"Comparative Analysis of COVID-19". Stanford group of 5 is well-supported by @StanfordMed & @NIH. Three helped part-time: Andrea Scaiewicz @andreascaie, Frédéric Poitevin @fredericpoitev1 , João Rodrigues @jpglmrodrigues . Also Francesco Zonta @Cescoxonta (at @ShanghaiTechUni 

The app was written in Python by Andrea Scaiewicz advised by João Rodrigues. It is research software allowing comparison of all locations with >50 deaths or >3000 cases (see examples). Response is slow as freely hosted by heroku @heroku. Tested too little, it is likely buggy.




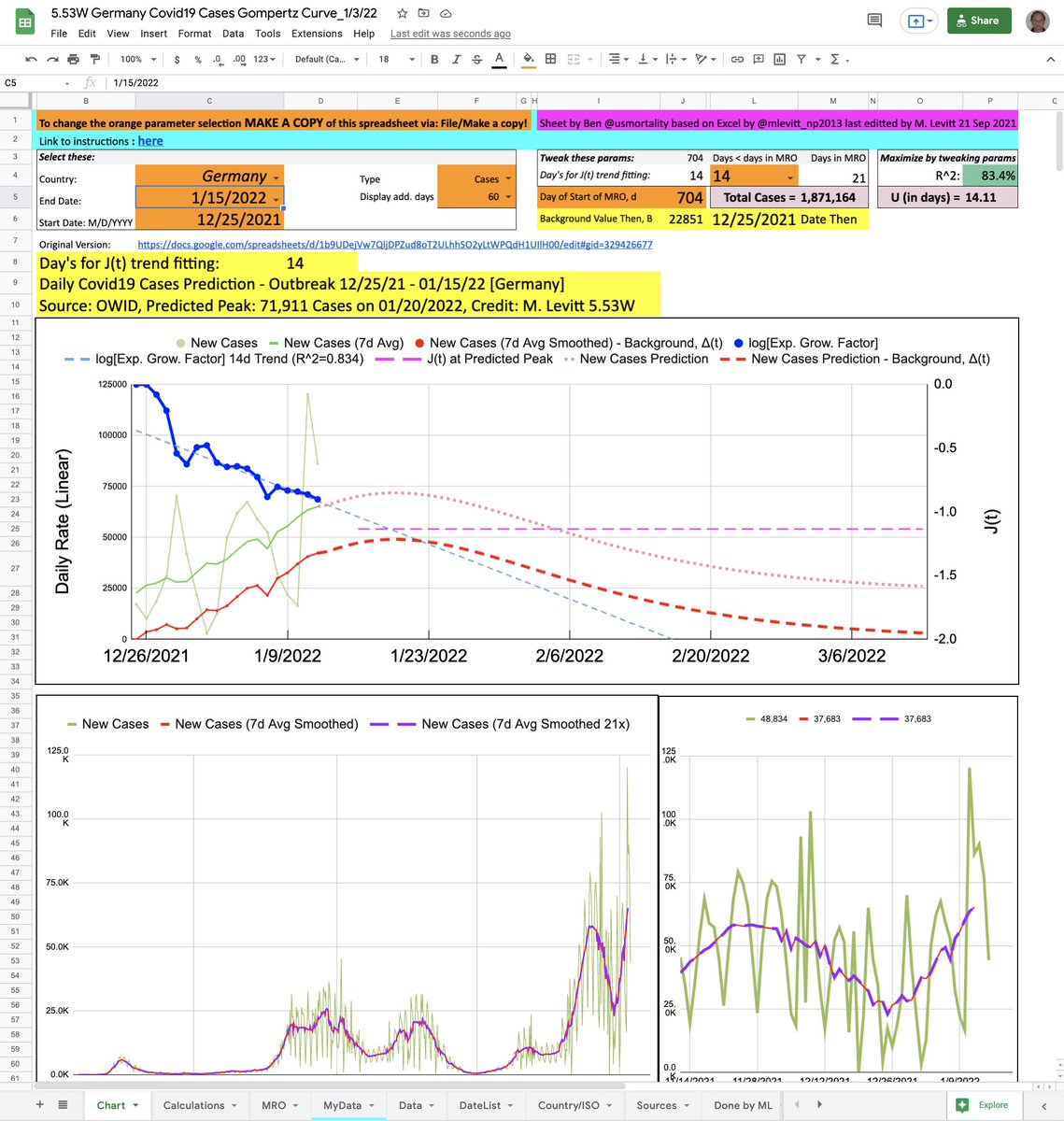
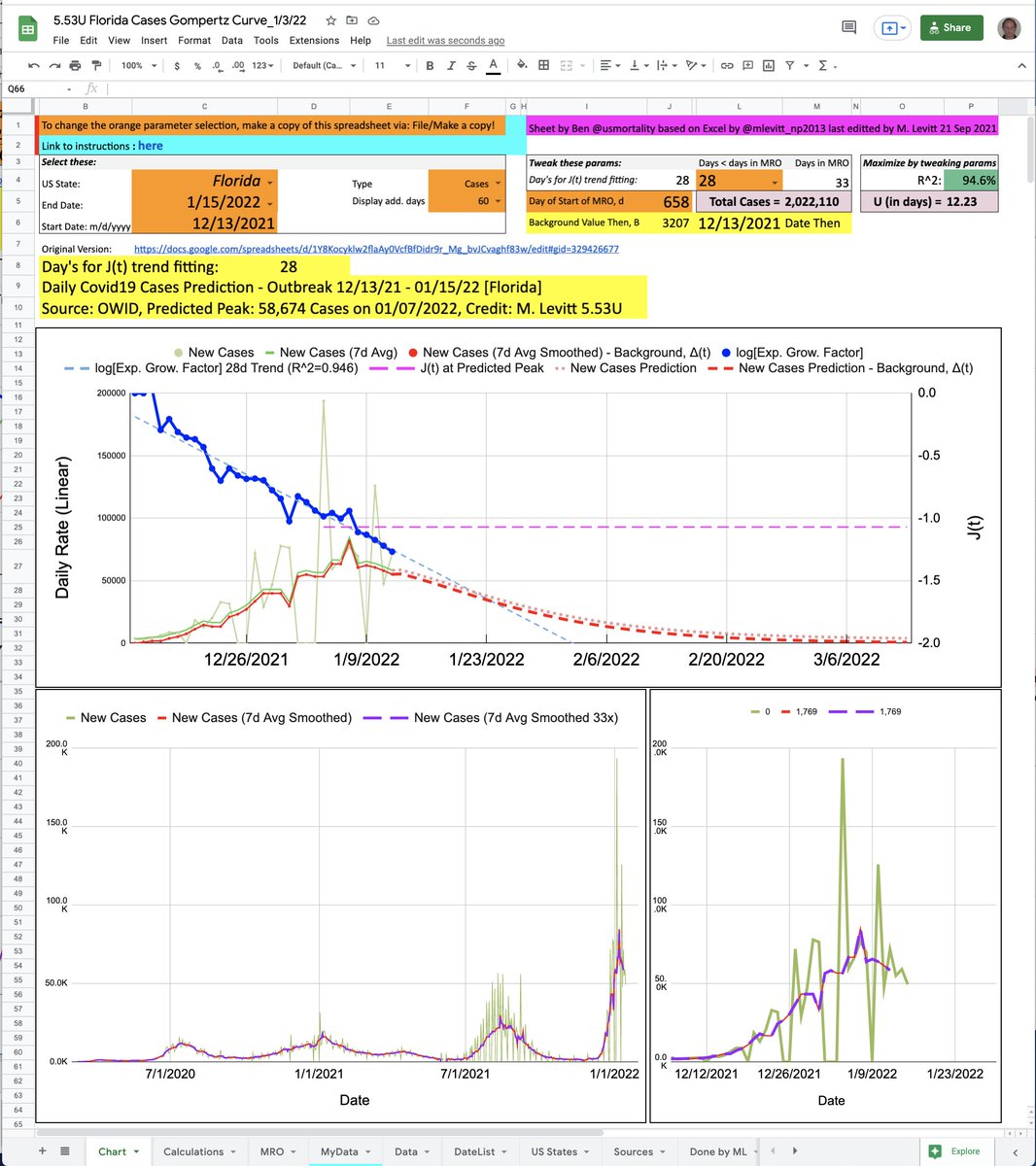
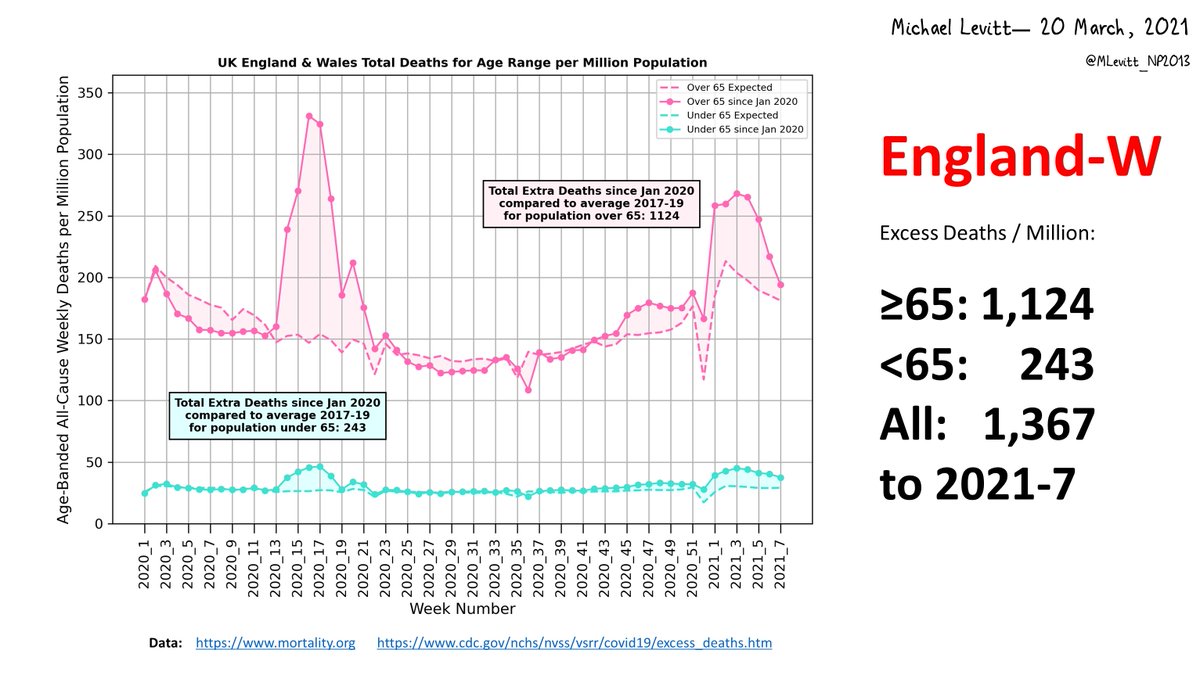
The table of locations is classified by Class score. Columns can be sorted or filtered by a string (eg. "====" with quotation selects worst locations). UNSM is raw data, SMO3 is moderate smoothing & SMO5 is more extreme smoothing.
Enjoy at levitt1.herokuapp.com and feed back to me. I intend to pay for better hosting as needed. Also please suggest alternative places we can host this.
• • •
Missing some Tweet in this thread? You can try to
force a refresh