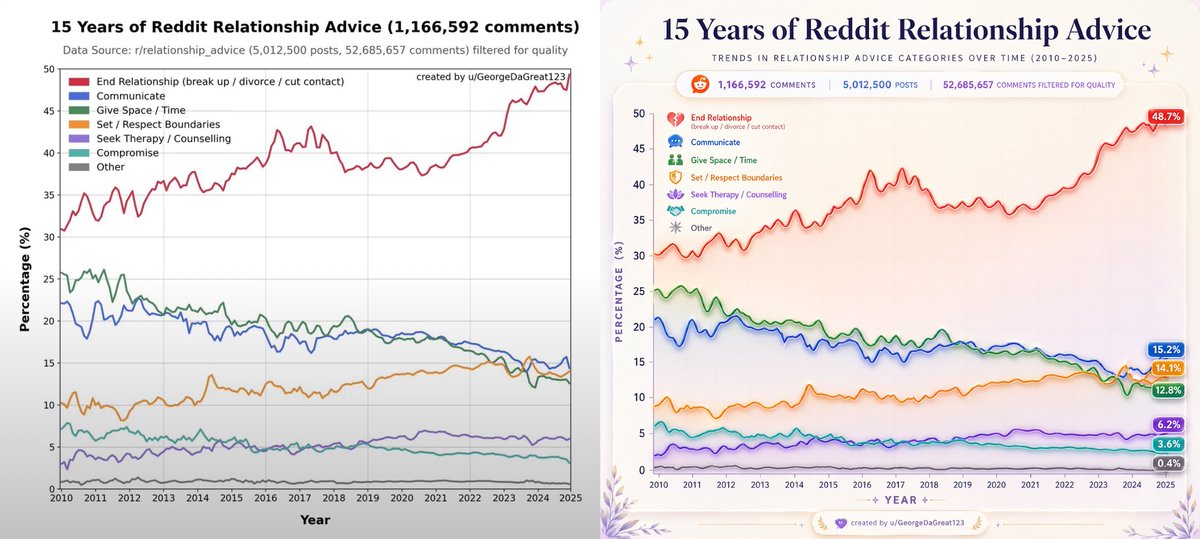
1/ This is the Strava heatmap of running around the world. It's truly fascinating, and gets to the core of how certain places, particularly European cities, are designed for outdoor activity while others aren't. Let's look more closely 
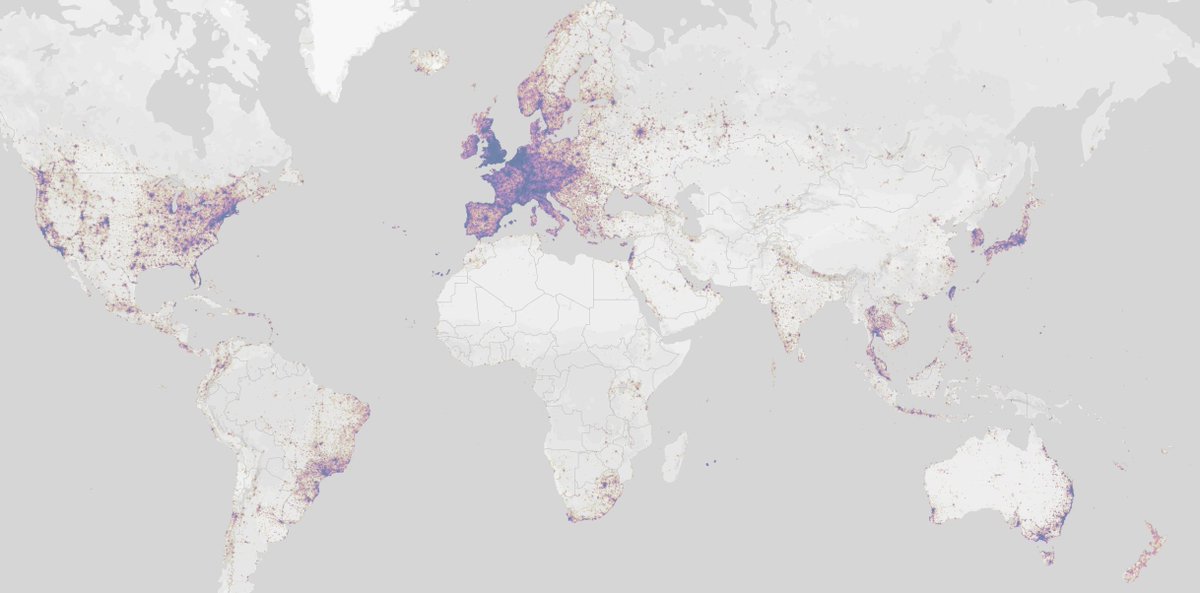
2/ Let's look at the Bay Area and New York City to get a glimpse of US cities. The Bay, despite being sprawled out, has running routes connecting the entire peninsula down to South Bay.
NYC is denser, but people run everywhere - park, coast, bridges, even in the middle of town.
NYC is denser, but people run everywhere - park, coast, bridges, even in the middle of town.


3/ Cities in Europe - Paris, Barcelona and London, for example - follow similar patterns - several core runnable boulevards with many tributaries that encompass the entire landscape.



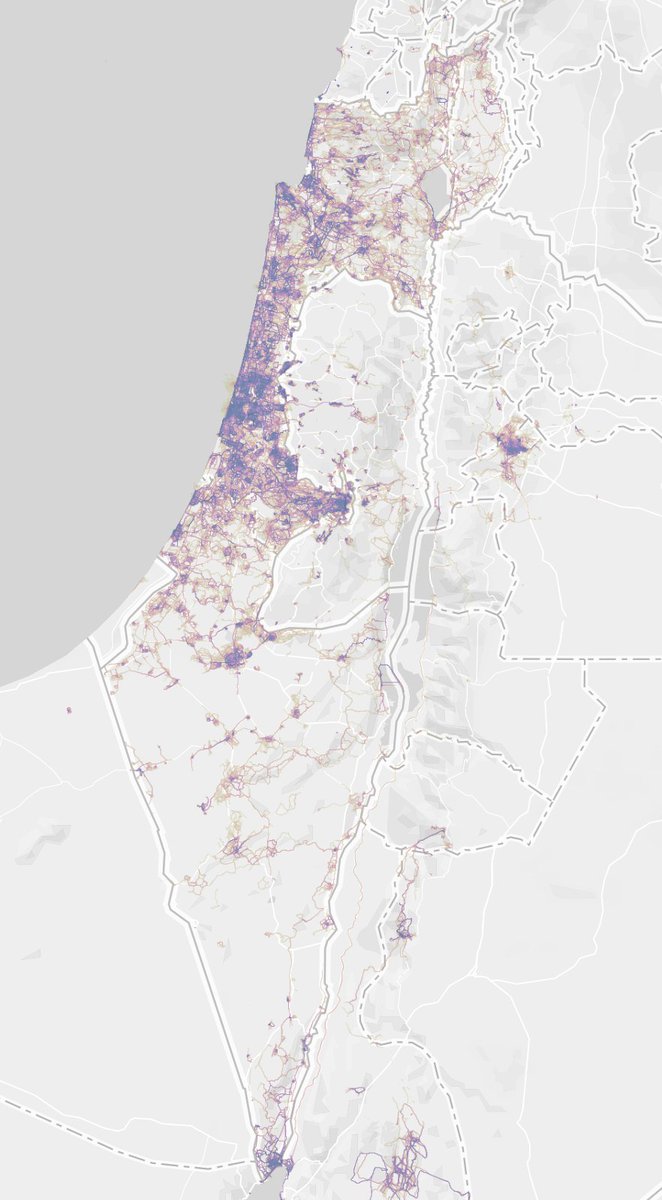
4/ "European" cities outside Europe, like Tel Aviv and Istanbul are Tel Aviv are similar. Beautiful coastal runs with smaller lanes branching out into the city. Gorgeous, well planned places.


5/ Israel, in my experience, is a place known for being well spread out and not having clusters of big cities. The data backs this up, and Israel is one of the only countries I found which seem entirely runnable, not just in pockets.
6/ This gets me to my core point. I've always been annoyed by Indian cities because, regrettably, they're made up of pockets of activity and un-runnable roads - like ill-fitting puzzle pieces.
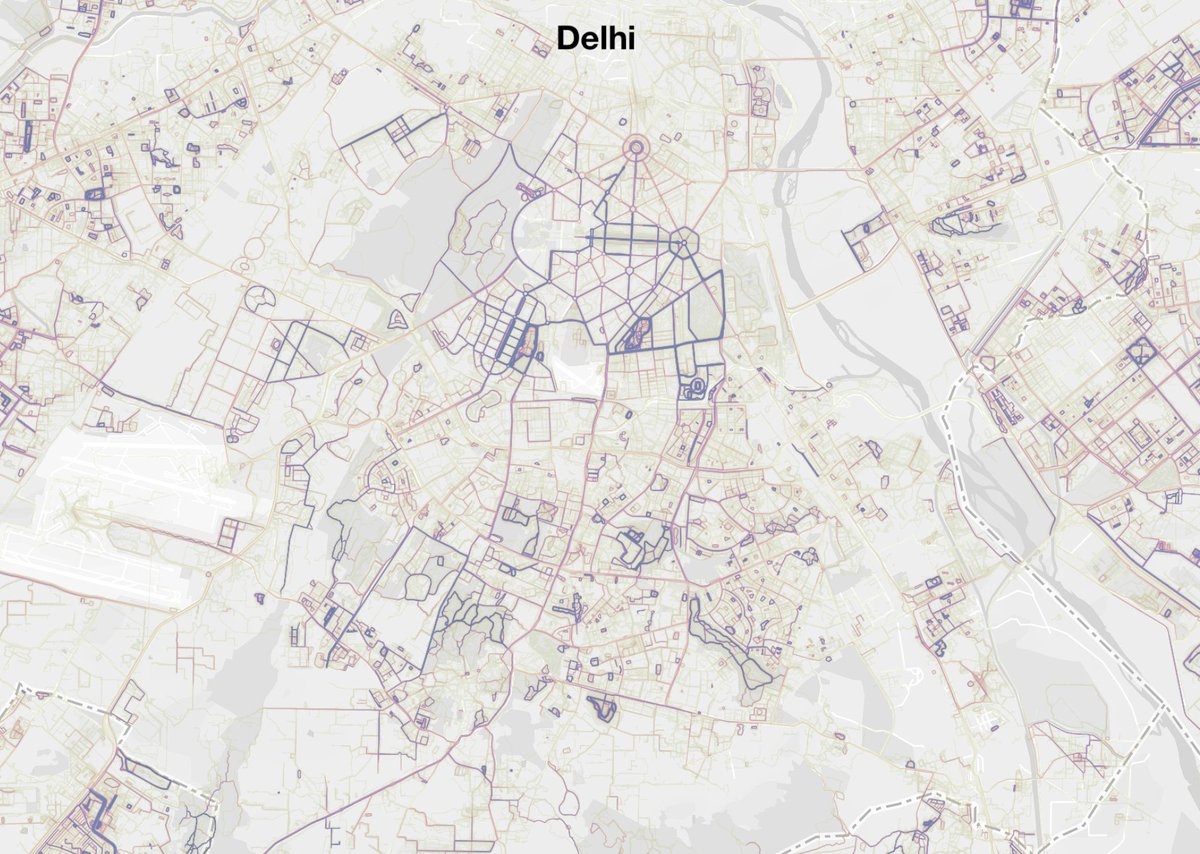

7/ We see little islands of planned / closed neighborhoods or lakes that are far removed from each other. The spines of the city aren't pedestrian-friendly at all.
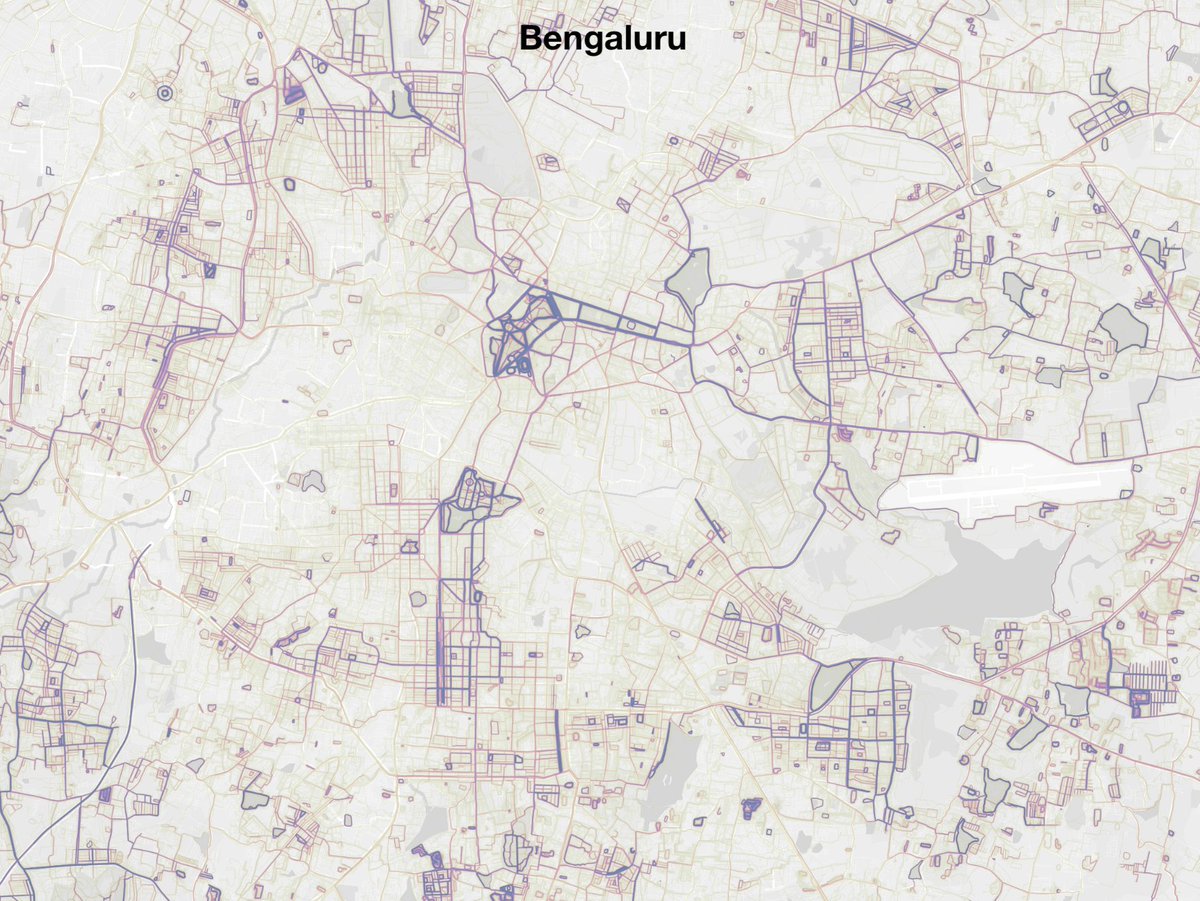

8/ If you think density is to blame, that's not true. Dense Asian cities can be very well connected. Take a look at Tokyo, Shanghai or Singapore for example. Even in comparison to their European counterparts, there's less prominent spines and just a web of interconnected roads.



9/ Even though Strava data is biased towards countries with more smartphones, the story it paints, empirically, rings true. I wish more Indian cities strived to be more runnable.
My favorite city though was this one: with one singular long continuous run by the river. Guess?
My favorite city though was this one: with one singular long continuous run by the river. Guess?

• • •
Missing some Tweet in this thread? You can try to
force a refresh