient and rate the outcome, without knowledge of the treatment allocation.
Does this make the trial blinded?
Are the endpoints EVALUATED blinded?
First 3 people are seeing the distinction very clearly.
Sadly, two funding peer reviewers, one of ORBITA and one of ORBITA-2, completely failed to understand this, despite our valiant attempts to explain.
They "killed" it because they said other PCI trials were blinded too!
Sadly, two funding peer reviewers, one of ORBITA and one of ORBITA-2, completely failed to understand this, despite our valiant attempts to explain.
They "killed" it because they said other PCI trials were blinded too!
The endpoints are EVALUATED blinded, i.e. the committee has no knowledge of the treatment arm.
But what are they looking at?
But what are they looking at?
And who decided what treatments the patients needed to be on?
And do those people know which arm the patient is in?
So that is my sadness.
Death is death, but everything else is a measure of what their clinical staff decided to give that patient at that time, in the full knowledge of whether they were taking the drug, and likely the tacit belief that the drug is probably beneficial.
Death is death, but everything else is a measure of what their clinical staff decided to give that patient at that time, in the full knowledge of whether they were taking the drug, and likely the tacit belief that the drug is probably beneficial.
My only suggestion would have been to add a placebo control infusion. I can't see it being very expensive or difficult, since it is not a tablet that has to be manufactured.
Otherwise I think the whole thing is excellent, and I wish them, and the patients, the best of luck!
Otherwise I think the whole thing is excellent, and I wish them, and the patients, the best of luck!
One little postscript.
(I see the anti-capitalism campaigners are in: Smash ECMO! Down with Ventilation! Up the revolution!)
Think why I would not push for a much longer timepoint than 11d, for this 7-level endpoint.
(I see the anti-capitalism campaigners are in: Smash ECMO! Down with Ventilation! Up the revolution!)
Think why I would not push for a much longer timepoint than 11d, for this 7-level endpoint.
Do a thought experiment. At 90 days, let's say (just a made-up number) 20% of people are dead.
What will the status of the other 80% be, along the spectrum of 6 remaining states?
What will the status of the other 80% be, along the spectrum of 6 remaining states?
If you have difficulty answering, think about the answer at 365 days.
With that 365-day timepoint picture in mind, what is the benefit of choosing the 7-level endpoint to evaluate that outcome, rather than a dichotomous outcome?
With that 365-day timepoint picture in mind, what is the benefit of choosing the 7-level endpoint to evaluate that outcome, rather than a dichotomous outcome?
OMG 100% of the first 6 people are wrong on this question:

Let me put it in words of one syllable.
1000 peeps go in da hosp
At 3 months (MONTHS) [M O N T H S],
200 are dead.
Dat meens 800 still live
Where are dose 800 peeps? (At 3 months, or wun year?)
1000 peeps go in da hosp
At 3 months (MONTHS) [M O N T H S],
200 are dead.
Dat meens 800 still live
Where are dose 800 peeps? (At 3 months, or wun year?)
And of those 800 who have gone home, how many are on ECMO & shit?
OK so at a very long time point, like 3 months or one year or whatever, EVERYONE who hasn't died has recovered and is at home.
So the 7-level fanciness turns to crap.
It has a bunch of people (say 20%) in the worst tier, "dead".
And all of the rest in the best, "home".
So the 7-level fanciness turns to crap.
It has a bunch of people (say 20%) in the worst tier, "dead".
And all of the rest in the best, "home".
So we have shot the 7-level endpoint in the head.
What we should have done is picked the timepoint when people were spread out across the levels of the endpoint.
Right in the middle of the bad times.
11 days sounds good to me!
What we should have done is picked the timepoint when people were spread out across the levels of the endpoint.
Right in the middle of the bad times.
11 days sounds good to me!
A brief math interlude and then another postscript.
I love today's puzzle from Mathirati.
Simple to ask
Impossible (for me) to do in one's head: had to type two lines of notes
And answer is hard to believe from picture
I love today's puzzle from Mathirati.
Simple to ask
Impossible (for me) to do in one's head: had to type two lines of notes
And answer is hard to believe from picture

Let's take the radius of the circles as one unit.
Look at this line, the side of the small octagon.
Look at this line, the side of the small octagon.
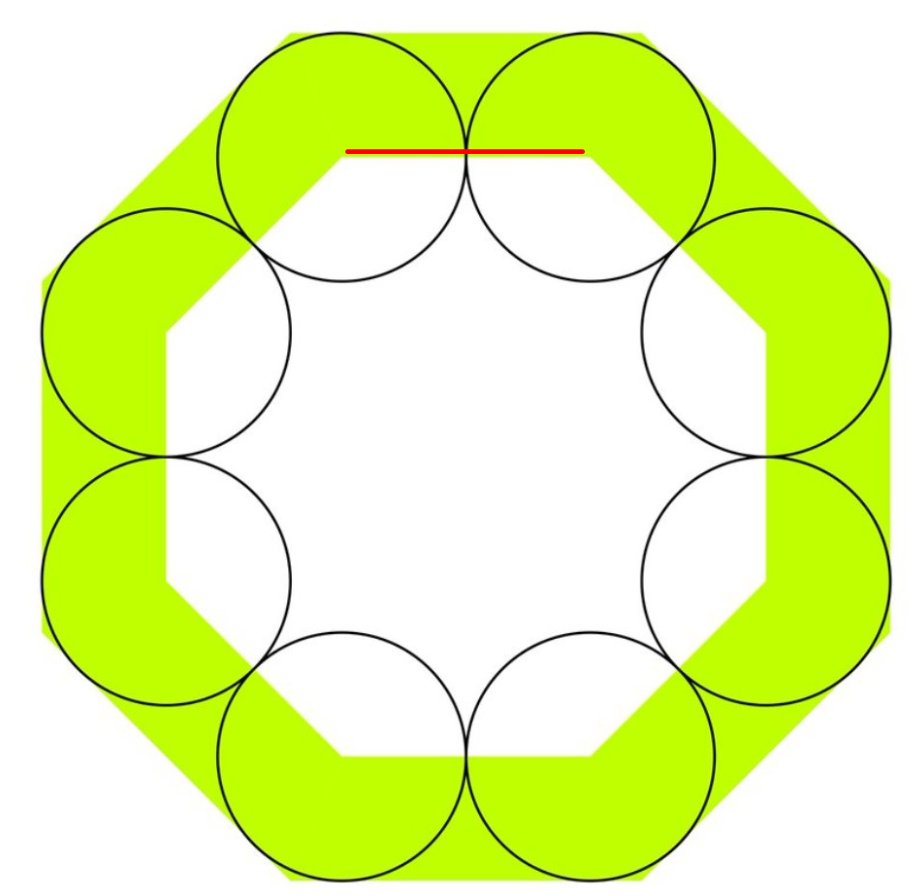
How long is it?
Now look at the blue line
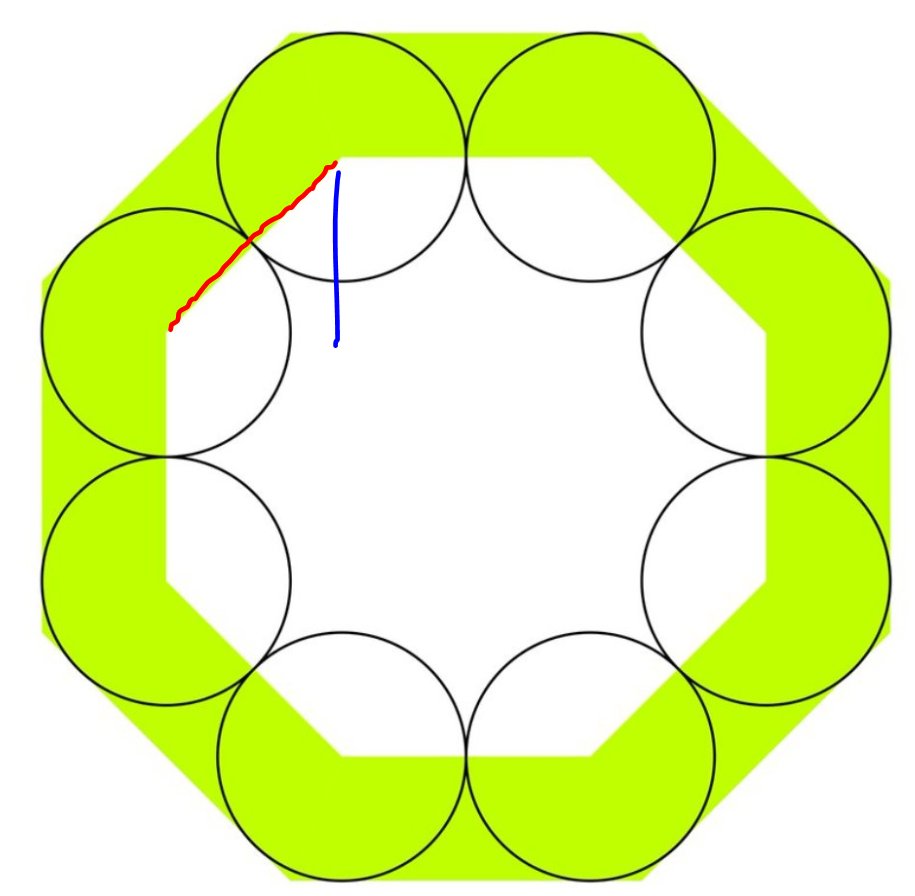
How long is the blue line?
Remember that thing is a 45 degree triangle.
In a 45 degree triangle the short sides are Square-root-of-2 times smaller than the long side.
And you know the long side is two units: you just told me.
A short side (blue) is:
Remember that thing is a 45 degree triangle.
In a 45 degree triangle the short sides are Square-root-of-2 times smaller than the long side.
And you know the long side is two units: you just told me.
A short side (blue) is:
Look at this black line, which takes us down to the centre of the octagons.
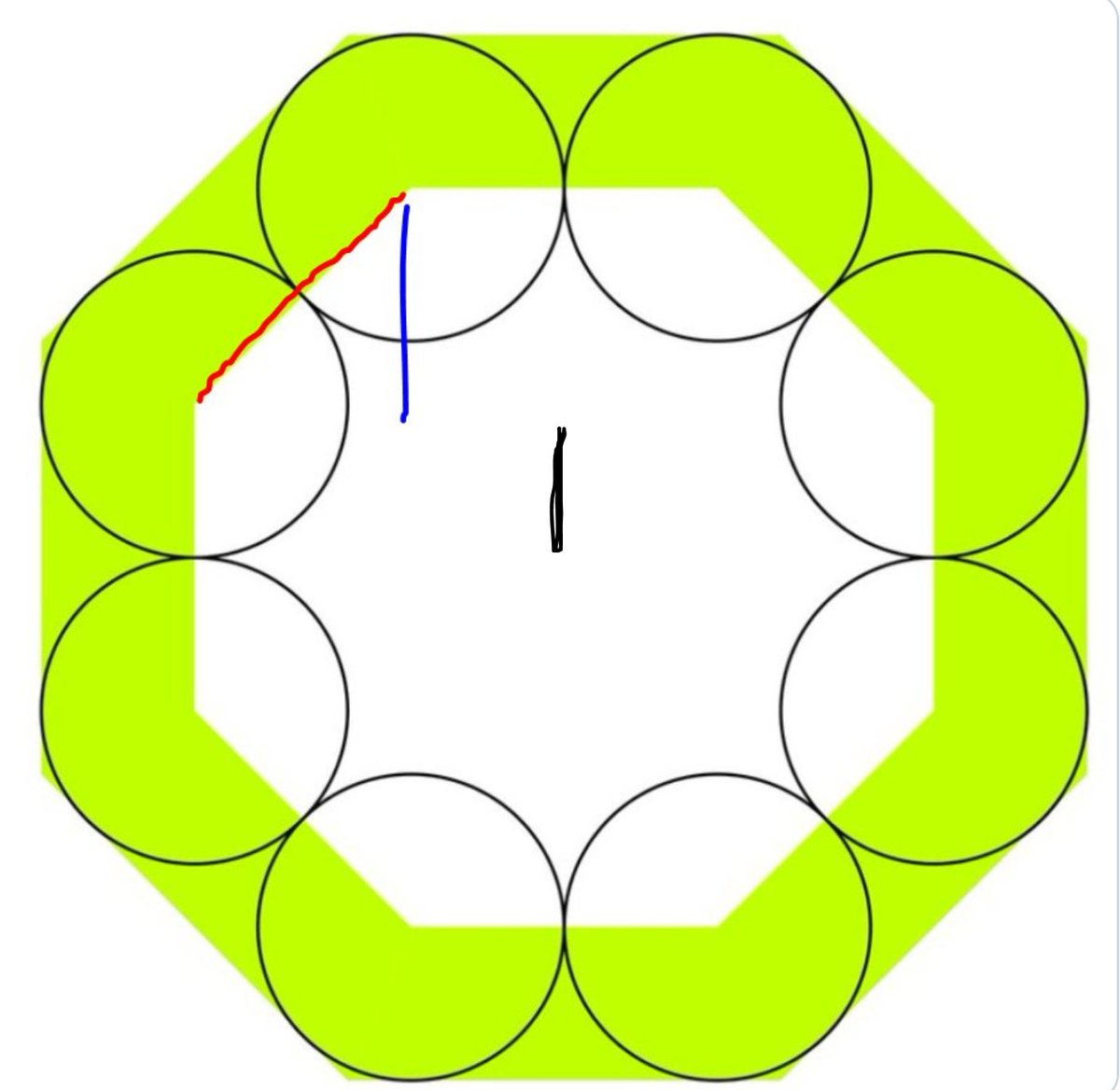
How long is the black line
So the total from the top of the inner octagon to the centre of the octagons is what?
Add the blue and the black heights.
Add the blue and the black heights.
Now, from that midpoint, how many units further up is the top of the big octagon?
So the ratio of the HEIGHTS of the small to the big octagon is what?
(I am using "s" to mean square root of 2)
(I am using "s" to mean square root of 2)
All that you could, and have, done in your head.
Now square that ratio. This will give you the fraction UNSHADED.
(1 + s) squared is what? You can use paper if you want
Now square that ratio. This will give you the fraction UNSHADED.
(1 + s) squared is what? You can use paper if you want
And (2 + s) squared, with the help of some paper, you can similarly work out to be
2*2 + 2*2*s + s*s
which is 4 + 4s + 2
or 6 + 4s
2*2 + 2*2*s + s*s
which is 4 + 4s + 2
or 6 + 4s
Which is the good news, because hopefully you saw that (1+s)^2 was 1 + 2s + s*s = 1 + 2s + 2
= 3 + 2s
So now you know the proportion UNSHADED, which is
3 + 2s
divided by
6 + 4s
i.e.
= 3 + 2s
So now you know the proportion UNSHADED, which is
3 + 2s
divided by
6 + 4s
i.e.
Doesn't look it, does it?
That's why we do numbers, rather than just bullshitting.
That's why we do numbers, rather than just bullshitting.

If your thread ends here, click here to continue:
Speaking of numbers, remember my hesitancy over the remdesivir trials is that they are unblinded (in the sense that unblinded staff make the decisions which are the main measured outcomes of the trial)?
POSTSCRIPT 2
POSTSCRIPT 2
We are measuring something that is a decision of an unblinded colleague.
If that causes false-positive bias, then what happens to the p value when you make the trial bigger?
If that causes false-positive bias, then what happens to the p value when you make the trial bigger?
Bigging up the size of a trial does not solve the problem of the unblinding.
Instead, it makes the problem worse.
8-(
Instead, it makes the problem worse.
8-(
Oh, first couple of people didn't see this as obvious.
The p-value is telling you how easily such an extreme result could happen through simply the play of CHANCE.
The p-value is telling you how easily such an extreme result could happen through simply the play of CHANCE.
If it is very small, i.e. "This sort of thing would only happen by chance about once for every 20 trials of ineffective medication" (i.e. p<0.05),
then it is not saying whether the reduction of events is due to the DRUG or due to BIAS.
then it is not saying whether the reduction of events is due to the DRUG or due to BIAS.
Indeed, when a family of therapies simply do not work, then the p values of the trials become very useful.
p-values show how biased (or fraudulent) the researchers are!
And they've signed it and published it!
Amazing.
Anyway that's another story. bmj.com/content/bmj/34…
p-values show how biased (or fraudulent) the researchers are!
And they've signed it and published it!
Amazing.
Anyway that's another story. bmj.com/content/bmj/34…
Good query here from Amer Ardati @spiritus_bah

Yes, the FIELD could contain
answer Yes
answer No
unanswerd
answer Yes
answer No
unanswerd
Which is why I was careful to say "How many bits do you need to store the ANSWER".
If you need to store the unanswered state as well, there are more bits needed.
However there are two bigger problems with my analogy to bits.
However there are two bigger problems with my analogy to bits.
Problem 1.
When you count deaths, as well as NUMBER (or proportion) of deaths, you also have DATE of death.
So everyone could be dead in 100 years, but if one arm lived many years longer, that is the better arm.
When you count deaths, as well as NUMBER (or proportion) of deaths, you also have DATE of death.
So everyone could be dead in 100 years, but if one arm lived many years longer, that is the better arm.
My defence here is that in clinical trials.gov they wrote that it was the proportion that was the original primary endpoint, so not the date, but how many home at a fixed time point.
So my analogy is reasonable.
So my analogy is reasonable.
Problem 2.
Although we NEED one bit of computer memory to store the answer (as long as it is Yes/No),
we are not really getting one bit of INFORMATION content.
Although we NEED one bit of computer memory to store the answer (as long as it is Yes/No),
we are not really getting one bit of INFORMATION content.
For example, suppose I make a Gregg Stone detector. You point it at people, and it tells you whether they are the Greggster or not.

You point it at him, it says "Yes" and then you point it at a dozen other people and it says "No".
That is a certain amount of information.
That is a certain amount of information.
Now imagine you go to the next room and point it at another 13 different people, and it correctly says "No", do you have twice as much information about it?
You might say yes. (My analogy was based on this being the case)
You might say yes. (My analogy was based on this being the case)
But actually that second room is not as informative, because there isn't a Gregg Stone there. For all we know, it just says "Yes" the first time and then "No" forever after.
Or "Yes" one in 20 times or so, at random.
So we go back and re-scan Gregg (the Original and Best), from a different direction.
It says "Yes" again.
Now that is impressive.
It says "Yes" again.
Now that is impressive.
That extra "Yes" was worth more than a whole load of extra "No"s.
Because that can't be just because the thing is generally saying "No" a lot. It has got it right in two rare cases of Gregg Stone-ness.
Because that can't be just because the thing is generally saying "No" a lot. It has got it right in two rare cases of Gregg Stone-ness.
Now according to @DrJHoward and @mshunshin who are our local Deep Learning Geeks and Cardiologists, this is something to do with Shannon's Information concept, of which I have some vague familiarity.
They have to know this stuff to train t neural networks and things.
They have to know this stuff to train t neural networks and things.
Anyway, to cut a long story short:
"Getting one more correct answer is far more meaningful if it is a rare YES than a common NO".
"Getting one more correct answer is far more meaningful if it is a rare YES than a common NO".
Anyway they do something with logarithms and stuff, and the end result is that:
"If the YESes and NOs are roughly equal in number, each extra case is worth one binary digit of information.
If not, it is worth less than one bit."
"If the YESes and NOs are roughly equal in number, each extra case is worth one binary digit of information.
If not, it is worth less than one bit."
Now don't push me here, because I don't know what I am talking about.
However I am in good company. Yesterday I was in a thread with David Brown and somebody called "YO".

And while he was busy leveraging etc, out comes this news.



The NYTimes article link I can only see some of, but there is enough to show the reporter (thankfully I can't see their name) has not done a particularly careful job.

It hasn't been peer reviewed.
That should matter to the general public.
But it has NO RELEVANCE to the readers of this thread, who are scientists and doctors. All peer review means is somebody like you and me had a look and said "OK go on then."
That should matter to the general public.
But it has NO RELEVANCE to the readers of this thread, who are scientists and doctors. All peer review means is somebody like you and me had a look and said "OK go on then."
The corresponding author is Zhan Zhang (doctorzhang2003@163.com) if anyone knows if they are on Twitter.


Your view after reading the abstract?
8-)

Have a look here.

Is it registered on ClinicalTrials.gov?
Now have a look at the primary endpoint

What is the primary endpoint?
Look at the randomization methods

They were randomized stratified by what?
The questions you have answered are
OK Now the answers.
Question 1. ClinicalTrials.Gov
First respondent said "yes". I understand why, because the authors said this, and you are trusting lot.
Question 1. ClinicalTrials.Gov
First respondent said "yes". I understand why, because the authors said this, and you are trusting lot.

I'm not.
Here is what Mr Clinical Trials Dot Org has to say on the subject.
Here is what Mr Clinical Trials Dot Org has to say on the subject.

So since that "ChiCTR" sounds like an ID for Chinese Clinical Trials Registry, from 2000, and number 29559 at that, let's look there, shall we?
chictr.org.cn/showprojen.asp…
chictr.org.cn/showprojen.asp…
Oh hello hello.
Mysteriously not working
Mysteriously not working

Not to worry, here is a screenshot I accidentally took earlier today.

Good stuff

If your thread stops here, click this.
Some of you will already have seen an oddity, yes?
Date of ethics approval and date of study start. Anyway, maybe that's the date they started lining up their test tubes etc, and not the date open for randomization, like we would write in the West.
Date of ethics approval and date of study start. Anyway, maybe that's the date they started lining up their test tubes etc, and not the date open for randomization, like we would write in the West.
And here is more.

So the ClinicalTrials.Gov registration, turned out to be
And the Primary Endpoint, which you reasoned from the paper was some mishmash of various incomprehensible things like the half-self-absorbing lungs etc...

Was actually this, or rather I should say "these".

I have no idea what "T cell recovery time" is. But what did the paper say the result of that was?
And what about the one that I can imagine what it is, namely "The time when the nucleic acid of the novel coronavirus turns negative"
What did the drug to that, in the trial report?
Need a hint? Here are the Results
What did the drug to that, in the trial report?
Need a hint? Here are the Results

and the entirety of the rest of the results.

And, pray, what was the effect of the drug on the time to elimination of Viral nucleic acid?
Now the Randomization.
Remember how you said that they made a special point that randomization was stratified by site?
How many sites were there?
Remember how you said that they made a special point that randomization was stratified by site?
How many sites were there?

They said it was randomized stratified by site, which means they had several sites.
Did it?
Did it?
Still giving them the benefit of the doubt? You are Mother Theresa and Jesus Christ all rolled into one.
Here is the killer question.
How many arms did the trial have?
Here is the killer question.
How many arms did the trial have?
Now have a look at this

Now how many arms did the trial have?
OK
* Said it was on ClinTrials.Gov, but wasn't
* Published that it had 3 arms, but only reported on two
* Specifically said to be stratified only by site, but has only one site
* One primary endpoint incomprehensible
* BOTH PRIMARY ENDPOINTS DISAPPEARED
* Said it was on ClinTrials.Gov, but wasn't
* Published that it had 3 arms, but only reported on two
* Specifically said to be stratified only by site, but has only one site
* One primary endpoint incomprehensible
* BOTH PRIMARY ENDPOINTS DISAPPEARED
The disappearance of one arm and both primary endpoints is actually extremely helpful.
It means the people that wrote this cannot be trusted, EVEN ON THINGS THAT YOU CAN EASILY CHECK AND SEE THAT THEY ARE LYING.
It means the people that wrote this cannot be trusted, EVEN ON THINGS THAT YOU CAN EASILY CHECK AND SEE THAT THEY ARE LYING.
So why should you have any faith in the things you can't check?
Discuss.
(without mention of Donald Trump saying it's really good stuff)
Discuss.
(without mention of Donald Trump saying it's really good stuff)
Oh Touché!

The situations are different in the following way.
If you say your name is Dr Pranev Sharma and you have a name badge saying the same, and a stethescope etc, and then you ask to take my pulse, I will not raise any query.
If you say your name is Dr Pranev Sharma and you have a name badge saying the same, and a stethescope etc, and then you ask to take my pulse, I will not raise any query.
If you are dressed as a clown, carry a trombone in one arm, and announce you are Napoleon, despite having a name-badge saying "Ms Praneva Sharma" and the photo of someone else, then I would be hesitant.
The paper is in the latter group.
I do not give it the benefit of the doubt.
The paper is in the latter group.
I do not give it the benefit of the doubt.
One more thing. Why do I care about the number of sites, and make a big issue of it?
Because it was intended to have 300 patients.
The paper mentioned randomization "stratified by site".
But it only gave the results of one site, with 62 patients.
Because it was intended to have 300 patients.
The paper mentioned randomization "stratified by site".
But it only gave the results of one site, with 62 patients.
One possibility is that it was harmful on the primary endpoint across all the sites; another is that it was harmful at the other sites; finally it could have been harmful in the unmentioned trial arm.
So if you have (say) 300/62 ~ 5 sites, and 2 ACTIVE arms, and fifty endpoints to try out, then how many ways can you slice your full dataset to make a single-site subtrial with 1 active arm and one(-ish!) primary endpoint?
And on average, how many of these slicings of a single 300-pt, 3-arm trial (as described on the Chinese Clinical Trial Registration site) would produce a statistically significant results at p<0.05?
And what is the chance, that if you have that number of slicings available, and the drug is ineffective, that you will find one or ore slicings that is statistically significant (p<0.05)?
Yes I know that is cheeky because they are not statistically independent, but let's face it, you are almost certain to strike gold unless you are very very unlucky.
It is not the Poisson for zero successes in 500, when the mean is 25, but it is in that league. Well past 0.99.
It is not the Poisson for zero successes in 500, when the mean is 25, but it is in that league. Well past 0.99.
That is why I give less than zero credence to the suggestion from this paper that the drug is beneficial.
Who actually said that the trial was good?
We can now discount all future proclamations from them because they
EITHER
Did not notice these crazy self-destruct features in the trial
(i.e. are stupid)
OR
Did not look for them
(i.e. are incompetent)
Can anyone provide links?
We can now discount all future proclamations from them because they
EITHER
Did not notice these crazy self-destruct features in the trial
(i.e. are stupid)
OR
Did not look for them
(i.e. are incompetent)
Can anyone provide links?





